By: Aaron Bertrand | Updated: 2012-03-13 | Comments (8) | Related: 1 | 2 | 3 | 4 | > Database Design
Problem
A lot of people are storing large quantities of e-mail addresses in their systems. As someone who focuses on squeezing every bit of performance out of the various hardware components in a system, when I look at a table full of e-mail addresses, I can't help but think that it is wasteful. Since a large percentage of any system's user base is going to be supplying e-mail addresses from a few of the vastly popular providers (such as GMail and Hotmail), we are storing the "@gmail.com" and "@hotmail.com" parts of those addresses on disk over and over and over again. Further to that it makes it difficult to search efficiently for all users of GMail, for example, since the domain name is not at the beginning of the column and therefore will require a table or index scan. Even if the e-mail address column is indexed, the index is only useful for exact matches or when trying to find all the users like aaron@<anydomain>.
Solution
Earlier in my career, I experimented with various ways to store e-mail addresses that would bypass some of these limitations. Initially we had a table like this:
CREATE TABLE dbo.Contacts_Original
(
EmailAddress VARCHAR(320) PRIMARY KEY
);(For simplicity's sake, let's ignore that there were obviously other columns involved.)
But we quickly came across some of the problems mentioned above - the table grew quite quickly, and certain types of queries started to take unacceptably long times (such as running reports on the activity for Hotmail.com users). At first we tried splitting the e-mail address up, which would at least buy us the ability to index the domain first, which helped certain queries:
CREATE TABLE dbo.Contacts_Split
(
LocalPart VARCHAR(64) NOT NULL,
DomainName VARCHAR(255) NOT NULL,
PRIMARY KEY (DomainName, LocalPart)
);
This solution was very short-lived as well, since we still had a tremendous amount of space being wasted on duplicate domain names (and not all of them were nice and short like gmail.com and hotmail.com). So the logical evolution was to store each domain name *once*, and even though it would need more code for maintenance, we would be better off in the end since we were I/O-bound and always strived to find ways to reduce I/O. So the final version of the schema looked something like this:
CREATE TABLE dbo.EmailDomains
(
DomainID INT IDENTITY(1,1) PRIMARY KEY,
DomainName VARCHAR(255) NOT NULL UNIQUE
);
CREATE TABLE dbo.Contacts_DomainFK
(
DomainID INT NOT NULL FOREIGN KEY
REFERENCES dbo.EmailDomains(DomainID),
LocalPart VARCHAR(64),
PRIMARY KEY (DomainID, LocalPart)
);But aside from the obvious additional complexities in code, how would this new solution perform compared to the previous solutions? I wanted to run it through three tests:
- Inserting 10,000 new e-mail addresses
- Counting the number of addresses in use by a specific domain
- Updating all the addresses for one domain to use a new domain (something like this really did happen)
So first I needed a way to generate 10,000 unique e-mail addresses. There are plenty of ways to generate data; I like to play with the system objects, so I came up with this approach:
;WITH x(n,i,rn) AS
(
SELECT TOP (10000) LOWER(s1.name),
ABS(s2.[object_id] % 10),
ROW_NUMBER() OVER (ORDER BY s1.[object_id])
FROM sys.all_columns AS s1
CROSS JOIN sys.all_objects AS s2
),
y(i, localpart, domain) AS
(
SELECT i, n+RTRIM(rn),
CASE WHEN i < =2 THEN 'gmail.com'
WHEN i <= 4 THEN 'hotmail.com'
WHEN i = 5 THEN 'aol.com'
WHEN i = 6 THEN 'compuserve.net'
WHEN i = 7 THEN 'mci.com'
WHEN i = 8 THEN 'hotmail.co.uk'
ELSE RTRIM(rn) + '.com'
END
FROM x
)
SELECT domain, c = COUNT(*)
FROM y
GROUP BY domain ORDER BY c DESC;I wanted a lot of duplicate domains, but I also wanted a lot of singletons. This query produced 992 rows on my system, favoring gmail and hotmail domains:

And changing the final SELECT to actually build e-mail addresses:
... ) SELECT DISTINCT y.localpart, y.domain, email = y.localpart + '@' + y.domain FROM x INNER JOIN y ON x.i = y.i;
Yields these partial results (10,000 total unique e-mail addresses):

(In spite of appearances, not all e-mail addresses start with 'grantee'.)
So now that we have a way to easily generate 10,000 unique e-mail addresses, let's proceed with our tests.
Creating 10,000 contact rows
In order to test the creation of 10,000 rows, I created a single stored procedure for each table (since this is how contacts were typically generated in our system). Note that I use MERGE for consistency across methods, not for performance, error handling, isolation or concurrency (those are topics for another tip). You'll notice that the stored procedure code gets a little more complex in each case; hopefully that complexity will pay off.
CREATE PROCEDURE dbo.Contact_Create_Original
@EmailAddress VARCHAR(320)
AS
BEGIN
SET NOCOUNT ON;
MERGE INTO dbo.Contacts_Original AS c
USING (SELECT EmailAddress = @EmailAddress) AS p
ON c.EmailAddress = p.EmailAddress
WHEN NOT MATCHED THEN
INSERT (EmailAddress) VALUES(p.EmailAddress);
END
GO
CREATE PROCEDURE dbo.Contact_Create_Split
@LocalPart VARCHAR(64),
@DomainName VARCHAR(255)
AS
BEGIN
SET NOCOUNT ON;
MERGE INTO dbo.Contacts_Split AS c
USING
(
SELECT LocalPart = @LocalPart,
DomainName = @DomainName
) AS p
ON c.LocalPart = p.LocalPart
AND c.DomainName = p.DomainName
WHEN NOT MATCHED THEN
INSERT (LocalPart, DomainName) VALUES(p.LocalPart, p.DomainName);
END
GO
CREATE PROCEDURE dbo.Contact_Create_DomainFK
@LocalPart VARCHAR(64),
@DomainName VARCHAR(255)
AS
BEGIN
SET NOCOUNT ON;
DECLARE @DomainID INT;
SELECT @DomainID = DomainID
FROM dbo.EmailDomains
WHERE DomainName = @DomainName;
IF @DomainID IS NULL
BEGIN
INSERT dbo.EmailDomains(DomainName) SELECT @DomainName;
SELECT @DomainID = SCOPE_IDENTITY();
END
MERGE INTO dbo.Contacts_DomainFK AS c
USING (SELECT DomainID = @DomainID, LocalPart = @LocalPart) AS p
ON c.DomainID = p.DomainID
AND c.LocalPart = p.LocalPart
WHEN NOT MATCHED THEN
INSERT (DomainID, LocalPart) VALUES(p.DomainID, p.LocalPart);
END
GOThen, using the query above, I selected the 10,000 unique e-mail addresses into a #temp table (so I could operate on the same set multiple times):
... ) SELECT DISTINCT EmailAddress = y.localpart + '@' + y.domain, DomainName = y.domain, LocalPart = y.localpart INTO #foo FROM x INNER JOIN y ON x.i = y.i;
Now I could create a cursor for each method and time the run:
DECLARE @EmailAddress VARCHAR(320), @DomainName VARCHAR(255), @LocalPart VARCHAR(64); SELECT SYSDATETIME(); DECLARE c CURSOR LOCAL STATIC FORWARD_ONLY READ_ONLY FOR SELECT EmailAddress, DomainName, LocalPart FROM #foo; OPEN c; FETCH NEXT FROM c INTO @EmailAddress, @DomainName, @LocalPart; WHILE (@@FETCH_STATUS <> -1) BEGIN --EXEC dbo.Contact_Create_Original @EmailAddress = @EmailAddress; --EXEC dbo.Contact_Create_Split @LocalPart = @LocalPart, @DomainName = @DomainName; --EXEC dbo.Contact_Create_DomainFK @LocalPart = @LocalPart, @DomainName = @DomainName; FETCH NEXT FROM c INTO @EmailAddress, @DomainName, @LocalPart; END CLOSE c; DEALLOCATE c; SELECT SYSDATETIME();
Results:
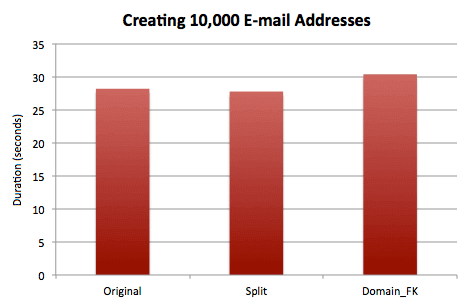
I also wanted to check the disk space usage (and I could do a less complex version of a typical usage query because I know the table is not partitioned, there is no LOB or overflow data, and the only index in each table is the clustered index):
SELECT t.name, data_in_kb = 8 * (p.in_row_data_page_count) FROM sys.tables AS t INNER JOIN sys.dm_db_partition_stats AS p ON t.[object_id] = p.[object_id];
Results:

So when splitting the domains out into a separate table, we have a slight increase in cost when performing inserts, and a marginal savings in disk space (about 10%). In our case the savings were a substantially larger percentage because we were talking about extrapolating millions of addresses, and a larger percentage of those addresses were distributed across a handful of the most popular domains.
Counting contacts from a particular domain
I picked a domain with a lot of contacts (gmail.com) and a domain with one (1010.com), and timed counting each of those 10,000 times:
SELECT SYSDATETIME(); GO DECLARE @c INT; SELECT @c = COUNT(*) FROM dbo.Contacts_Original WHERE EmailAddress LIKE '%@gmail.com'; SELECT @c = COUNT(*) FROM dbo.Contacts_Original WHERE EmailAddress LIKE '%@1010.com'; GO 10000 SELECT SYSDATETIME(); GO DECLARE @c INT; SELECT @c = COUNT(*) FROM dbo.Contacts_Split WHERE DomainName = 'gmail.com'; SELECT @c = COUNT(*) FROM dbo.Contacts_Split WHERE DomainName = '1010.com'; GO 10000 SELECT SYSDATETIME(); GO DECLARE @c INT; SELECT @c = COUNT(*) FROM dbo.Contacts_DomainFK AS c INNER JOIN dbo.EmailDomains AS d ON c.DomainID = d.DomainID WHERE d.DomainName = 'gmail.com'; SELECT @c = COUNT(*) FROM dbo.Contacts_DomainFK AS c INNER JOIN dbo.EmailDomains AS d ON c.DomainID = d.DomainID WHERE d.DomainName = '1010.com'; GO 10000 SELECT SYSDATETIME();
Results:

Because of the JOIN, the inline split method is a little more efficient than breaking the domain out into its own table, but both are far more efficient than searching domain names within a complete e-mail address. Due to our specific needs, we actually solved this problem using an indexed view with DomainID and COUNT_BIG() - opting to pay the cost of that as up-front index maintenance and with a little additional storage (a little over 12 bytes * the number of distinct domains).
Updating all addresses to use a different domain
My last test was not a common use case but it happened more than once - for example when AT&T purchased MCI, they created a new domain name and simply moved all MCI customers over to the new one. Or at least we'll pretend in this case that the transition was that simple. The code to do this is not overly complicated, but for the purposes of producing measurable activity, I'm going to change them forward and back 500 times:
SELECT SYSDATETIME();
GO
UPDATE dbo.Contacts_Original
SET EmailAddress = LEFT(EmailAddress, CHARINDEX('@', EmailAddress))
+ 'att.net' WHERE EmailAddress LIKE '%@mci.com';
UPDATE dbo.Contacts_Original
SET EmailAddress = LEFT(EmailAddress, CHARINDEX('@', EmailAddress))
+ 'mci.com' WHERE EmailAddress LIKE '%@att.net';
GO 500
SELECT SYSDATETIME();
GO
UPDATE dbo.Contacts_Split
SET DomainName = 'att.net' WHERE DomainName = 'mci.com';
UPDATE dbo.Contacts_Split
SET DomainName = 'mci.com' WHERE DomainName = 'att.net';
GO 500
SELECT SYSDATETIME();
GO
UPDATE dbo.EmailDomains
SET DomainName = 'att.net' WHERE DomainName = 'mci.com';
UPDATE dbo.EmailDomains
SET DomainName = 'mci.com' WHERE DomainName = 'att.net';
GO 500
SELECT SYSDATETIME();Results:

It shouldn't be surprising that substring-based string searching and manipulation will be significantly more expensive than wholesale updating and matching. And of course the most efficient outcome would be when only a single value is changed. Even if this isn't going to be a common use case, I lend some weight to the efficiency here because it is the kind of thing that could potentially take your table offline.
Conclusion
As you can see, it can make a difference in your workload by experimenting with various ways to store certain types of data, especially if a lot of your information is repeated or treated independently. You could extend this to think about other information like URLs - if you store a lot of google or bing search result URLs, for example, then you may be storing a whole lot of redundant information by keeping the URL fully intact.
Keep in mind this solution was initially developed in SQL Server 2005. In SQL Server 2008 and above, we would have experimented with Data Compression to hopefully achieve even greater savings. In a future tip, I'll extend this to see how different the impact is when compression is part of the equation.
Next Steps
- Review your current data storage policies.
- Consider alternate ways to store redundant data.
- Review the following tips and other resources:






About the author
 Aaron Bertrand (@AaronBertrand) is a passionate technologist with industry experience dating back to Classic ASP and SQL Server 6.5. He is editor-in-chief of the performance-related blog, SQLPerformance.com, and also blogs at sqlblog.org.
Aaron Bertrand (@AaronBertrand) is a passionate technologist with industry experience dating back to Classic ASP and SQL Server 6.5. He is editor-in-chief of the performance-related blog, SQLPerformance.com, and also blogs at sqlblog.org.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2012-03-13
