By: Tim Cullen | Updated: 2010-04-02 | Comments (4) | Related: > Spatial Data Storage
Problem
The institution I work with has decided to migrate their database system to SQL Server 2008. One of the applications uses geospatial data, which consists of millions of rows. I understand that their are indexes that can be used for geospatial data, but have not worked with them. What's the scoop on them?
Solution
Geospatial data has certainly become an important component in applications for everything from tracking packages via delivery services to the outdoor activity of geocaching. Before long these tables can grow to millions of records. Although SQL Server has indexes that assist in narrowing a result set, the storage of geospatial data as a binary format represents an interesting challenge in terms of indexing. SQL Server 2008 provides Spatial Indexes for this situation.
Like other indexes in SQL Server, spatial indexes utilize a B-Tree structure. B-tree structures, however, can represent data in only two dimensions, so the index re-factors the space into a four-level grid hierarchy, referred to as Level 1, which is the top level; Level 2; Level 3; and Level 4. Level One is more like a "bird's eye view" of the covered area; each level below that takes a section of the previous level and further divides it into another grid. The numbering of the cells shows the hierarchy. The first cell in Level One is 1; the first cell in Level Two is 1.1 because it is a subsection of Level One. This hierarchical model is built into the query processor, which allows for minimal storage of the information needed. Each level contains the same number of same-sized cells, the size of which can be specified when creating the index. The more cells in an index, the more dense the grid is. So a grid with 64 cells is more dense than a grid with 16 cells.
When a spatial index is created, it first performs the refactoring of space. It then performs a tessellation process, whereby it fits the space represented by the data into the previously created grid hierarchy without gaps or overlaps. The tessellation process is governed by three rules:
| Rule Name | Description |
|---|---|
| The covering rule | If an object completely covers a cell and overlaps into other cells then the cell is recorded in the index and no other attempt is made to maneuver other objects against that cell |
| The cells-per-object rule | A limit on the number of objects that tessellation can occur with in a given cell. This limitation is enforced in all levels except for Level One and can be customized when creating the index (the maximum values is 8192) |
| The deepest-cell rule | This rule takes advantage of the hierarchical model mentioned earlier
by recording only the information required in the deepest cell |
There are some restrictions on creation of a spatial index. First, spatial indexes can only be created on either a geometry or geography data type. Second, the table must have a primary key constraint with a maximum of 15 columns. Once a spatial index is created on a table the primary key composition cannot be modified. Third, the maximum size of index key records is 895 bytes. Fourth, spatial indexes cannot be created on indexed views.
Creating a Spatial Index Using SQL Server Management Studio
Navigate through the object tree to the Indexes section of the table on which the index will be created
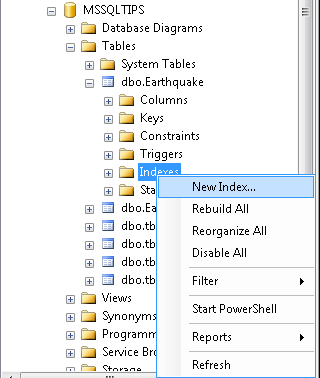
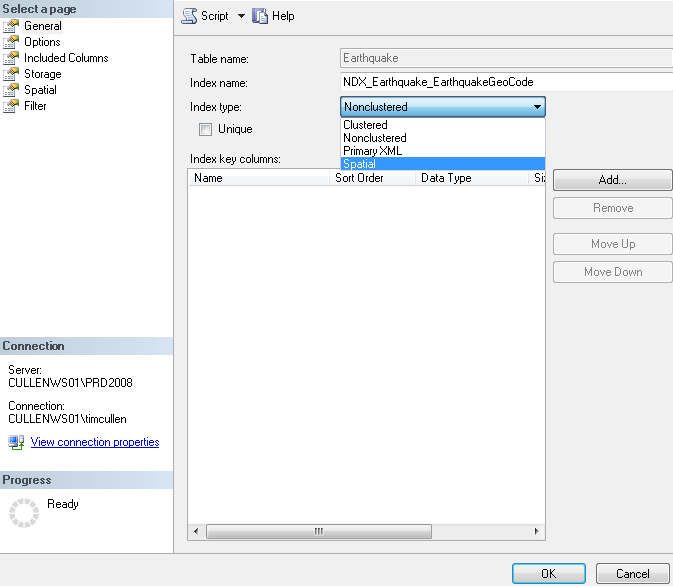
Type in a name for the index and choose SPATIAL in the Index Type
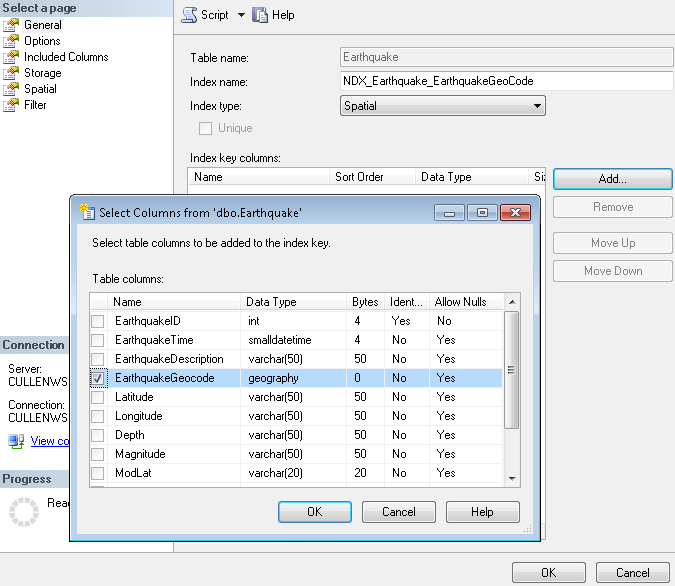
Click Add in the Index Key Columns section and click OK
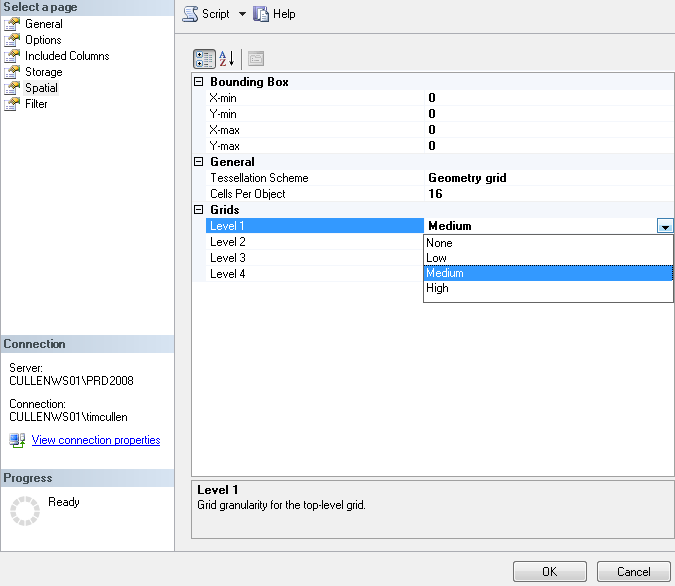
The choice for tessellation is tied to the data type on which the index will be created. On the left lower side (in the Progress area) you'll see that an error was previously generated. I attempted to create an index on a geography data column using the GEOMETRY_GRID tessellation scheme.
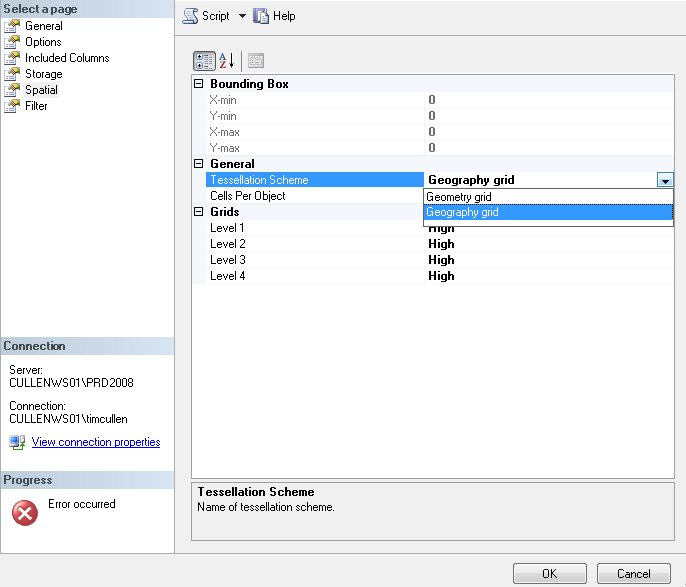
On the left side of the main Index Creation are additional options for the index. Of most importance is the Spatial section. In this section you can specify the bounding box parameters (for indexes on geometry columns only) and grid density.
Creating a Spatial Index Using Transact-SQL
CREATE SPATIAL INDEX [NDX_Earthquake_EarthquakeGeoCode]
ON
[dbo].[Earthquake] ([EarthquakeGeocode])
USING GEOGRAPHY_GRID
WITH
(
GRIDS=(LEVEL_1 = HIGH,LEVEL_2 = HIGH,LEVEL_3 = HIGH,LEVEL_4 = HIGH)
, CELLS_PER_OBJECT = 64
, PAD_INDEX = OFF
, SORT_IN_TEMPDB = OFF
, DROP_EXISTING = OFF
, ALLOW_ROW_LOCKS = ON
, ALLOW_PAGE_LOCKS = ON
)
ON [PRIMARY]
| Script Dissection | |
|---|---|
| CREATE SPATIAL INDEX [NDX_Earthquake_EarthquakeGeoCode] ON [dbo].[Earthquake] ([EarthquakeGeocode]) |
This section specifies the index type, the index name, and the table
and column the index will be created on. The syntax is essentially the same
as for non-clustered index creation aside from the word SPATIAL
|
| Geography data type USING GEOGRAPHY_GRID Geometry data type USING GEOMETRY_GRID |
This section identifies which grid type to use (either GEOMETRY_GRID
or GEOGRAPHY_GRID). The default for the grid is the corresponding data type.
If you attempt index creation using a grid type different from the data
type an error will be returned |
| Geography data type WITH ( GRIDS=(LEVEL_1 = HIGH,LEVEL_2 = HIGH,LEVEL_3 = HIGH,LEVEL_4 = HIGH) , CELLS_PER_OBJECT = 64 Geometry data type WITH (BOUNDING_BOX =(0, 0, 1800, 1800)) GRIDS=(LEVEL_1 = HIGH,LEVEL_2 = HIGH,LEVEL_3 = HIGH,LEVEL_4 = HIGH) , CELLS_PER_OBJECT = 64 |
This section specifies either the grid density and the number of cells per object (geography data type) or the bounding boxes (geometry data type). Again, when creating a spatial index for a geography data column the maximum number of cells per object is 8192 (an error will be returned if you try to specify a higher value). As for |
Performance Difference
To show the difference in performance let's look at the number of earthquakes near my fictional getaway spot near Fiji. The approximate coordinates of my little getaway is 179.41 Longitude by -16.57 Latitude. I would like to see how many earthquakes' epicenters occurred within 100 miles of my getaway. There are a little over 3100 earthquakes in the dataset (since February, 2009) , with 125 of them whose epicenter was close enough to Fiji so that the description of the location has the word Fiji in it. In the query I declare a geography type variable and set it equal to my getaway coordinates. Then I look for all earthquakes where the distance between it and my getaway are less than or equal to 100 miles (528,000 feet):
DECLARE @Getaway GEOGRAPHY
SELECT @Getaway = geography::STGeomFromText('POINT(178.31 -16.8)', 4326)
SELECT
EarthquakeID
, CONVERT(CHAR(10),EarthquakeTime,101) + ' ' +
CONVERT(CHAR(8),EarthquakeTime,108) as EarthquakeTime
, EarthquakeDescription
, EarthquakeGeocode.Long as Longitude
, EarthquakeGeocode.Lat as Latitude
, EarthquakeGeocode.M as Magnitude
, EarthquakeGeocode.Z as Depth
, CONVERT(NUMERIC(4,1),@Getaway.STDistance(EarthquakeGeocode)/5280) as MilesAway
FROM
MSSQLTIPS.dbo.Earthquake (nolock)
WHERE
@Getaway.STDistance(EarthquakeGeocode) < 528000
ORDER BY
CONVERT(NUMERIC(4,1),@Getaway.STDistance(EarthquakeGeocode)/5280);
I executed the query three ways: without a spatial index or primary key, with a primary key but without the spatial index, and with both the primary key and spatial index. During the executions I captured the actual execution plan, IO statistics, and time statistics. Executing the query with no indexes at all ran as you would expect, a TABLE SCAN. Once a primary key constraint was created on the table I executed the query. Again, the execution plan showed exactly what was expected, a CLUSTERED INDEX SCAN. When the spatial index was created, a whole different scenario appeared:
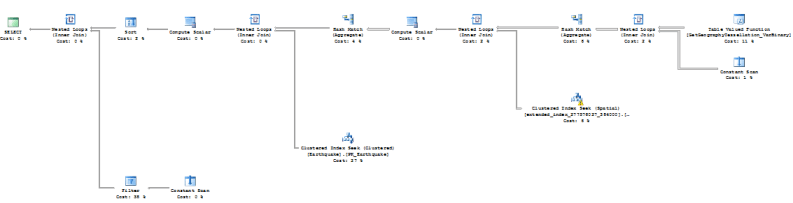
| Clustered Index Only | After Spatial Index Creation |
|---|---|
| (51 row(s) affected) Table 'Earthquake'. Scan count 1, logical reads
88, physical reads 0, read-ahead reads 0, lob logical reads 0 , lob physical
reads 0, lob read-ahead reads 0. (1 row(s) affected) SQL Server Execution Times: CPU time = 218 ms, elapsed time = 357 ms. SQL Server Execution Times: CPU time = 0 ms, elapsed time = 0 ms. |
(51 row(s) affected) Table 'Earthquake'. Scan count 0, logical reads
136, physical reads 0, read-ahead reads 0, lob logical reads 0 , lob physical
reads 0, lob read-ahead reads 0. Table 'Worktable'. Scan count 0, logical
reads 0, physical reads 0 , read-ahead reads 0, lob logical reads 0, lob
physical reads 0, lob read-ahead reads 0. Table 'extended_index_277576027_384000'.
Scan count 2054, logical reads 4108, physical reads 0, read-ahead reads
0 , lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.(1
row(s) affected) SQL Server Execution Times: CPU time = 47 ms, elapsed time = 163 ms. SQL Server Execution Times: CPU time = 0 ms, elapsed time = 0 ms. |
Performance is certainly enhanced, even in the relatively small earthquake dataset I was working against. You can experiment with the cell density and other aspects of the spatial index to meet the needs of your organization. Although it doesn't usually make sense to have multiple indexes covering the same table column, multiple indexes on a spatial data column can be used with different tessellation parameters in certain conditions.
Next Steps
- Many thanks to GeoCommunity for sending me the daily newsletter that contains both the geospatial news of the day as well as recent earthquakes around the globe!
- If you are interested in learning more about spatial indexes and would like to use the data I collected, click here for a Zip file containing both a flat file and XML file
- Read the Spatial Indexing Overview on Microsoft TechNet
- Stay tuned for more Spatial Data Storage Tips






About the author
 Tim Cullen has been working in the IT industry since 2003 and currently works as a SQL Server Reports Developer.
Tim Cullen has been working in the IT industry since 2003 and currently works as a SQL Server Reports Developer.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2010-04-02
