By: Koen Verbeeck | Updated: 2014-03-27 | Comments (3) | Related: More > Integration Services Development
Problem
Advanced analytics, big data, data science; they're all hyped topics nowadays. They're not new however, and one specific subject area has always had some presence in Microsoft's ETL tool: text mining. Integration Services offers two transformations that can help you to do some rudimentary analysis on text: the Term Extraction and the Term Lookup components. This tip will introduce you to the Term Extraction component using a simple use case.
Solution
Before we start, a small but important warning: the Term Extraction and the Term Lookup transformations fall under the Advanced Transforms, which means they are only available in the Enterprise edition. You can still develop a package using these components in BIDS or SSDT(BI), but if you run it on a server with a lower edition, an error will be returned. For more information, check out Features Supported by the Editions of SQL Server 2012.
A simple use case
If we want to do some text mining, we need to have some text available of course. In this tip, I'll use an archive of all my tweets I've downloaded from Twitter. Using this archive I want to find out which topics I particularly tweeted about in the past years or which persons I mentioned the most. The Term Extraction component is perfectly suited for this task. According to its definition on MSDN:
The Term Extraction transformation extracts terms from text in a transformation input column, and then writes the terms to a transformation output column.
...
You can use the Term Extraction transformation to discover the content of a data set.
...
The Term Extraction transformation can extract nouns only, noun phrases only, or both nouns and noun phases.
...
Basically the transformation will parse the text and will extract all the different terms from the input stream. The terms are added to the output, along with a score. Tweets are one example of course, but you can also text mine the emails of your company to discover feedback on your products/services, you could monitor a forum to see what people are discussing lately or if you're really evil, to find out what your kids are talking about. Anyway, I loaded all of my tweets into a SQL Server table, ready to be consumed by SSIS.
Getting Started
Using the Term Extraction component is pretty straight forward. On the control flow I only need a data flow.

The data flow itself is also very simple: a source to read the text, the Term Extraction transformation and a destination to write the results back to the database.
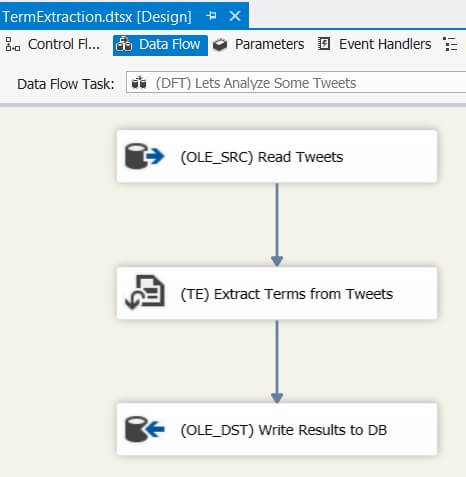
The tweets are read from the source with the following SELECT statement:
SELECT tweets = CONVERT(NVARCHAR(150),[text]) FROM [dbo].[tweets];
The Term Extraction component expects a Unicode input - this means the data flow data types DT_WSTR or DT_NTEXT - so a little conversion is added to the SQL statement. Since tweets are supposed to be shorter than 140 characters, I don't need the text stream data type. If your incoming text exceeds 8000 characters, you need to choose DT_NTEXT.
Let's edit the component itself. You simply need to choose the text column you want to analyze from the available input columns. By default the output columns are conveniently called Term and Score.

When you configure the component and connect it to a destination, you first get a warning telling the error output is not connected. Somehow the default configuration is to redirect error rows.

You can get rid of this warning by connecting the error output of course, or by changing the behavior to Ignore Failure or Fail Component in the Configure Error Output screen in the transformation editor.

The output is connected to an OLE DB Destination which will write the results to a table.
Extracting the Terms
On a fairly decent laptop, the data flow takes less than one second to extract 2,580 terms from 7,241 tweets. Let's take a look at the results.

One of the highest terms is SSIS of course, together with the popular hashtags #sqlserver and some people I regularly have a conversation with. But as you can clearly see, some clutter has made its way in the list. At the top we have co, which comes from t.co, the URL shortener provided by Twitter. We also have RT, the acronym for a retweet, cc for carbon copy and gt, which is more of a data quality issue. gt comes from >, which is used in XML (and HTML) to represent >. When the tweets were downloaded, > and < were left as > and < instead of being converted to their actual character value. The algorithm that extracts the terms got rid of symbols surrounding gt and lt: & and ; were dropped. This leads the one of the biggest flaws when using this transformation to analyze tweets: the hashtag (#) is also dropped. SSIS is at the top, but I cannot determine exactly if I tweeted #SSIS or just SSIS or both. The same goes up for the Twitter handles: @ValentinoV42 becomes ValentinoV42. If a user has a regular word as a Twitter handle, it becomes indistinguishable from that word. @sqlserver is a good example of that problem.
It is pretty easy to get rid of the clutter: you can provide an exclusion list to the transformation. This list contains terms the transformation doesn't have to include in the output. It works similarly as a stop list in SQL Server Full Text indexes. By quickly scanning through the first results of terms, the following list has been created:

To add the exclusion list to the transformation, open up the editor and go to the Exclusion tab, select the checkbox and fill in the details in the dropdown menus. The list has to be accessible from an OLE DB connection.
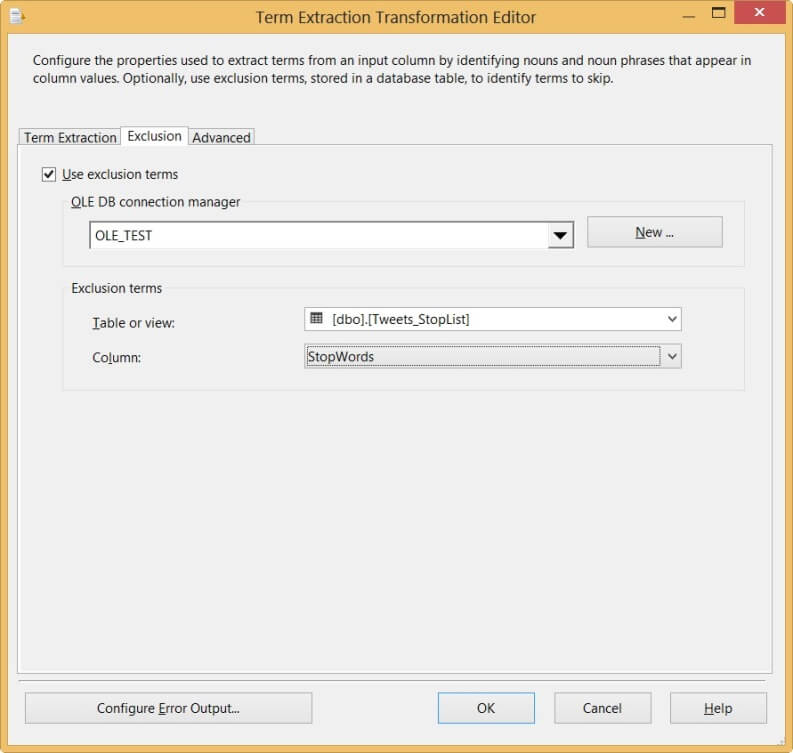
When we run the package again, we receive the following results:

SSIS is now number 1 at the list, as it should be. Let's take a look at the advanced options of the transformation, which we can find in the Advanced pane of the editor.
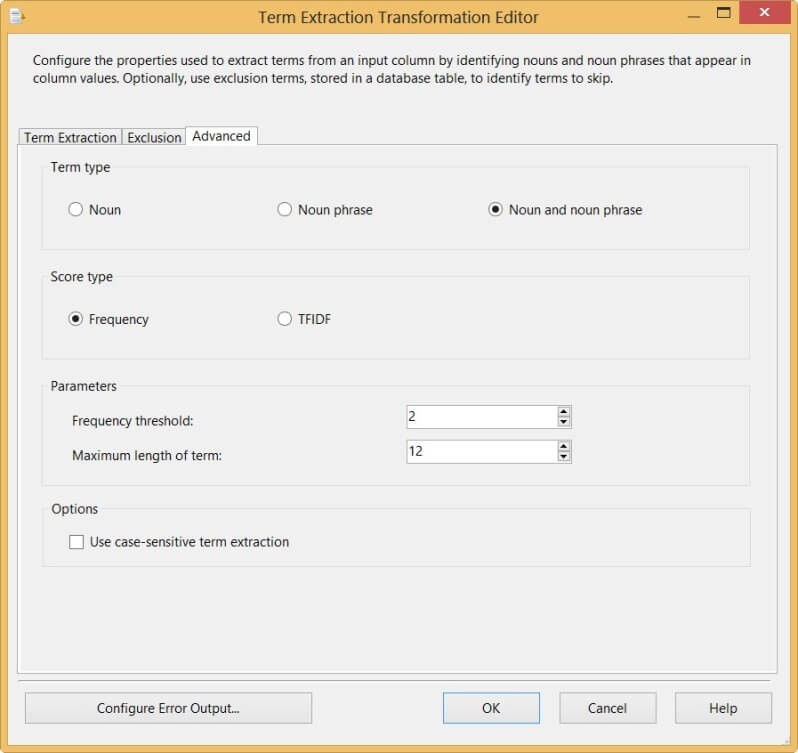
First of all we can change the type of terms:
- Only nouns
- Noun phrases (combination of nouns)
- Nouns and noun phrases
We can also change how the score is calculated:
- Frequency, which is a simple count of how many times a term occurred in the text.
- TFIDF, which stands for Term Frequency and Inverse Document Frequency. For a term T, TDIDF = (frequency of T) * log(#rows in input) / (#rows having T).
Other options are the frequency threshold - the minimum amount of times a term has to appear in the text before it is added to the output - and the maximum length of a term. This last option can be important if a term can exist of several nouns. If you would configure the maximum length to 9, SQL Server would not be extracted as a single term, but as two separate terms. Finally the case sensitivity can be configured.
Remarks
Although the term extraction transformation performed really well on a small data set (about 7000 tweets), the transformation has problems scaling. The component is a blocking transformation, meaning all rows from the input have to be read before one single row can be added to the output. This can have some serious impact on memory usage. If the data set is too large to be processed efficiently, you could try to split up the text in smaller chunks and run the term extraction on each separate part. This only works though if you're using the frequency as the score, as the FTIDF needs to be calculated over the entire text for accurate results.
Another issue is the character of the term extraction component: it behaves like a black box. You have no control whatsoever on how to algorithm selects the different nouns, what is discarded and how phrases are formed. The only (limited) amount of control you have is the exclusion list, the type of terms and the type of score. MSDN explicitly mentions:
The tagging of parts of speech is based on a statistical model and the tagging may not be completely accurate.
Keeping this connect issue in mind, it doesn't seem there is any improvement soon on this area. It would be nice to have more influence, for example choosing to keep Twitter handles and hash tags intact instead of discarding the @ and the #.
Conclusion
Although the transformation has its flaws, it's very easy to get a quick idea on the different terms that are used in a text using this transformation. You could use for example this component to find all the different terms used in blog posts to construct a word cloud. For more advanced text analytics, such as semantic analysis, you need to look for alternatives.
Next Steps
- For more information on how the transformation extracts the terms - and what is discarded - the MSDN documentation gives a nice overview.
- Chris Webb gives a very nice alternative using Power Query and Shakespeare. The Term Extraction component outperforms Power Query though.






About the author
 Koen Verbeeck is a seasoned business intelligence consultant at AE. He has over a decade of experience with the Microsoft Data Platform in numerous industries. He holds several certifications and is a prolific writer contributing content about SSIS, ADF, SSAS, SSRS, MDS, Power BI, Snowflake and Azure services. He has spoken at PASS, SQLBits, dataMinds Connect and delivers webinars on MSSQLTips.com. Koen has been awarded the Microsoft MVP data platform award for many years.
Koen Verbeeck is a seasoned business intelligence consultant at AE. He has over a decade of experience with the Microsoft Data Platform in numerous industries. He holds several certifications and is a prolific writer contributing content about SSIS, ADF, SSAS, SSRS, MDS, Power BI, Snowflake and Azure services. He has spoken at PASS, SQLBits, dataMinds Connect and delivers webinars on MSSQLTips.com. Koen has been awarded the Microsoft MVP data platform award for many years.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2014-03-27
