By: Arshad Ali | Updated: 2020-07-29 | Comments (8) | Related: > JOIN Tables
Problem
In the tip SQL Server Join Examples, Jeremy Kadlec talked about different logical join operators, but how does SQL Server implement them physically? What are the different physical join operators? How are they different from each other and in what scenario is one preferred over other? In this tip, we cover these questions and more.Solution
We use logical operators when we write queries to define a relational query at the conceptual level (what needs to be done). SQL implements these logical operators with three different physical operators to implement the operation defined by the logical operators (how it needs to be done). Although there are dozens of physical operators, in this tip I will cover specific physical join operators. Although we have different kinds of logical joins at the conceptual/query level, but SQL Server implements them all with three different physical join operators as discussed below.
We will cover:
- Nested Loops Join
- Merge Join
- Hash Join
We will look at execution plans to see these operators and I will explain why each occurs.
For these examples, I am using the AdventureWorks database.
SQL Server Nested Loops Join Explained
Before digging into the details, let me tell you first what a Nested Loops join is if you are new to the programming world.
A Nested Loops join is a logical structure in which one loop (iteration) resides inside another one, that is to say for each iteration of the outer loop all the iterations of the inner loop are executed/processed.
A Nested Loops join works in the same way. One of the joining tables is designated as the outer table and another one as the inner table. For each row of the outer table, all the rows from the inner table are matched one by one if the row matches it is included in the result-set otherwise it is ignored. Then the next row from the outer table is picked up and the same process is repeated and so on.
The SQL Server optimizer might choose a Nested Loops join when one of the joining tables is small (considered as the outer table) and another one is large (considered as the inner table which is indexed on the column that is in the join) and hence it requires minimal I/O and the fewest comparisons.
The optimizer considers three variants for a Nested Loops join:
- naive nested loops join in which case the search scans the whole table or index
- index nested loops join when the search can utilize an existing index to perform lookups
- temporary index nested loops join if the optimizer creates a temporary index as part of the query plan and destroys it after query execution completes
An index Nested Loops join performs better than a merge join or hash join if a small set of rows are involved. Whereas, if a large set of rows are involved the Nested Loops join might not be an optimal choice. Nested Loops support almost all join types except right and full outer joins, right semi-join and right anti-semi joins.
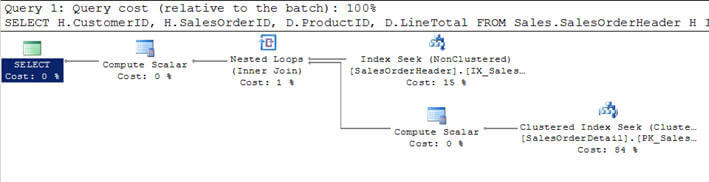
- In Script #1, I am joining the SalesOrderHeader table with SalesOrderDetail table and specifying the criteria to filter the result of the customer with CustomerID = 670.
- This filtered criteria returns 12 records from the SalesOrderHeader table and hence being the smaller one, this table has been considered as the outer table (top one in the graphical query execution plan) by the optimizer.
- For each row of these 12 rows of the outer table, rows from the inner table SalesOrderDetail are matched (or the inner table is scanned 12 times each time for each row using the index seek or correlated parameter from the outer table) and 312 matching rows are returned as you can see in the second image.
- In the second query below, I am using SET STATISTICS PROFILE ON to display profile information of the query execution along with the query result-set.
Script #1 - Nested Loops Join Example
SELECT H.CustomerID, H.SalesOrderID, D.ProductID, D.LineTotal FROM Sales.SalesOrderHeader H INNER JOIN Sales.SalesOrderDetail D ON H.SalesOrderID = D.SalesOrderID WHERE H.CustomerID = 670
SET STATISTICS PROFILE ON SELECT H.CustomerID, H.SalesOrderID, D.ProductID, D.LineTotal FROM Sales.SalesOrderHeader H INNER JOIN Sales.SalesOrderDetail D ON H.SalesOrderID = D.SalesOrderID WHERE H.CustomerID = 670 SET STATISTICS PROFILE OFF

If the number of records involved is large, SQL Server might choose to parallelize a nested loop by distributing the outer table rows randomly among the available Nested Loops threads dynamically. It does not apply the same for the inner table rows though. To learn more about parallel scans click here.
SQL Server Merge Join Explained
The first thing that you need to know about a Merge join is that it requires both inputs to be sorted on join keys/merge columns (or both input tables have clustered indexes on the column that joins the tables) and it also requires at least one equijoin (equals to) expression/predicate.
Because the rows are pre-sorted, a Merge join immediately begins the matching process. It reads a row from one input and compares it with the row of another input. If the rows match, that matched row is considered in the result-set (then it reads the next row from the input table, does the same comparison/match and so on) or else the lesser of the two rows is ignored and the process continues this way until all rows have been processed..
A Merge join performs better when joining large input tables (pre-indexed / sorted) as the cost is the summation of rows in both input tables as opposed to the Nested Loops where it is a product of rows of both input tables. Sometimes the optimizer decides to use a Merge join when the input tables are not sorted and therefore it uses an explicit sort physical operator, but it might be slower than using an index (pre-sorted input table).
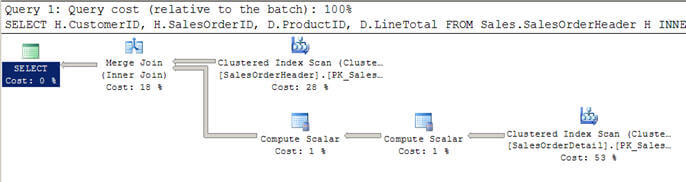
- In Script #2, I am using a similar query as above, but this time I have added a WHERE clause to get all customer greater than 100.
- In this case, the optimizer decides to use a Merge join as both inputs are large in terms of rows and they are also pre-indexed/sorted.
- You can also notice that both inputs are scanned only once as opposed to the 12 scans we saw in the Nested Loops join above.
Script #2 - Merge Join Example
SELECT H.CustomerID, H.SalesOrderID, D.ProductID, D.LineTotal FROM Sales.SalesOrderHeader H INNER JOIN Sales.SalesOrderDetail D ON H.SalesOrderID = D.SalesOrderID WHERE H.CustomerID > 100
SET STATISTICS PROFILE ON SELECT H.CustomerID, H.SalesOrderID, D.ProductID, D.LineTotal FROM Sales.SalesOrderHeader H INNER JOIN Sales.SalesOrderDetail D ON H.SalesOrderID = D.SalesOrderID WHERE H.CustomerID > 100 SET STATISTICS PROFILE OFF

A Merge join is often a more efficient and faster join operator if the sorted data can be obtained from an existing B-tree index and it performs almost all join operations as long as there is at least one equality join predicate involved. It also supports multiple equality join predicates as long as the input tables are sorted on all joining keys involved and are in the same order.
The presence of a Compute Scalar operator indicates the evaluation of an expression to produce a computed scalar value. In the above query I am selecting LineTotal which is a derived column, hence it has been used in the execution plan.
SQL Server Hash Join Explained
A Hash join is normally used when input tables are quite large and no adequate indexes exist on them. A Hash join is performed in two phases; the Build phase and the Probe phase and hence the hash join has two inputs i.e. build input and probe input. The smaller of the inputs is considered as the build input (to minimize the memory requirement to store a hash table discussed later) and obviously the other one is the probe input.
During the build phase, joining keys of all the rows of the build table are scanned. Hashes are generated and placed in an in-memory hash table. Unlike the Merge join, it's blocking (no rows are returned) until this point.
During the probe phase, joining keys of each row of the probe table are scanned. Again hashes are generated (using the same hash function as above) and compared against the corresponding hash table for a match.
A Hash function requires significant amount of CPU cycles to generate hashes and memory resources to store the hash table. If there is memory pressure, some of the partitions of the hash table are swapped to tempdb and whenever there is a need (either to probe or to update the contents) it is brought back into the cache. To achieve high performance, the query optimizer may parallelize a Hash join to scale better than any other join, for more details click here.
There are basically three different types of hash joins:
- In-memory Hash Join in which case enough memory is available to store the hash table
- Grace Hash Join in which case the hash table cannot fit in memory and some partitions are spilled to tempdb
- Recursive Hash Join in which case a hash table is so large the optimizer has to use many levels of merge joins.
For more details about these different types cclick here.
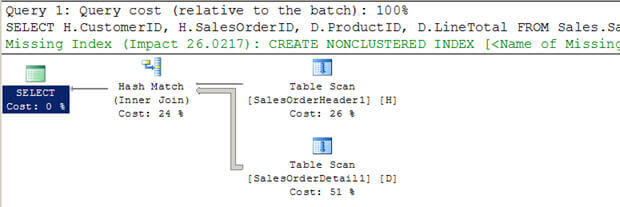
- In Script #3, I am creating two new large tables (from the existing AdventureWorks tables) without indexes.
- You can see the optimizer chose to use a Hash join in this case.
- Again unlike a Nested Loops join, it does not scan the inner table multiple times.
Script #3 - Hash Join Example
--Create tables without indexes from existing tables of AdventureWorks database SELECT * INTO Sales.SalesOrderHeader1 FROM Sales.SalesOrderHeader SELECT * INTO Sales.SalesOrderDetail1 FROM Sales.SalesOrderDetail GO SELECT H.CustomerID, H.SalesOrderID, D.ProductID, D.LineTotal FROM Sales.SalesOrderHeader1 H INNER JOIN Sales.SalesOrderDetail1 D ON H.SalesOrderID = D.SalesOrderID WHERE H.CustomerID = 670 GO
SET STATISTICS PROFILE ON SELECT H.CustomerID, H.SalesOrderID, D.ProductID, D.LineTotal FROM Sales.SalesOrderHeader1 H INNER JOIN Sales.SalesOrderDetail1 D ON H.SalesOrderID = D.SalesOrderID WHERE H.CustomerID = 670 SET STATISTICS PROFILE OFF

--Drop the tables created for demonstration DROP TABLE Sales.SalesOrderHeader1 DROP TABLE Sales.SalesOrderDetail1
Note: SQL Server does a pretty good job in deciding which join operator to use in each condition. Understanding these conditions helps you to understand what can be done in performance tuning. It's not recommended to use join hints (using OPTION clause) to force SQL Server to use a specific join operator (unless you have no other way out), but rather you can use other means like updating statistics, creating indexes or re-writing your query.
Next Steps
- Review SQL Server Join Examples tip.
- Review Logical and Physical Operators Reference article on technet.






About the author
 Arshad Ali is a SQL and BI Developer focusing on Data Warehousing projects for Microsoft.
Arshad Ali is a SQL and BI Developer focusing on Data Warehousing projects for Microsoft.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2020-07-29
