By: Arshad Ali | Updated: 2009-03-16 | Comments (21) | Related: 1 | 2 | 3 | 4 | 5 | > Fragmentation and Index Maintenance
Problem
While indexes can speed up execution of queries several fold as they can make the querying process faster, there is overhead associated with them. They consume additional disk space and require additional time to update themselves whenever data is updated, deleted or appended in a table. Also when you perform any data modification operations (INSERT, UPDATE, or DELETE statements) index fragmentation may occur and the information in the index can get scattered in the database. Fragmented index data can cause SQL Server to perform unnecessary data reads and switching across different pages, so query performance against a heavily fragmented table can be very poor. In this article I am going to write about fragmentation and different queries to determine the level of fragmentation.
Solution
When indexes are first built, little or no fragmentation should exist. Over time, as data is inserted, updated, and deleted, fragmentation levels on the underlying indexes may begin to rise. So let's see how it happens.
When a page of data fills to 100 percent and more data must be added to it, a page split occurs. To make room for the new incoming data, SQL Server moves half of the data from the full page to a new page. The new page that is created is created after all the pages in the database. Therefore, instead of going right from one page to the next when looking for data, SQL Server has to go from one page to another page somewhere else in the database looking for the next page it needs. This is called index fragmentation.
There are basically two types of fragmentation:
- External fragmentation - External, a.k.a logical, fragmentation occurs when an index leaf page is not in logical order, in other words it occurs when the logical ordering of the index does not match the physical ordering of the index. This causes SQL Server to perform extra work to return ordered results. For the most part, external fragmentation isn't too big of a deal for specific searches that return very few records or queries that return result sets that do not need to be ordered.
- Internal fragmentation - Internal fragmentation occurs when there is too much free space in the index pages. Typically, some free space is desirable, especially when the index is created or rebuilt. You can specify the Fill Factor setting when the index is created or rebuilt to indicate a percentage of how full the index pages are when created. If the index pages are too fragmented, it will cause queries to take longer (because of the extra reads required to find the dataset) and cause your indexes to grow larger than necessary. If no space is available in the index data pages, data changes (primarily inserts) will cause page splits as discussed above, which also require additional system resources to perform.
As we learned, heavily fragmented indexes can degrade query performance significantly and cause the application accessing it to respond slowly. So now the question is how to identify the fragmentation. SQL Server 2005 and later provides a dynamic management function (DMF) to determine index fragmentation level. This new DMF (sys.dm_db_index_physical_stats) function accepts parameters such as the database, database table, and index for which you want to find fragmentation. There are several options that allow you to specify the level of detail that you want to see in regards to index fragmentation, we will see some of these options in the examples below.
The sys.dm_db_index_physical_stats function returns tabular data regarding one particular table or index.
| Input Parameter | Description |
|---|---|
| database_id | The default is 0 (NULL, 0, and DEFAULT are equivalent values in this context) which specify to return information for all databases in the instance of SQL Server else specify the databaseID from sys.databases if you want information about a specific database. If you specify NULL for database_id, you must also specify NULL for object_id, index_id, and partition_number. |
| object_id | The default is 0 (NULL, 0, and DEFAULT are equivalent values in this context) which specify to return information for all tables and views in the specified database or else you can specify object_id for a particular object. If you specify NULL for object_id, you must also specify NULL for index_id and partition_number. |
| index_id | The default is -1 (NULL, -1, and DEFAULT are equivalent values in this context) which specify to return information for all indexes for a base table or view. If you specify NULL for index_id, you must also specify NULL for partition_number. |
| partition_number | The default is 0 (NULL, 0, and DEFAULT are equivalent values in this context) which specify to return information for all partitions of the owning object. partition_number is 1-based. A nonpartitioned index or heap has partition_number set to 1. |
| mode | mode specifies the scan level that is used to obtain statistics.
Valid inputs are DEFAULT, NULL, LIMITED, SAMPLED, or DETAILED. The default
(NULL) is LIMITED. LIMITED - It is the fastest mode and scans the smallest number of pages. For an index, only the parent-level pages of the B-tree (that is, the pages above the leaf level) are scanned. In SQL Server 2008, only the associated PFS and IAM pages of a heap are examined; the data pages of the heap are not scanned. In SQL Server 2005, all pages of a heap are scanned in LIMITED mode. SAMPLED - It returns statistics based on a 1 percent sample of all the pages in the index or heap. If the index or heap has fewer than 10,000 pages, DETAILED mode is used instead of SAMPLED. DETAILED - It scans all pages and returns all statistics. |
Note
- The sys.dm_db_index_physical_stats dynamic management function replaces the DBCC SHOWCONTIG statement. It requires only an Intent-Shared (IS) table lock in comparison to DBCC SHOWCONTIG which required a Shared Lock, also the algorithm for calculating fragmentation is more precise than DBCC SHOWCONTIG and hence it gives a more accurate result.
- For an index, one row is returned for each level of the B-tree in each partition (this is the reason, if you look at image below, for some indexes there are two or more than two records for a single index; you can refer to the Index_depth column which tells the number of index levels). For a heap, one row is returned for the IN_ROW_DATA allocation unit of each partition. For large object (LOB) data, one row is returned for the LOB_DATA allocation unit of each partition. If row-overflow data exists in the table, one row is returned for the ROW_OVERFLOW_DATA allocation unit in each partition.
Example
Let's see an example. The first script provided below gives the fragmentation level of a given database including all tables and views in the database and all indexes on these objects. The second script gives the fragmentation level of a particular object in the given database. The details about the columns and its meaning returned by the sys.dm_db_index_physical_stats are given in the below table.
--To Find out fragmentation level of a given database --This query will give DETAILED information --CAUTION : It may take very long time, depending on the number of tables in the DB USE AdventureWorks GO SELECT object_name(IPS.object_id) AS [TableName], SI.name AS [IndexName], IPS.Index_type_desc, IPS.avg_fragmentation_in_percent, IPS.avg_fragment_size_in_pages, IPS.avg_page_space_used_in_percent, IPS.record_count, IPS.ghost_record_count, IPS.fragment_count, IPS.avg_fragment_size_in_pages FROM sys.dm_db_index_physical_stats(db_id(N'AdventureWorks'), NULL, NULL, NULL , 'DETAILED') IPS JOIN sys.tables ST WITH (nolock) ON IPS.object_id = ST.object_id JOIN sys.indexes SI WITH (nolock) ON IPS.object_id = SI.object_id AND IPS.index_id = SI.index_id WHERE ST.is_ms_shipped = 0 ORDER BY 1,5 GO
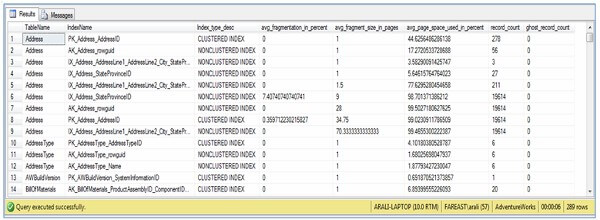
--To Find out fragmentation level of a given database and table
--This query will give DETAILED information
DECLARE @db_id SMALLINT;
DECLARE @object_id INT;
SET @db_id = DB_ID(N'AdventureWorks');
SET @object_id = OBJECT_ID(N'Production.BillOfMaterials');
IF @object_id IS NULL
BEGIN
PRINT N'Invalid object';
END
ELSE
BEGIN
SELECT IPS.Index_type_desc,
IPS.avg_fragmentation_in_percent,
IPS.avg_fragment_size_in_pages,
IPS.avg_page_space_used_in_percent,
IPS.record_count,
IPS.ghost_record_count,
IPS.fragment_count,
IPS.avg_fragment_size_in_pages
FROM sys.dm_db_index_physical_stats(@db_id, @object_id, NULL, NULL , 'DETAILED') AS IPS;
END
GO
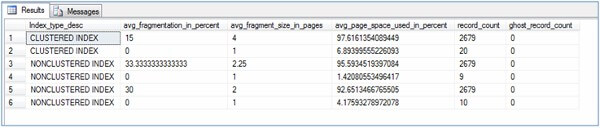
| Returned Column | Description |
|---|---|
| avg_fragmentation_in_percent | It indicates the amount of external fragmentation you have
for the given objects.
The lower the number the better - as this number approaches 100% the more pages you have in the given index that are not properly ordered. For heaps, this value is actually the percentage of extent fragmentation and not external fragmentation. |
| avg_page_space_used_in_percent | It indicates how dense the pages in your index are, i.e. on average
how full each page in the index is (internal fragmentation).
The higher the number the better speaking in terms of fragmentation and read-performance. To achieve optimal disk space use, this value should be close to 100% for an index that will not have many random inserts. However, an index that has many random inserts and has very full pages will have an increased number of page splits. This causes more fragmentation. Therefore, in order to reduce page splits, the value should be less than 100 percent. |
| fragment_count | A fragment is made up of physically consecutive leaf pages in the same file for an allocation unit. An index has at least one fragment. The maximum fragments an index can have are equal to the number of pages in the leaf level of the index. So the less fragments the more data is stored consecutively. |
| avg_fragment_size_in_pages | Larger fragments mean that less disk I/O is required to read the same number of pages. Therefore, the larger the avg_fragment_size_in_pages value, the better the range scan performance. |
Next Steps
- Review Identify Database Fragmentation in SQL Server tip.
- Review sys.dm_db_index_physical_stats on MSDN.
- Once you have identified the high fragmentation level, the next step is to fix it, in my next tip I am going to write more about the different ways to fix high fragmentation levels.






About the author
 Arshad Ali is a SQL and BI Developer focusing on Data Warehousing projects for Microsoft.
Arshad Ali is a SQL and BI Developer focusing on Data Warehousing projects for Microsoft.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2009-03-16
