By: Ben Snaidero | Updated: 2012-10-30 | Comments | Related: 1 | 2 | 3 | 4 | > SQL Server Agent
Problem
When it comes to managing the history of SQL Server Agent there are two things you want to consider; first, you want to make sure that the table is being purged as you don't want it growing indefinitely and second, there may be occasions when you want to take a look at the last few failures, so you can see if there is some sort of pattern when a job does fail.
This tip will look at a customized method of purging the SQL Server Agent history that addresses both of these issues.
Solution
Built into SQL Server there are two different ways to keep the size of the job history table in check. The first limits the number of records in the job history table and the second purges records from the table based on a specified date. I won't go into any of the details regarding these two methods as there are plenty of tips that discuss these topics.
- Managing SQL Server Agent job history
- Retaining SQL Server job history
- Analyze and correct a large SQL Server msdb database
- Missing SQL Server Agent History
- Analyzing SQL Agent job and job step history
While the above tips address our first issue they do not take into account keeping the last XX number of failed executions for a given sql job. In the past I have found this information can be useful as a given SQL job could fail on the first day of every month for some reason. If a job runs a few times a day or there are a lot of jobs on the server, then the defaults of 100 rows per job and 1000 rows in total in the job history would not be enough to see the pattern.
Before we get into the details of the script we'll have to make sure that we turn off the default behavior in the SQL Server agent properties. We can do this in SQL Server Management Studio by right clicking on "SQL Server Agent" category in Object Explorer and then selecting the "History" page. Once on this page we can uncheck the options as shown below.
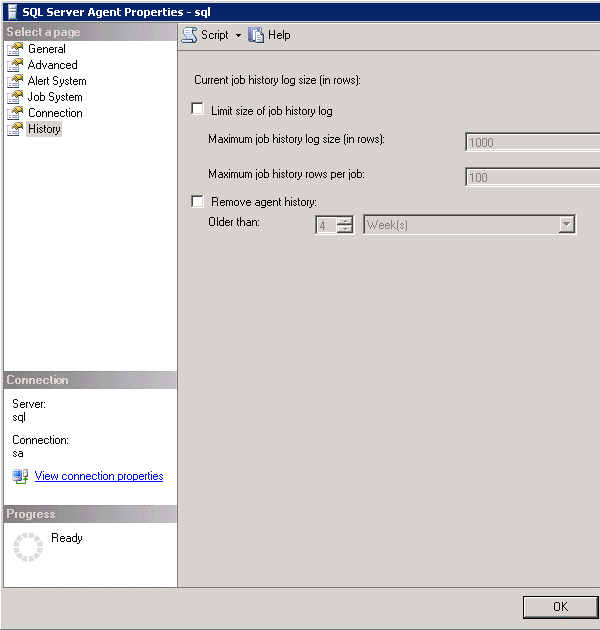
The next decision we have to make is to decide how much data we want to keep. There are no hard and fast rules when it comes to picking values for this but there are a few things you need to make sure you take into account when making this decision.
- Space - Disk space may not be much of an issue for you so in this case you can set these values relatively high
- Number of jobs on the server - If disk space is an issue and you have a lot of jobs setup on your server you may want keep fewer records per job
- Frequency of jobs on the server - Again if disk space is an issue and there are jobs that run on your server at a very high frequency you may also want set these values fairly low
In my experience I have found that keeping the last 30 successful runs and the last 20 failed runs provides enough data to see any trends. I don't have many jobs defined that run more than once per hour so in the majority of my cases 30 successful and 20 failed executions allows me to in the worst case to see approximately one days worth of job executions.
Now let's take a look at the script. At a high level this script gets the instance_id of the 20 most recent failed executions and the 30 most recent successful executions using the RANK() function. We then take this list and use it to generate a complete list of all the instance_ids for the associated jobs steps. Now that we know what records we wish to keep we simply delete everything else from the table. One thing to keep in mind with the design of this query is that we consider a job successful based on the final job status, not the outcome of the individual steps. That is, in the case where a job step fails but the step is configured to go on to some other step in the job and the rest of the job completes as expected then we consider this successful.
DELETE FROM sysjobhistory WHERE instance_id NOT IN
(SELECT final.instance_id FROM sysjobhistory final INNER JOIN
(SELECT instance_id,ranked30.job_id,
(CAST(run_date AS FLOAT)*1000000)+run_time AS starttime,
(CAST(run_date AS FLOAT)*1000000)+run_time+run_duration AS endtime
FROM
(SELECT *,RANK() OVER (PARTITION BY job_id ORDER BY instance_id DESC) AS RowNum
FROM sysjobhistory
WHERE step_id=0 AND run_status = 1) ranked30
INNER JOIN sysjobs sj ON sj.job_id=ranked30.job_id
WHERE RowNum <= 30) top30
ON final.job_id=top30.job_id AND
(CAST(final.run_date AS FLOAT)*1000000)+final.run_time >= top30.starttime AND
(CAST(final.run_date AS FLOAT)*1000000)+final.run_time <= top30.endtime
UNION
SELECT final.instance_id FROM sysjobhistory final INNER JOIN
(SELECT instance_id,ranked20.job_id,
(CAST(run_date AS FLOAT)*1000000)+run_time AS starttime,
(CAST(run_date AS FLOAT)*1000000)+run_time+run_duration AS endtime
FROM
(SELECT *,RANK() OVER (PARTITION BY job_id ORDER BY instance_id DESC) AS RowNum
FROM sysjobhistory
WHERE step_id=0 AND run_status <> 1) ranked20
INNER JOIN sysjobs sj ON sj.job_id=ranked20.job_id
WHERE RowNum <= 20) top20
ON final.job_id=top20.job_id AND
(CAST(final.run_date AS FLOAT)*1000000)+final.run_time >= top20.starttime AND
(CAST(final.run_date AS FLOAT)*1000000)+final.run_time <= top20.endtime)I usually run this script through SQL Server Management Studio the first time so I can monitor its performance. In the case where your msdb is very large you may want to do this as well since if this table has never been purged and the server has been around for a while, the script could end up taking quite some time and grow the transaction log quite a bit. Once you've made it through the initial execution successfully you can use this script to schedule the job to run daily through the SQL Server Agent.
Next Steps
- Investigate purging other tables in the msdb database:
- Configure Multi Server Administration to make it easier to maintain these cleanup jobs across all the servers you manage






About the author
 Ben Snaidero has been a SQL Server and Oracle DBA for over 10 years and focuses on performance tuning.
Ben Snaidero has been a SQL Server and Oracle DBA for over 10 years and focuses on performance tuning.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2012-10-30
