By: K. Brian Kelley | Updated: 2009-11-17 | Comments (13) | Related: > Clustering
Problem
I want to institute a high availability solution for SQL Server with no downtime. I am planning on using Microsoft clustering, but I have been told that in the event that the cluster moves the SQL Server from one physical server to another, that there is some downtime. Why is this so?
Solution
There is indeed a period of downtime whenever the SQL Server moves from one physical server to another in a traditional Microsoft clustering solution. Let's take a quick look at why that is.
First, let's consider a typical two-node cluster setup (Figure 1):
Figure 1:
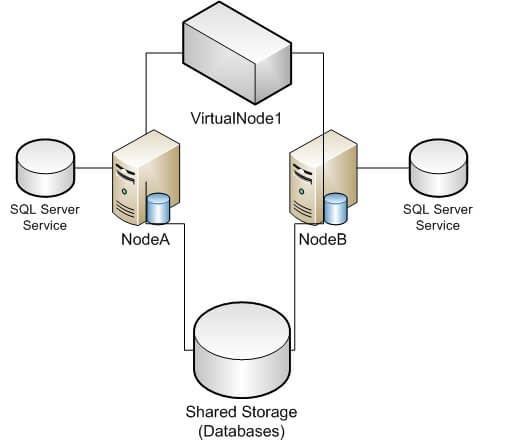
In a typical Microsoft clustering solution, all the databases reside on shared storage which all the physical servers, called nodes, can access. However, only one node can access the storage at a given time.
In addition, the SQL Server service for a particular instance of SQL Server installed on the cluster resides on each physical node where SQL Server is allowed to run. For instance, in the case of a default instance, with a SQL Server 2008 default instance setup, we would see a service called SQL Server (MSSQLServer) on each node. For a named instance called MyNamedInstance, we would see a service called SQL Server (MyNamedInstance) on each node. Because the service needs to access the databases, only the node which has access to the shared storage can successfully have the SQL Server service running. All other nodes will have the SQL Server service present in the services list, but in a stopped state. And finally, because of the fact that this SQL Server instance will need to move around between the physical nodes, in a clustering setup the SQL Server is configured to run on a virtual node, one that can float between the nodes.
These virtual node will have the following characteristics that are different from any of the physical nodes:
- Its own IP address
- Its own network (NetBIOS and DNS) name
So in the example shown in Figure 1 above, the physical nodes NodeA and NodeB can run the SQL Server instance. They both can access the shared storage and they both have the appropriate SQL Server service installed. For someone who wants to access the SQL Server, they must do so through the virtual node, which I've called VirtualNode1. So I wouldn't connect to NodeA or NodeB, I would set my connection to VirtualNode1. Now I'm simplifying a bunch about how clustering works and how SQL Server interacts with the cluster (and vice versa), but hopefully this gives a good overall picture of Microsoft SQL Server on a Microsoft clustering solution.
Now that we have the big picture view, let's look at the specifics of SQL Server running. We'll start by looking at Figure 2, where NodeA has control of the shared storage and where SQL Server is running. You can note this by the thicker lines from NodeA to the various resources.
Figure 2:

So if we take a look at both NodeA and NodeB, we'll see that NodeA has the storage. You'll see the drive letters which belong to the SQL Server databases on that physical server. You'll be able to access the files on them and read them (provided they aren't already in use, such as the SQL Server databases themselves). While you might see the drive letters on NodeB, you won't be able to access them. The operating system will give you an error telling you the disk isn't available. Also, if we look at the services, we'll see the SQL Server service started and running on NodeA. On NodeB it'll be stopped. And if we check on the networking side, we'll see that NodeA isn't just running with its IP address, but also the IP address for VirtualNode1. NodeB will just have NodeB's IP address.
Now let's look at a situation where an administrator gracefully moves the SQL Server from running on NodeA to NodeB. And when we look at what happens behind the scenes, we'll see why there is downtime.
The cluster receives the request from the administrator and then proceeds to perform the following steps:
- Stops the SQL Server Agent service and any services dependent on the SQL Server service.
- Stops the SQL Server service (meaning SQL Server isn't available at this point).
- Releases NodeA's hold on the IP address and network name for VirtualNode1.
- Releases NodeA's hold on the shared storage.
- Tells NodeB to take control of the shared storage (which it does).
- Tells NodeB to take control of the IP address and network name for VirtualNode1.
- Starts the SQL Server service on NodeB (meaning SQL Server is coming back on-line for its clients).
- Starts the SQL Server Agent service and any services dependent on the SQL Server service.
Again, I've simplified a lot of things, but this 8 step process is basically what the cluster is doing. Note that from step 2 to step 7 SQL Server is down. NodeA has to release the resources SQL Server is dependent on so that NodeB can take control of them. Until NodeB has control of them, it can't restart the SQL Server service. So even if the shared storage and networking transfer were to happen in milliseconds, you still have the time it takes for the SQL Server service to stop and restart as downtime. There are things that could cause this to draw out, such as a configuration on 32-bit servers where AWE memory is used (along with lock pages in memory). In situations like that, the downtime is extended to take care of these matters. But once the graceful move is over, we'll see our resources on NodeB, such as what is shown in Figure 3.
Figure 3:

And when we look at the two physical nodes, we'll see that NodeB has the storage and the IP address for VirtualNode1. We'll also see that the SQL Server service is running on NodeB but is stopped on NodeA. The situation is a reverse of what we saw in Figure 2.
But what about when we have an unintentional "fail-over" such as when NodeA goes down? In this particular case, the cluster will have to realize the node is not available any longer. It does this fairly quickly, but then it still must tell NodeB to bring the resources on-line. So basically we'll be going through steps 5 through 8 from above. Again, we'll see the downtime from whenever the SQL Server became unavailable, such as when NodeA dropped off-line, until NodeB is able to get all the resources under its control and successfully starts its SQL Server service. This is the best case scenario, a perfect fail-over situation, if you will, and this is the quickest scenario for SQL Server to come back online in the event of a real problem. There could be other cases such as when NodeA isn't down but SQL Server is unresponsive (but the service is still running). In this case, the cluster won't note that SQL Server is not available until its "keep alive" check fails. Once it determines SQL Server is not responsive, it will go through the process of trying to gracefully go through all the steps. If there any complications, then the downtime will be extended as the cluster tries to deal with them.
So with a Microsoft clustering solution, there will always be some amount of downtime as the SQL Server moves from one physical node to another, whether this be intentional, such as when it's initiated by a system administrator, or in the event of a failure, such as when the physical node SQL Server was running on suddenly becomes unavailable. Generally, the amount of time its unavailable is relatively small and that's why its considered a satisfactory high availability solution for most scenarios. But it must be understood that in this configuration, downtime is a given.
Next Steps
- Review these other clustering tips
- For other high availability options review these database mirroring tips






About the author
 K. Brian Kelley is a SQL Server author and columnist focusing primarily on SQL Server security.
K. Brian Kelley is a SQL Server author and columnist focusing primarily on SQL Server security.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2009-11-17
