By: Scott Murray | Updated: 2014-01-28 | Comments (1) | Related: > Analysis Services Dimensions
Problem
What is discretization and how is it used in SQL Server Analysis Services? What are its advantage and disadvantages? Check out this tip to learn more.
Solution
Discretization is a neat tool for assisting SSAS developers especially when dealing with dimension attributes which have a large number of members. Discretization is a derivative of discrete, and basically means creating a discrete set of values based on a continuous group of values. The discretization process allows the developer to take a large set of values and group them in distinct sets with a defined begin and end value. A good example of this situation would be to take a large group of customer names who range from A-Z. The customer list could have, for instance, 20,000 distinct customer names; trying to select from an attribute member list of 20,000 customers could cause performance issues and also be problematic just to select from a list. Using discretization divides the customers into distinct groups by the first letter of the customer's name. Thus we could have groups A-D, E-H, I-P, Q-S, and T-Z. Now the selection list would be more manageable.
For SSAS we can easily set the discretization method property with four possible values: 1) none, 2) automatic, 3) equal areas, or 4) clusters. The automatic method uses either the equal areas or clusters and selects what SSAS considers is the best method. The equal areas method attempts to divide the member list into groups with an equal number of members in each group. Finally, the cluster method uses a defined algorithm, Expectation-Maximization (EM), to divide the members into a set of distribution groups. The cluster method uses a set of sampled data points to iterate through the list of possible values; even so, this method generally will require more processing time. Moreover, the cluster method is only available for numeric columns.
Additionally, if the discretization method is set to any of the three discretization values, the DiscretizationBucketCount value can be set. The DiscretizationBucketCount property defines how many groups you would like the values to be divided into; thus, if the property is set 10, 10 groups will be created. Finally, the attribute groups which are created use a default naming convention for the attribute names; however, a developer can actually change the default naming template to use a broad array of possible alternatives. Of course, the best way to see discretization is by example. For the examples within this tip, we will use the AdventureWorks 2012 MultiDimensional database which can be downloaded on Codeplex at: http://msftdbprodsamples.codeplex.com/releases/view/55330.
SSAS Equal Areas Method for Discretization
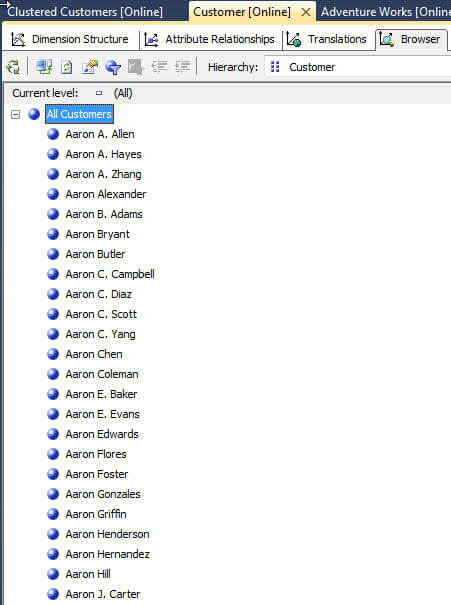
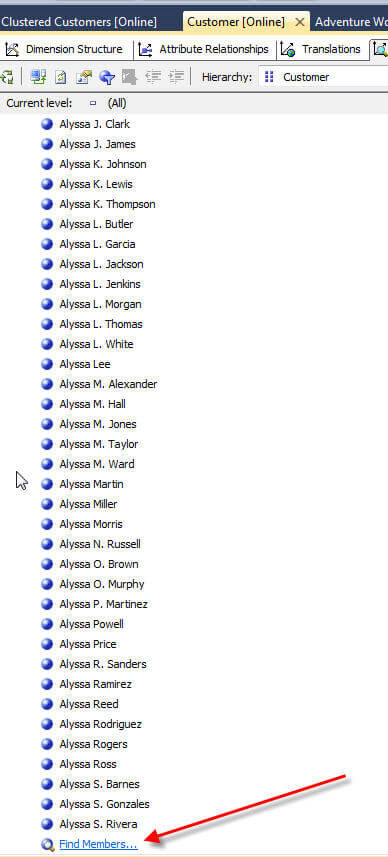
The SQL Server Analysis Services equal areas method for discretization will divide our dimension attribute members into approximately equal groups; a good example within the AdventureWorks SSAS database for using discretization is the Customer dimension, Customer attribute. Take a look at the screen prints below which displays some of the members of the customer list. The list goes on and on even within the A's until the browser finally asks to "find values". Needless to say this list is large; however we can use discretization to temper the list.
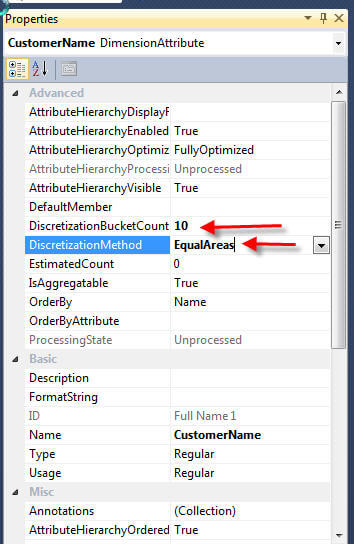
In the below example, we set the discretization method to equal areas and the bucket count to 10.
Now we have a group of 10 buckets. Since the total number of customer names is approximately 18,000, each group includes about 1,800 members. That break out will certainly help navigating the customer names, however, you may be saying where did my detail customer names go? The discretization method actually "takes over" the attribute. In order to drill into the individual customer names, the customer full name field must be added again as a new attribute, as shown below.
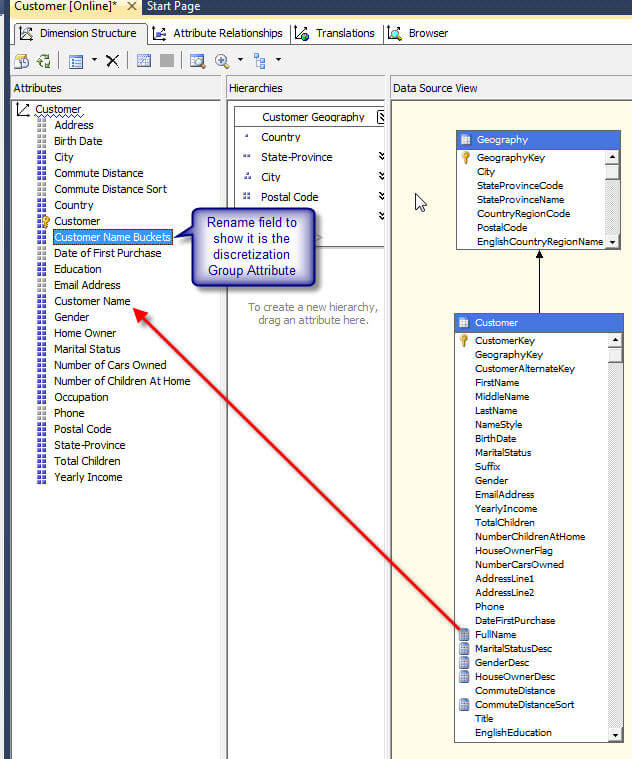
This setup though, only gets us back to our original issue as now we have an attribute that is grouped by customer name and a separate attribute that includes all our customer names. To complete the setup process we need to create a hierarchy with the group attribute at the highest level and then the customer name as the second level. This process is illustrated below; be sure to note that the relationship warning is addressed by creating the direct relationship on the Attribute Relationship tab.
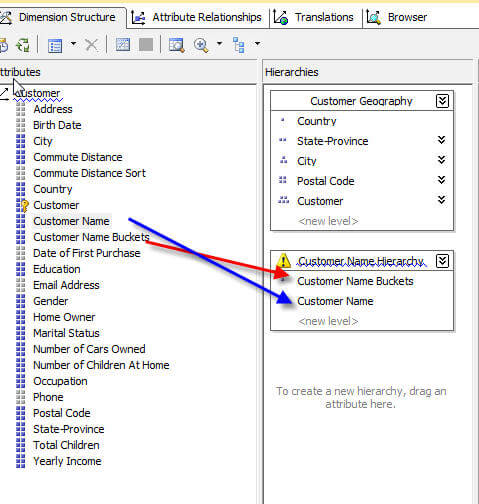
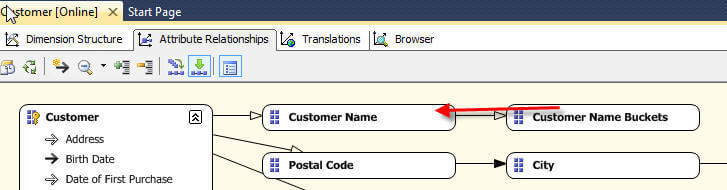
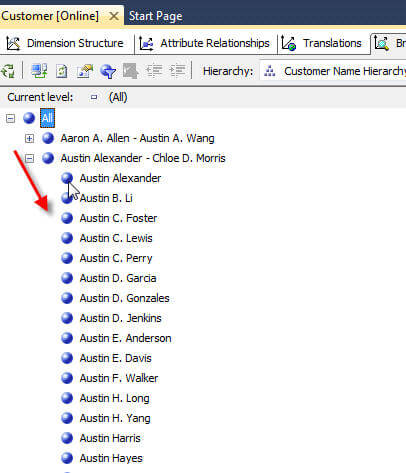
Now we can Browse the hierarchy, first to the "Bucket" groups and then to the individual customer names, as illustrated below.
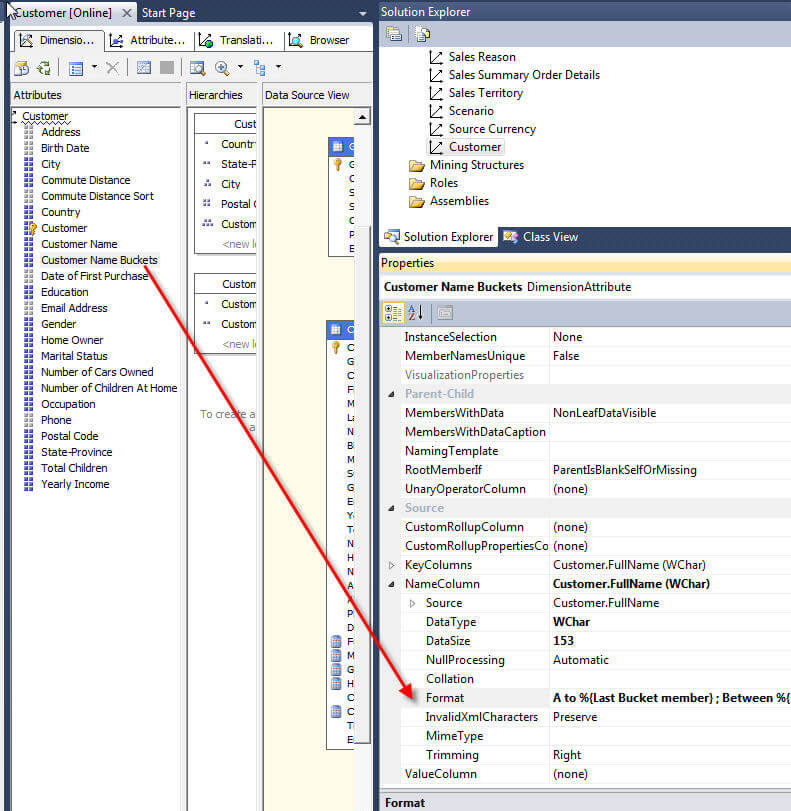
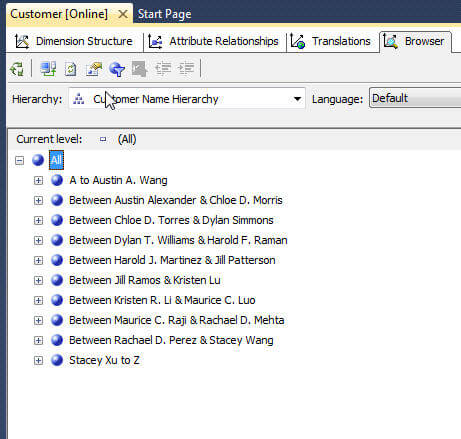
One additional item that we can adjust for the Bucket attribute is the default name used. We have the option of adjusting what actually appears in the "from and to" name used for the groups by adjusting the default naming format. In order to make this adjustment we need to first select the Discretization attribute, Customer Name Buckets in our example. Next, in the properties window, we need to expand the NameColumn properties under the Source Category. Next, in the format property, we can add the following format string: A to %{Last Bucket member} ; Between %{First Bucket member} & %{Last Bucket member} ; %{First Bucket member} to Z. This string tells SSAS to: 1) name the first range "A to whatever the ending name is in the first group" 2) Name all intermediary groups to "Between first name in range & last name in range" and 3) "Initial Name in last group to Z". To see the available values that can be used in the format property, please review the link in the Next Steps section.
The naming format results in the following groupings. Note if the name is actually set from the key by default, the format is actually changed under the KeyColumn properties and not the NameColumn properties (this situation often occurs when the name and key are the same, so the attribute just displays the key).
SSAS Clusters Method for Discretization
The SQL Server Analysis Services cluster method for discretization uses a more advanced methodology to arrange which members belong to which group. Generally if you have a complex distribution of member values, the cluster method may work to your advantage; similarly, the cluster method may, for some implementation, create more "logical" groupings. Since this method can only be used on numeric columns, for this example we will switch to using the Yearly Income attribute. In the below example we set the discretization method to cluster and the bucket count to 10.
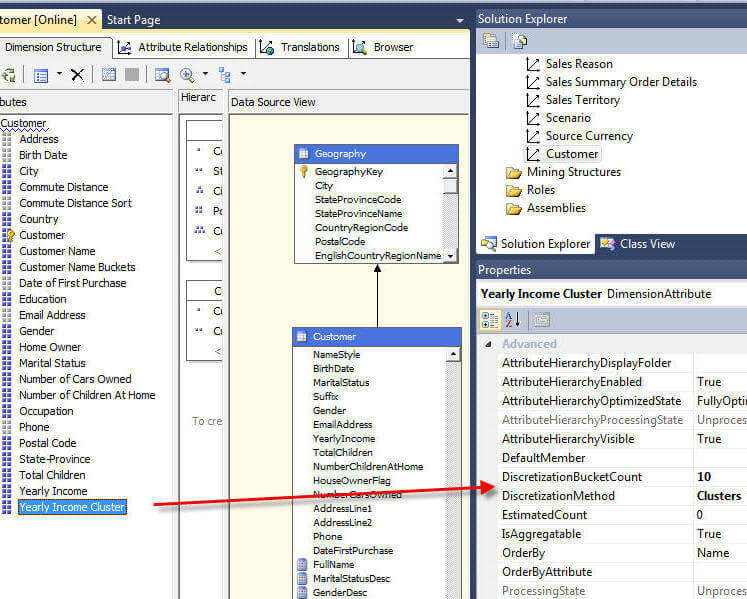
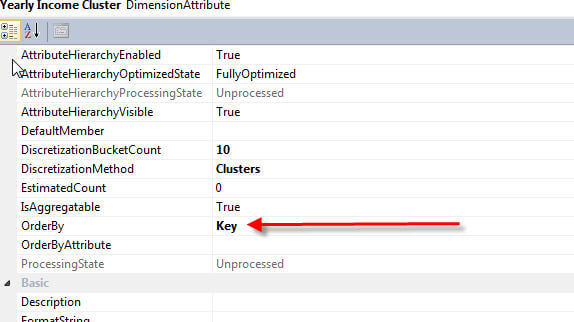
To complete our cluster setup, two additional properties, illustrated subsequently, were adjusted to better reflect the yearly income bucket groups. First to keep the groups in the proper order, the attribute OrderBy property is set to Key. Second, the naming format is adjusted to display a dollar sign in front of the group range names.
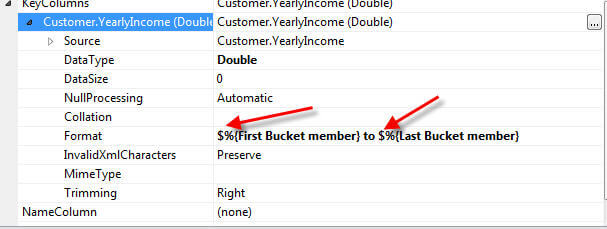
These settings result in the Yearly Income Cluster group displayed next.
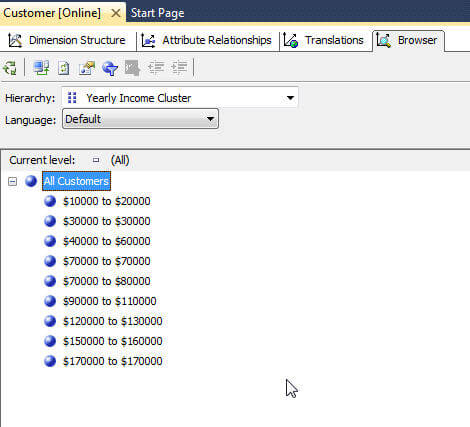
For the income example, the drill down to each income member value would likely not be necessary, so a group to detail hierarchy is not created. Of course, this hierarchy could be created, if needed.
SQL Server Analysis Services Automatic Method for Discretization
The automatic method of discretization selects what SSAS thinks is the best method. The setup process is the same as the other two methods, so I will not show you the complete process. Even so, the below screen print displays the groups which are generated when the Yearly Income cluster attribute is changed from cluster to automatic and the DiscretizationBucketCount property is set to 0. Setting the DiscretizationBucketCount to 0 tells SSAS to determine the most appropriate number of groupings.
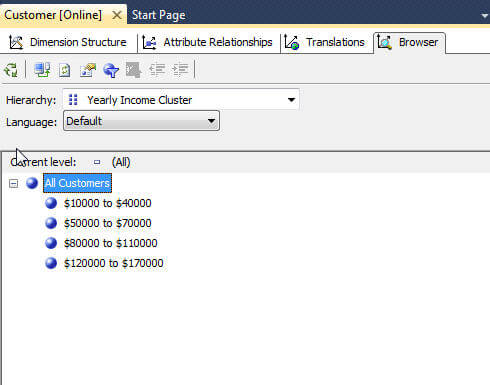
You can see SSAS made the number of groups quite small. At times, it could be best to let SSAS make some of those decisions. However, as new values get added, the grouping could of course change. Notice the $10,000 difference between the first group and the second group. When a $45,000 yearly income value gets added, that group name will change. Furthermore, that change will only take place when the dimension is processed using Process Full, which means your cube will also need to be reprocessed.
Conclusion
SSAS discretization is a useful property for splitting or grouping attributes which contain a large number of values, such as customer names, or have a wide continuous range of values, such as income or property member values. The discretization process can be implemented using the cluster method, the equal areas method, or the automatic method. Additionally, when using one of the methods, the DiscretizationBucketCount field allows us to define the number of groups we would like created. To the contrary, setting the value to 0 tells SSAS to decide the best number of groups. Once our group has been created, the names used for the groups can be adjusted using either the KeyColumn or NameColumn format property element. Finally, for some groups we may want to still see the detail members, but just want to put the members into logical groups to allow for easier selection and viewing. This result can be achieved by adding a second attribute for the detail member and then creating a hierarchy with the discretized attribute at the top level and then the detail member attribute as the next level.
Next Steps
- See Naming Template section of this Technet article for details on the available naming format options- http://technet.microsoft.com/en-us/library/ms174810.aspx






About the author
 Scott Murray has a passion for crafting BI Solutions with SharePoint, SSAS, OLAP and SSRS.
Scott Murray has a passion for crafting BI Solutions with SharePoint, SSAS, OLAP and SSRS.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2014-01-28
