By: Chad Boyd | Updated: 2008-02-07 | Comments | Related: 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | > Fragmentation and Index Maintenance
In the prior post (http://www.mssqltips.com/sqlservertip/2261/sql-server-fragmentation-storage-basics-and-access-methods-part-1-of-9/), we got through discussing the different types of fragmentation, and showed some diagrams of what they would conceptually look like under the covers. In this 3rd post, we'll dig into the different types of fragmentation a bit further to try and understand some of the different causes of each type of fragmentation as well as discuss what measures can be taken to avoid each type as much as possible. A few future posts will get into how each type impacts performance (and when it doesn't), when you need to worry (and when you don't), how to address it, etc., etc.
So, what causes it and how can I avoid it? Well, the answer varies for the different types of fragmentation, so let's use the same classifications of fragmentation as we did in the prior post and try to define the answers for each of them - since we're going to be referencing each type of fragmentation from the prior post, I won't be restating any of the "what is it" type information here, so if you need a reference on what it is, refer back to the 2nd post in the series:
LOGICAL FRAGMENTATION
Logical fragmentation primarily results from page splitting, or page splits. Aside from page splits, logical fragmentation can also be introduced by deleting data (resulting in free space within a page, dropping the page density). You could also say that fragmentation can be introduced by other DML (insert, update), however the majority of the time this causes fragmentation by the action resulting in a page split anyhow, so we won't cover it separately. The better question to answer for understanding this type of fragmentation is what can cause a page split.
A page split is what occurs to a database page when new data of some kind needs to fit a page, but there is not enough room on the page to accommodate all the data needed to be placed in the page. Page splits do NOT occur on a heap, only on indexes (clustered or non-clustered). What a page split is involves a complicated discussion, because it is a fairly complicated operation - for the sake of ease of description, think of it as a single page being split in half, with 1/2 of the rows on the page moving to a newly allocated page, and the other 1/2 of the rows remaining where they are. Also, though a page split can occur on any index page (root, intermediate, leaf), we'll limit our discussion here for now to splits of leaf pages of an index, since that is by far the most common, and also by far the causes the most impact.
2 operations that can commonly cause a page split include:
- Inserting a new record onto a full/nearly full page - this will occur when you have an index (clustered or non-clustered) on a column(s) and the new record to be inserted is not positioned at the end of the existing index chain (i.e. it needs to be inserted somewhere in the "middle" of the existing pages). This will never occur when the index key columns are ever-increasing (i.e. identity values, increasing date/time values (assuming none occur at the same time), etc.).
- Updating an existing record's variable-length column(s) to larger values on pages that don't have enough free-space to accommodate the increased sizes. This can only occur with variable-length values, since fixed-length columns are always stored with a fixed storage footprint. To be accurate, this type of update would be applied by the SQL engine as first a delete of the existing row followed by an insert of the new data.
As you can deduce, a page split introduces multiple types of logical fragmentation at once: a) since the 2 pages involved in the page split operation hold only 1/2 the records as originally fit on a single page, the 2 pages are only about 50% full each, and b) since a new page had to be allocated to hold 1/2 the records, there's a very good chance that this new page is not physically contiguous with the logically ordered previous/next pages in the linked list. Therefore, you end up with pages that have a lower page density, are not contiguous, and hence not properly ordered. Not very desirable indeed!
An additional contributor to logical fragmentation is ironically something that is typically used to try and avoid it, but is many times used incorrectly - fill-factor. Setting a fill-factor for an index will limit how full a page is allowed to become as a percentage, thereby attempting to leave a certain amount of free-space in every page to ward-off eventual page-splits. Naturally, if this is used correctly and appropriately, it can be a very desirable feature - used incorrectly however, it can cause bloated page-counts and an overall inefficiency in that page density for given indexes. We'll discuss in a future post how you can use this to avoid page-splitting, when it should be used, when it should never be used, etc., but you also need to be aware that it must be used carefully and correctly to ensure you're not causing more harm than good. As mentioned in a previous post, page density is the only type of fragmentation that not only hurts performance on physical IO operations to/from disk, but also hurts performance within the data cache, or in memory, since a low page density leads to more pages,which leads to more pages required to store the same number of records.
Let's see what we can do to try and display logical fragmentation in a simple set of diagrams:

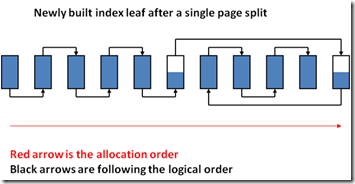




Images originally created by and courtesy of Paul Randal from SQLSkills.com from various presentations.
EXTENT FRAGMENTATION
Extent fragmentation is primarily caused by 2 things:
- Allocations of free-space to mixed/multiple data structures within the same file - all storage structures at one point or another will most likely require more space to store more data (heaps, non-clustered indexes, clustered indexes, etc.). As this occurs, extents are allocated to each object when requested to store more data in. If these requests are coming from multiple structures (not necessarily multiple tables, could be multiple indexes from the same table even), then these extents are going to become interleaved within the given data file(s) as the requests are fulfilled. There's a good chance that some structures will have more contiguous extents than others (i.e. the objects that incur the most write activity will likely have more contiguous extents than objects with a small amount of write activity), but if multiple structures are storing data within the same data file, you'll end up with extent fragmentation to some degree almost certainly.
- Using multiple data files - if you use multiple data files to store data for a single storage structure, you'll end up with extent fragmentation (this is probably obvious). Since extents are allocated in a round-robin type fashion using a proportional fill algorithm, the chances are very, very good that extents from the same structure will be stored in different files.
To again try and use a simple diagram to display what this might look like, let's try:

Image originally created by and courtesy of Paul Randal from SQLSkills.com from various presentations.
FILE-LEVEL FRAGMENTATION
I'm not going to discuss how a single allocation request from SQL Server to the OS and beyond could potentially be scattered across a spindle(s) and hence be technically fragmented from the start - i.e., let's make the assumption for now that if SQL Server requests 50gb of new space from the OS/beyond for a new data file (or a growing file) that it will be granted a fully contiguous block of 50gb of space. Obviously, this is not the case, but to the extent possible, it would be granted as much contiguous space as is possible generally for the given spindle(s). A discussion on how this can cause file-level fragmentation could be quite involved. So, let's concentrate on what else can contribute to this type of fragmentation that we have a bit more control over:
- Other applications/services/etc. (or SQL Server itself) writing data to the same spindles that SQL Server data/log files reside on - this can lead to fragmentation on the file system because as the SQL Server files grow, they end up being allocated space on the spindle(s) that is not physically contiguous to prior allocations for the same file, since data for these other applications/services/etc. have been allocated that space for storing whatever data it may be (could be a word document, could be a backup file (sql server or otherwise), could a another sql server data file, could be a text document, etc., etc.). Notice that it doesn't have to be a non-sql server file that can cause file-level fragmentation - if you have 2 data files (even for the same database) that reside on the same spindle(s), and those files have grown multiple times, chances are quite good that they are interleaved on disk.
- Auto-growth / growth of data/log files - this doesn't just apply to auto-grow, it applies to any growth of the file(s), manual or automatic. Generally auto-grow is the larger contributor in cases where this is a problem because it's more feasible that a file has auto-grown hundreds/thousands/millions of times in small scattered chunks than manually so.
To display this is a simple diagram, if a set of storage spindles could be described as contiguous from left-right as implied in the diagram below, and you assume each color-coded block is a section of data for each given file, file-level fragmentation might look like this:

Image originally created by and courtesy of Paul Randal from SQLSkills.com from various presentations.
Ok, that covers most of the major "what causes it" topics - next post we'll start talking about what can be done to avoid these different types of fragmentation...






About the author
 Chad Boyd is an Architect, Administrator and Developer with technologies such as SQL Server, .NET, and Windows Server.
Chad Boyd is an Architect, Administrator and Developer with technologies such as SQL Server, .NET, and Windows Server.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2008-02-07
