By: Brady Upton | Updated: 2013-09-20 | Comments (14) | Related: More > Integration Services Data Flow Transformations
Problem
I have multiple duplicate records in my SQL Server database. What is a quick and easy way to remove them using SSIS?
Solution
There are multiple ways to remove duplicate records in SQL Server. In this tip, I'll use the SSIS Sort Transformation to remove records and show you how easy it can be.
The SSIS Sort Transformation task is useful when you need to sort data into a certain sort order. You can compare it to the ORDER BY clause in a SELECT statement. Books Online explains it as:
"The Sort transformation sorts input data in ascending or descending order and copies the sorted data to the transformation output. You can apply multiple sorts to an input; each sort is identified by a numeral that determines the sort order. The column with the lowest number is sorted first, the sort column with the second lowest number is sorted next, and so on"
SSIS Sort Task in Action
First, open Visual Studio (or Business Intelligence Dev Studio if you're using pre SQL Server 2012) and create an SSIS project. Next, we can go ahead and make a connection to our database. Right click Connection Managers in Solution Explorer and choose New Connection Manager:
Choose your Connection Manager type. In this example, we'll use OLEDB. Next, configure the Connection Manager to point to your dataset. In this example, I'll use localhost and my Dev database:
Test the connection and click OK. Next, drag a Data Flow task from the SSIS toolbox onto the design screen:

Right click the Data Flow task and choose Edit. You are now inside the data flow task. This is where all the action happens. Drag an OLEDB source task from the SSIS toolbox to the design screen:

Right click the OLEDB task and choose Edit. This screen is where we will define the connection manager we created earlier. Under OLEDB connection manager choose the connection you created. Leave data access mode as Table or view. Change the name of the table or the view to the table that has duplicate data that needs to be removed. In this example, I'll use a table named Teams:

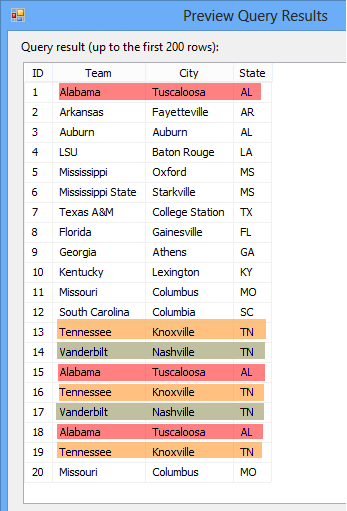
To preview the data click Preview. In my example, you can see I have duplicates in the Team, City and State columns:
Click OK to close the OLEDB Source task. Drag the Sort Transformation task onto the design screen. Connect the OLEDB Source task to the Sort task:

Right click the Sort task and choose Edit. Here is where we can sort our data. Let's say I want to sort my data by State. Under Available Input Columns, I'll choose State:

Click OK. Drag the Derived Column task from the SSIS toolbox onto the design screen. Connect the Sort task to the Derived Column task:

Right click on the precedence constraint between Sort and Derived column and click Enable Date Viewer. This will allow us to view the data as it passes through the constraint:

Let's view our data sorted by State. Click the play button on the toolbar to debug:

Tada! You can see the data has been sorted by State:

Removing Duplicate Rows Using SSIS Sort
But wait....what does this have to do with removing duplicates? Close the Data Viewer and click the stop button on the toolbar to stop debugging. Right click the Sort task again and you'll notice down at the bottom, "Remove rows with duplicate values". I know, I know, you're thinking no way that it's this easy. Click the remove rows option and choose OK:

Click the play button on the toolbar again to view the results. On the design screen, you can see that I passed 20 rows to the sort column but the sort column only passed 11 rows to the next task. This means the transformation removed 9 duplicates based on the column state:

The package worked the way I designed it but I don't want to remove State duplicates. I want to remove Team, City and State duplicates. Back in design view, right click the Sort task and choose Edit. Add Team and City to the input columns and click OK:
Now, click play one more time...
You can now see I have "Distinct" Team, City and State columns:

Next Steps
- To move the new dataset to a location just add a destination task in place of the derived column task.
- View more SSIS Data Flow Transformation tips courtesy of MSSQLTips.com here






About the author
 Brady Upton is a Database Administrator and SharePoint superstar in Nashville, TN.
Brady Upton is a Database Administrator and SharePoint superstar in Nashville, TN.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2013-09-20
