By: Greg Robidoux | Updated: 2008-12-09 | Comments (5) | Related: 1 | 2 | 3 | > Indexing
Problem
When creating tables it is difficult to determine exactly how the data will be accessed. Therefore when clustered indexes are chosen they are often just the ID column that makes the row unique. This may be a good choice, but once the application has been used and data access statistics are available you may need to go back and make some adjustments to your tables to ensure your clustered indexes are providing a benefit and not a drain on your applications. This tip shows a simple approach on how to determine a better candidate for your clustered indexes.
Solution
To illustrate this we are going to use a table from the AdventureWorks database and query this table. The table that I am using is Person.Address, the screen shot below shows the current structure for this table. We can see there are four indexes on this table.
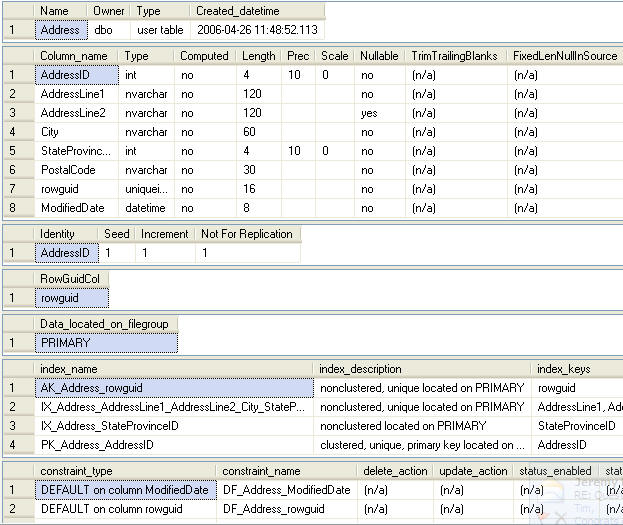
To collect some index usage stats, I ran the following query five times in the AdventureWorks database .
SELECT AddressLine1, AddressLine2
FROM Person.Address
WHERE StateProvinceID = 1 If we look at the execution plan we can see that this query is doing an Index Seek on index IX_Address_StateProvinceID and then doing a Key Lookup on the clustered index PK_Address_AddressID.

- The Index Seek scans a nonclustered index looking for records that match the value provided.
- The Key Lookup is used to lookup the actual data from the clustered index.
To see how these indexes are actually being used we can run the following query.
SELECT OBJECT_NAME(S.[OBJECT_ID]) AS [OBJECT NAME],
I.[NAME] AS [INDEX NAME],
USER_SEEKS,
USER_SCANS,
USER_LOOKUPS,
USER_UPDATES
FROM sys.dm_db_index_usage_stats AS S
INNER JOIN sys.indexes AS I
ON I.[OBJECT_ID] = S.[OBJECT_ID]
AND I.INDEX_ID = S.INDEX_ID
WHERE OBJECT_NAME(S.[OBJECT_ID]) = 'Address' Since I restarted SQL Server before I ran these tests, my numbers should match the five query executions that I ran. We can see here that SQL Server did a USER_SEEK five times on index IX_Address_StateProvinceID (nonclustered index) and also did a USER_LOOKUP five times for index PK_Address_AddressID (clustered index). This corresponds with the execution plan above where we first did an Index Seek and then we did a Key Lookup to retrieve the additional data.

If this was a real representation of how users are accessing our database we can conclude that index IX_Address_StateProvinceID would be a better clustered index since we are always seeking on this column and therefore we can eliminate the Key Lookup which was 96% of our execution plan.
Now that we know we want to use StateProvinceID as our clustered index there are a few steps we need to do. We need to remove the existing Primary Key (PK) / Clustered Index, but since this table is also referenced by Foreign Keys (FK) we need to drop them as well. The following queries show how to drop the FKs, the PK and create the new Clustered Index. In a real world situation you would want to recreate the PK and also script out the creates for these FKs, so after you make the changes you could recreate them.
ALTER TABLE [HumanResources].[EmployeeAddress] DROP CONSTRAINT [FK_EmployeeAddress_Address_AddressID]
ALTER TABLE [Sales].[CustomerAddress] DROP CONSTRAINT [FK_CustomerAddress_Address_AddressID]
ALTER TABLE [Purchasing].[VendorAddress] DROP CONSTRAINT [FK_VendorAddress_Address_AddressID]
ALTER TABLE [Sales].[SalesOrderHeader] DROP CONSTRAINT [FK_SalesOrderHeader_Address_ShipToAddressID]
ALTER TABLE [Sales].[SalesOrderHeader] DROP CONSTRAINT [FK_SalesOrderHeader_Address_BillToAddressID]
ALTER TABLE Person.Address DROP CONSTRAINT PK_Address_AddressID
CREATE CLUSTERED INDEX IX_StateProvinceID ON Person.Address(StateProvinceID) Now that we have our new clustered index created we can re-query the table and see what our new execution plan looks like.
SELECT AddressLine1, AddressLine2
FROM Person.Address
WHERE StateProvinceID = 1 The below shows that we now have a Clustered Index Seek and no more Key Lookup.
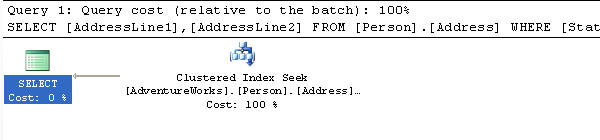
If we query the index usage stats we can see the difference here as well. We now have only USER_SEEKS and no more USER_LOOKUPS. One thing to note is that when you alter indexes on a table these stats get reset to zero. So this change seems to be a success for our table.

Next Steps
- Hopefully this gives you some insight on how to determine if you have the correct clustered index. If you see your clustered indexes with only USER_LOOKUPS and you have a nonclustered index that has almost the same number of seeks this is probably a good candidate for the swap.
- Take a look at these other tips to get a better insight into your SQL Server indexes.






About the author
 Greg Robidoux is the President and founder of Edgewood Solutions, a technology services company delivering services and solutions for Microsoft SQL Server. He is also one of the co-founders of MSSQLTips.com. Greg has been working with SQL Server since 1999, has authored numerous database-related articles, and delivered several presentations related to SQL Server. Before SQL Server, he worked on many data platforms such as DB2, Oracle, Sybase, and Informix.
Greg Robidoux is the President and founder of Edgewood Solutions, a technology services company delivering services and solutions for Microsoft SQL Server. He is also one of the co-founders of MSSQLTips.com. Greg has been working with SQL Server since 1999, has authored numerous database-related articles, and delivered several presentations related to SQL Server. Before SQL Server, he worked on many data platforms such as DB2, Oracle, Sybase, and Informix.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2008-12-09
