By: Daniel Calbimonte | Updated: 2013-09-12 | Comments (4) | Related: > Analysis Services Measure Groups
Problem
When we create a Multidimensional Database (SSAS), sometimes we need to use the distinct count measure. For example, we need to know the number of users who buy our products. We sometimes have a customer that buys many products, but we need to know the number of unique users. For this scenario, the distinct count measure is very useful. This measure contains very useful information for our reports, but unfortunately it is an expensive resource and if we have many GB or TB of information, it can take a long time to run the queries. This article contains different options to solve the distinct count problem.
Solution
This tip contains three solutions to solve or to improve the query performance for the distinct count measure:
- The new Tabular Model.
- An alternative to the distinct count using an extra dimension
- The Microsoft Recommendations for distinct count measure
Requirements
- Solution 1 requires SQL 2012 or later.
- Solutions 2 and 3 can be used in SQL 2005 or later.
Solution 1 - The new SQL Server Analysis Services Tabular Model
This alternative is valid in SQL Server 2012. The Tabular model is a new database model that is different than the multidimensional model. Tabular models are in memory databases and are in some cases faster than the multidimensional models.
The tabular model was introduced in SQL 2012 and it is easier to learn, build and understand. I am not going to talk about all the advantages of tabular model because it is out of the scope of this tip. However, you can read the next steps links for more information.
The main advantage in the tabular model is that the distinct count queries run faster because of its structure.
The traditional databases use row storage of information and the Tabular model uses column storage of information. That means that if you want to run a query for a single column, the results should be displayed faster. In our distinct count scenario, the tabular model can run faster and it is easier to work with for the distinct count.
The advantages in the tabular model with the distinct count are:
- You do not need to create, process and maintain separate partitions and measures for the distinct count as you do in multidimensional models. The distinct count is treated like any other measure.
- The query time for distinct count queries are faster because of the in column storage.
- Less disk space is required.
The question is: Should I migrate my entire Database from multidimensional model to a tabular model just because of the distinct count?
You should analyze if you want to stay with the multidimensional model and migrate just part of the data required for certain reports. Before migrating to the tabular model, it is strongly recommended to study the tabular model carefully and deploy the tabular model in a testing environment.
For more information about tabular models you can read the following tips:
- Getting started with tabular model in SQL 2012
- New SQL Server Tabular Projects for Analysis Services
Solution 2 - An alternative to the distinct count using an extra dimension in SQL Server Analysis Services
If you do not want to migrate to the tabular model, there is another option. This option was explained by Samuel Vanga in his article Distinct Count in Analysis Services.
The idea is to replace the distinct count with a new dimension.
Example
Let's say that you have a column with users and you want to create a measure with the distinct count of users.
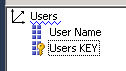
- Instead of creating the measure group, create a dimension with the Users Named Users.

- In this example the dimension will be named user. Add this dimension to the cube.
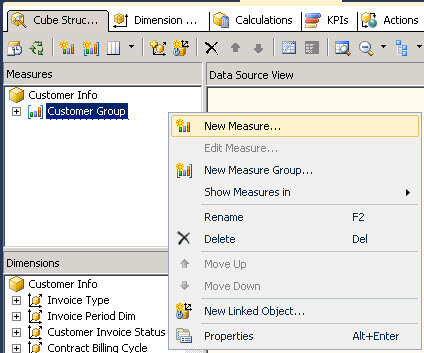
- Add a new measure in the cube structure tab.
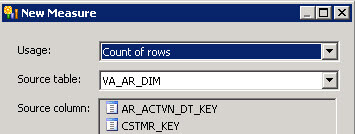
- In the New Measure Windows add a count of rows measure.
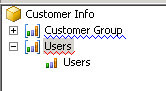
- Rename the measure group and measure to the name that you want.
- Go to the Dimension Usage tab.
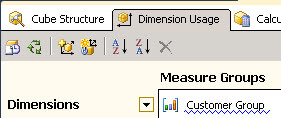
- Add the new Cube Dimension.
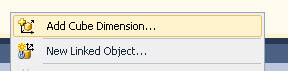
- Select the new created dimension and press OK.
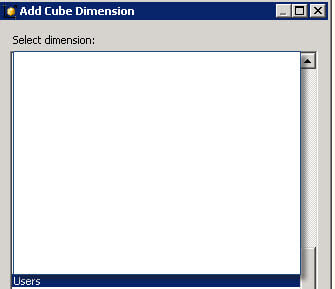
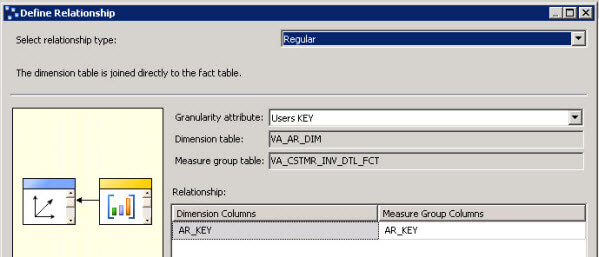
- Click on the relationship button

- In the Define Relationship, select regular and select the Granularity attribute, the dimension columns and the measure group columns.
- Click the second measure group define relationship button.

- Select the relationship type Fact.
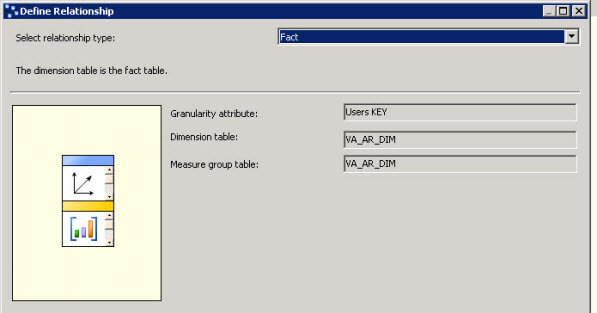
If you want to relate other measures, click the define relationship button.

- In the relationship type, select Many-to-Many and select the Intermediate measure group.
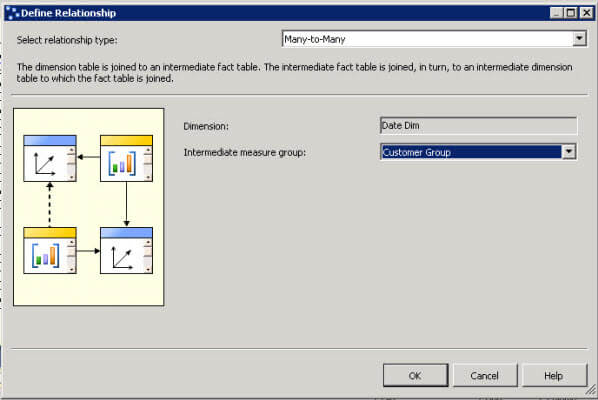
With this tip, you will not need to have multiple partitions for the distinct. You will just need a single extra partition with the new measure.
The queries will run faster and you will need less disk space. You will not need to process multiple partitions for the distinct count because it will be a single one.
Solution 3 - The Microsoft Recommendations for distinct count measure in SQL Server Analysis Services
Microsoft created a special document for the distinct count measure. The document name is: Analysis Services Distinct Count Optimization and you can obtain it from the following url: http://www.microsoft.com/en-us/download/details.aspx?id=891
This document was created for SQL Server 2005, but the document is still valid for SQL Server 2008, 2012 and 2014.
It is a 31 page document. There are instructions to increase the performance of the distinct count in a multidimensional database. The recommendations include the following tips:
- Create customized aggregations. These aggregations will help a lot to improve performance.
- Create partitions from equal size. In these models if you create partitions per day, the number of users will usually increase and the performance will decrease each day. That's why the distinct count is created separately and you need to create partitions with the same number of rows. You can use a hash to distribute the users.
- Use integer keys
- Use partition strategies to distribute the partitions.
Conclusion
So, now you have different options for the distinct count problem in SSAS. Now it is your turn to decide which option best suits your needs.
Next Steps
- For more information, refer to these links:






About the author
 Daniel Calbimonte is a Microsoft SQL Server MVP, Microsoft Certified Trainer and 6-time Microsoft Certified IT Professional. Daniel started his career in 2001 and has worked with SQL Server 6.0 to 2022. Daniel is a DBA as well as specializes in Business Intelligence (SSIS, SSAS, SSRS) technologies.
Daniel Calbimonte is a Microsoft SQL Server MVP, Microsoft Certified Trainer and 6-time Microsoft Certified IT Professional. Daniel started his career in 2001 and has worked with SQL Server 6.0 to 2022. Daniel is a DBA as well as specializes in Business Intelligence (SSIS, SSAS, SSRS) technologies.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2013-09-12
