By: Siddharth Mehta | Updated: 2011-04-22 | Comments (3) | Related: > Analysis Services Dimensions
Problem
In a parent child dimension, when an attribute's usage type is set as Parent and browsed from a client tool, many designers as well as users may get confused based on the displayed results. For example, when you browse a parent attribute in a parent child dimension like Employee and say the parent attribute is Employees, you can browse data members from the parent node until the deepest available level of the child node. By default you will find each parent member having a child member with the same name even though this member might not exist in the data. From a user experience point of view this is not a desirable way of browsing a parent child hierarchy because it may get confusing. In this tip we will look at an example of this issue and how to solve this problem.
Solution
The Parent attribute in a parent-child dimension is a special kind of attribute. To visualize the problem, we need to a have a parent child dimension with a parent attribute. For the purpose of this tip, we will use the AdventureWorks sample that ships with SQL Server. Open this solution and deploy it and then browse the Employees attribute of the Employee dimension. Employees is an attribute whose usage type is set to "Parent" in the Employee dimension. When you browse this attribute, you will find the properties as shown in the below screenshot.
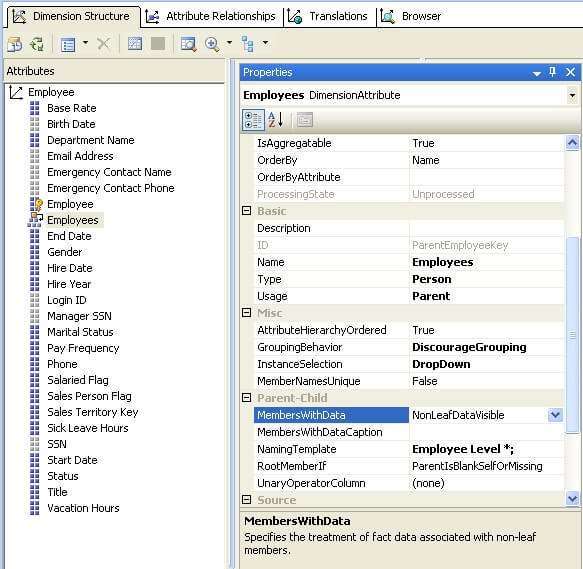
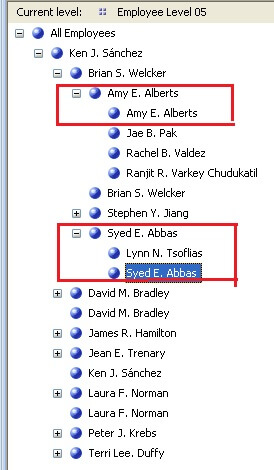
As you can see below the parent member is also available as a child member and this has the potential to confuse users.
It would be beneficial to understand the reason for this data representation before we proceed with the solution. Say a manager has two employees and all of them have their own sales targets. As per the hierarchy, the manager should be shown as a parent node and both employees should be displayed as child nodes. From an aggregation point of view, both these employees data can roll up to their manager, but manager is also an employee and can have his own targets. So the final data value associated with manager would be the roll up value of both employees as well as his own individual data value. This is the reason SSAS adds a system generated data member which is the parent member itself in the hierarchy. This has no effect on aggregation, but the intention is to preserve the individuality of the parent node in the display of the hierarchy.
In the below screenshot, you can see the setting for the Employees attribute. The above mentioned issue is a result of a property named "MembersWithData" which has a default value of "NonLeafDataVisible".
Our intention is to hide this system generated data member, so that when the hierarchy is browsed, the parent attribute is not shown as a child member to itself. To change this, modify the value of "MembersWithData" to "NonLeafDataHidden" as shown in the below screenshot.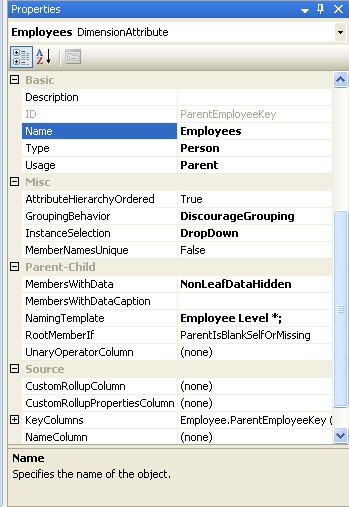
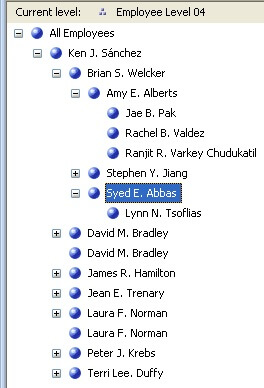
After changing this value, process the dimension and deploy it. Connect to the cube and browse the parent attribute of the "Employee" dimension. This time when you browse this attribute, you will not find the parent nodes displaying themselves as a child to itself as shown in the below screenshot.
Next Steps
- Check out how many attributes can be configured as a parent attribute in a parent child dimension.
- Use MembersWithDataCaption property to make the system generated data members stand out explicitly to avoid confusion.
- Read these related SSAS tips.






About the author
 Siddharth Mehta is an Associate Manager with Accenture in the Avanade Division focusing on Business Intelligence.
Siddharth Mehta is an Associate Manager with Accenture in the Avanade Division focusing on Business Intelligence.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2011-04-22
