By: Tibor Nagy | Updated: 2012-06-21 | Comments (6) | Related: > Performance Tuning
Problem
I heard that outdated statistics can cause SQL performance degradation. I am new to SQL Server and have not experienced this problem yet. Could you please show me an example?
Solution
Test Plan
I will demonstrate the impact of outdated statistics with different Graphical Query Plans and how outdated statistics can affect performance.
We will create a STAT_TEST table in a new database. This table has a few fields with different data types. An integer field (TEST_VALUE) functions as the unique ID for the records.
This is the test scenario:
- Create a test database Demo_DB and enable AUTO UPDATE STATISTICS for the database
- Create the STAT_TEST table and load the STAT_TEST table with 1,500,000 random records
- Disable AUTO UPDATE STATISTICS
- Load the STAT_TEST table with additional 300,000 records and delete the oldest 300,000 records
- Empty the cache using
DBCC DROPCLEANBUFFERS and
DBCC
FREEPROCCACHE
- Display the Estimated Query Plan for a query
- Run the query and check the Actual Query Plan
- Update the statistics
- Empty the cache again
- Display the Estimated Query Plan for the query
- Run the query and check the Actual Query Plan
Preparation
First, we have to create the test database:
CREATE DATABASE [Demo_DB] ON PRIMARY
( NAME = N'Demo_DB', FILENAME = N'G:\MSSQL\DATA\Demo_DB.mdf' , SIZE = 102400KB , FILEGROWTH = 1024KB )
LOG ON
( NAME = N'Demo_DB_log', FILENAME = N'G:\MSSQL\DATA\Demo_DB_log.ldf' , SIZE = 10240KB , FILEGROWTH = 10%)
GO
ALTER DATABASE [Demo_DB] SET AUTO_CREATE_STATISTICS ON
GO
ALTER DATABASE [Demo_DB] SET AUTO_UPDATE_STATISTICS ON
GO
Now we can create the test table and populate with 1.5 million records. Refer to this tip for details on how to populate the database with test data
USE [Demo_DB]
GO
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
CREATE TABLE [dbo].[STAT_TEST1](
[First_Name] [varchar](20) NULL,
[Last_Name] [varchar](20) NULL,
[First_Name_Mother] [varchar](20) NULL,
[Last_Name_Mother] [varchar](20) NULL
)
GO
INSERT INTO STAT_TEST1 VALUES ('John','Anderson','Mary','Jones')
INSERT INTO STAT_TEST1 VALUES ('Homer','Simpson','Martha','Smith')
INSERT INTO STAT_TEST1 VALUES ('Kevin','Bauer','Rachel','Green')
INSERT INTO STAT_TEST1 VALUES ('Matt','Lewis','Kate','Brown')
INSERT INTO STAT_TEST1 VALUES ('John','White','Olivia','Miller')
INSERT INTO STAT_TEST1 VALUES ('Kate','Walker','Julia','Taylor')
INSERT INTO STAT_TEST1 VALUES ('Ray','Kennedy','Juliette','Rock')
INSERT INTO STAT_TEST1 VALUES ('Tom','Jackson','Mary','Johnson')
INSERT INTO STAT_TEST1 VALUES ('Bill','Elliott','Emma','Moore')
INSERT INTO STAT_TEST1 VALUES ('James','Morgan','Emily','Davis')
INSERT INTO STAT_TEST1 VALUES ('Robert','Garcia','Mary','Robinson')
INSERT INTO STAT_TEST1 VALUES ('Bobby','Ewans','Samantha','Ewing')
SELECT top 10* INTO STAT_TEST2
FROM STAT_TEST1 ORDER by 1
SELECT ABS(CHECKSUM(NEWID()))%2 as RandNum1,convert(integer,ABS(CHECKSUM(NEWID()))/100.0) as RandNum2,
STAT_TEST1.[First_Name],STAT_TEST1.[Last_Name],STAT_TEST2.[First_Name_Mother],STAT_TEST2.[Last_Name_Mother]
INTO STAT_TEST FROM STAT_TEST1 CROSS JOIN STAT_TEST2
CREATE CLUSTERED INDEX [MY_INDEX]
ON [dbo].[STAT_TEST] ([RandNum2])
GO
INSERT INTO STAT_TEST
SELECT ABS(CHECKSUM(NEWID()))%2 as RandNum1,convert(integer,ABS(CHECKSUM(NEWID()))/100.0) as RandNum2,
STAT_TEST2.[First_Name],STAT_TEST2.[Last_Name],STAT_TEST1.[First_Name_Mother],STAT_TEST1.[Last_Name_Mother]
FROM STAT_TEST1 CROSS JOIN STAT_TEST2
INSERT INTO STAT_TEST SELECT
ABS(CHECKSUM(NEWID()))%2,convert(integer,ABS(CHECKSUM(NEWID()))/100.0),
S1.[First_Name],S2.[Last_Name],S1.[First_Name_Mother],S2.[Last_Name_Mother]
FROM STAT_TEST S1 CROSS JOIN STAT_TEST S2
GO
INSERT INTO STAT_TEST SELECT TOP 1442160
ABS(CHECKSUM(NEWID()))%2,convert(integer,ABS(CHECKSUM(NEWID()))/100.0),
S2.[First_Name],S1.[Last_Name],S2.[First_Name_Mother],S1.[Last_Name_Mother]
FROM STAT_TEST S1 CROSS JOIN STAT_TEST S2
GO
We are ready to start the tests.
Test with Outdated Statistics
Now we will disable the automatic update of the statistics:
ALTER DATABASE [Demo_DB] SET AUTO_CREATE_STATISTICS OFF
GO
ALTER DATABASE [Demo_DB] SET AUTO_UPDATE_STATISTICS OFF
GO
Let's modify a lot of rows in the database!
INSERT INTO STAT_TEST SELECT TOP 300000
ABS(CHECKSUM(NEWID()))%2,convert(integer,ABS(CHECKSUM(NEWID()))/100.0),
S2.[First_Name],S1.[Last_Name],S2.[First_Name_Mother],S1.[Last_Name_Mother]
FROM STAT_TEST S1 CROSS JOIN STAT_TEST S2
GO
DELETE FROM STAT_TEST WHERE RandNum2 < 4500000
GO
Now we will empty the cache, so we have clean numbers to compare the results:
DBCC DROPCLEANBUFFERS
GO
DBCC FREEPROCCACHE
GO
We will use this simple query for the test:
SELECT * FROM STAT_TEST WHERE RandNum2 > 5000000
You can display the Estimated Execution Plan in SQL Management Studio by pressing CTR + L in the query window. Then you can include the Actual Execution Plan in the results set by pressing CTR + M and then run execute query. Take a look at the estimated plan (left) versus the actual plan (right) and compare the values.
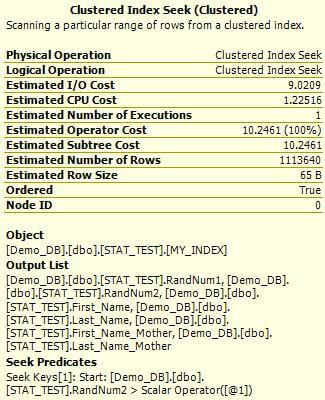
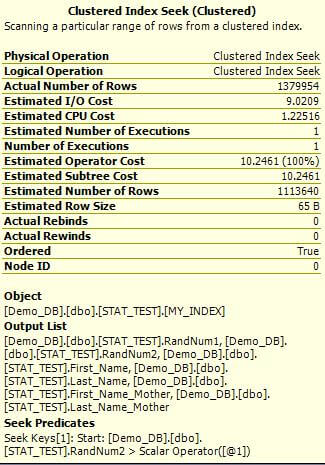
(estimated plan on left and actual plan on right)
When I ran the query, it took 31 seconds and returned 1,379,954 rows. As you can see the difference between the Estimated Number of Rows and the Actual Number of Rows value is 266,314 (1,379,954 - 1,113,640) rows which is more than 19% of the total number of rows returned by the query.
Test with Updated Statistics
To test again, let's enable the automatic update of the statistics, manually update the statistics and clear the cache again:
ALTER DATABASE [Demo_DB] SET AUTO_CREATE_STATISTICS ON
GO
ALTER DATABASE [Demo_DB] SET AUTO_UPDATE_STATISTICS ON
GO
UPDATE STATISTICS STAT_TEST
GO
DBCC DROPCLEANBUFFERS
GO
DBCC FREEPROCCACHE
GO
Now the statistics should be up to date.
Let's go back to our query and check the Estimated Query Plan again. Did the Estimated Execution Plan change? Yes, it changed! It returns 24% higher Estimated I/O Cost and 24% higher Estimated Operator Cost. The Estimated Number of Rows value is also higher, the values is much closer to our actual number of rows.
Now the last step is to execute the query again and check the results. The query run time decreased to 29 seconds (if you remember it was 31 seconds previously). The difference between the Estimated Number of Rows and the Actual Number of Rows value is now only 16 rows. This is much closer than the value we got with the outdated statistics!
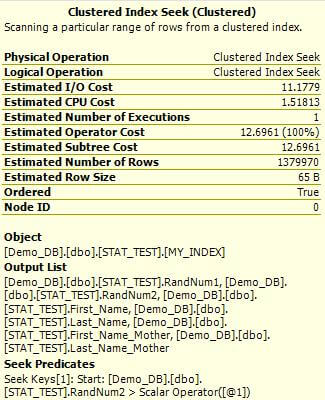
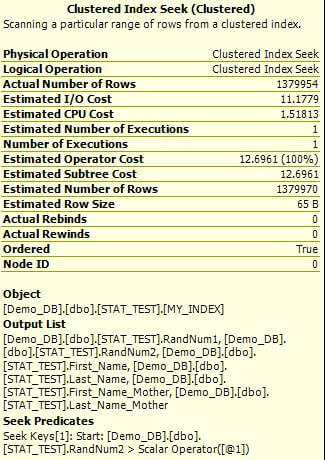
(estimated plan on left and actual plan on right)
Conclusion
So we spotted these differences when the statistics were up-to-date:
- The query plan better estimates the number of returned rows (outdated stats the number was off by 266,314 and when the stats were updated it was off by only 16 rows)
- The estimated I/O, CPU and Operator costs are different
- The query ran faster (31 seconds vs. 29 seconds). This is probably not really a factor for this query since each query run did a Clustered Index Seek when the statistics were out of date and when they were current. For more complex queries this could be a big factor, because updated statistics could generate a totally different execution plan.
If you take into account that this demonstration used a simple query against the clustered index, then you can imagine the impact with more complex queries. The Query Optimizer calculates the estimated cost of the operations based on the statistics and it is possible that it will choose a suboptimal Execution Plan if the statistics are outdated. In such cases you would see differences between the Query Plans with the outdated and updated statistics.
It also worth mentioning that INSERT operations can make statistics quickly outdated
and they trigger automatic updates only after a 20% change threshold is reached.
I think this information is evidence that outdated statistics have a performance cost. I hope you got some insights about statistics in SQL Server and why it is important to keep statistics up to date.
Next Steps
Check out these related tips to learn more about Statistics and Query Plans:
- SQL Server Query Execution Plans in SQL Server Management Studio
- Query Plans category articles
- A strange situation when Automatic Statistics Update Slows Down SQL Server 2005






About the author
 Tibor Nagy is a SQL Server professional in the financial industry with experience in SQL 2000-2012, DB2 and MySQL.
Tibor Nagy is a SQL Server professional in the financial industry with experience in SQL 2000-2012, DB2 and MySQL.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2012-06-21
