By: Scott Murray | Updated: 2014-06-27 | Comments (15) | Related: > Analysis Services Dimensions
Problem
What is the difference between the KeyColumn, the NameColumn, and the ValueColumn for a dimension attribute in SQL Server Analysis Services? How do they affect the data presented to the end user? When should you use the KeyColumn, the NameColumn, and the ValueColumn for a dimension attribute? Check out this tip to learn more.
Solution
It would seem that both the NameColumn and the KeyColumn should be one in the same; however each serves a specific and distinct purpose. At its most basic level the NameColumn field is what appears to end users in reports and spreadsheets. To the contrary, the KeyColumn field may or may not be seen by end users and is what attaches the dimension attributes to the dimension key and ultimately the fact table. The KeyColumn field can actually be made up of a composite key (a composite key is a key made up of more than one field); sometimes a composite key is required as some hierarchies require a composite key in order to display correctly and not error during processing. Likewise the ValueColumn allows the NameColumn to display a "friendly" version of the member attribute, but for actual use in filtering, for example, a different value is used. A good example of this situation is the NameColumn for the date attribute. This value can be set to a friendly name such as "May, 2, 2015" which is a string, but the ValueColumn can be set to use the date field and utilize the benefits of a date field for filtering purposes. We will show several examples of these scenarios later in the tip.
We will use the AdventureWorks 2012 Multidimensional SQL Server and Analysis Services databases for our examples. These databases are available on CodePlex at: http://msftdbprodsamples.codeplex.com/releases/view/55330. Once you have the SQL Server and OLAP databases installed, you will start SQL Server Data Tools (SSDT); SSDT is the new name for Business Intelligence Development Studio in SQL Server 2012.
Key, Name, Value Properties
All three of the column properties are filled in on the attribute properties window as shown below. It should be mentioned that these fields actually work in a hierarchy of application. The KeyColumn field must be populated and is actually automatically filled in when the attribute is placed on the dimension. If no NameColumn is specified than the KeyColumn is displayed to the end user. Secondly, if a NameColumn is filled in, but no ValueColumn is populated then the ValueColumn defaults to the field from the NameColumn. Of course all three can be different, or two can be the same and the other can be different. Furthermore, if a composite KeyColumn is used (multiple values linked to the key), then the name column must be filled in.
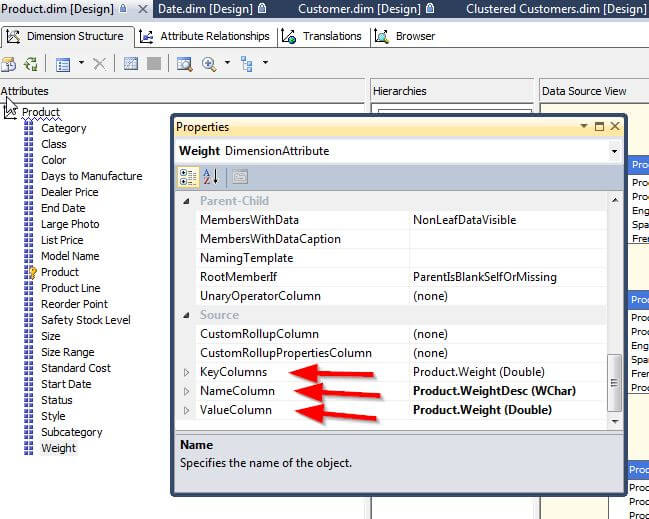
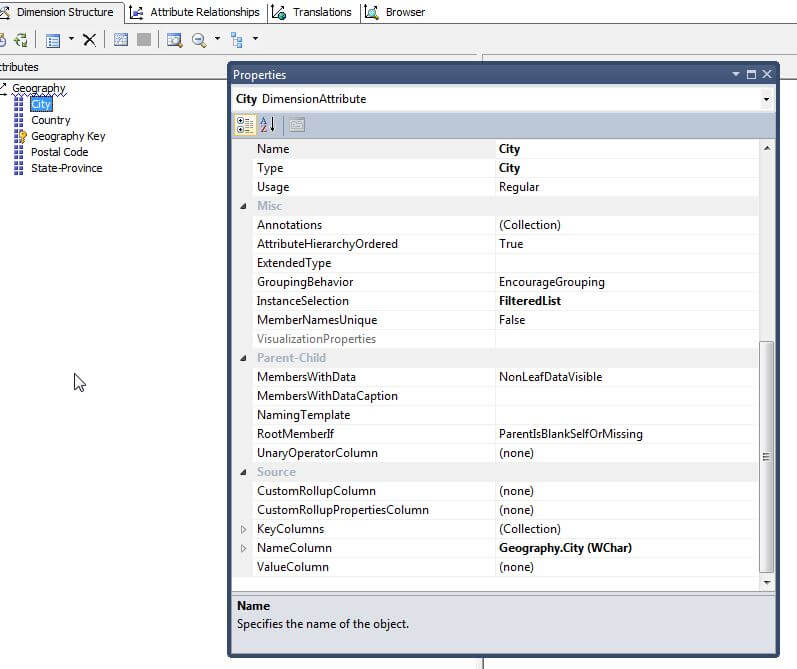
For our first example, let us show where we need to use a composite key which necessitates the need for a NameColumn value. One of the better examples of this situation is a city name. Of course the same city name can be found within different states, providences or regions within a country. That situation is ok until a hierarchy, as shown below, is created which leads to a situation where two cities belonging to a different state-providence that have the same name.
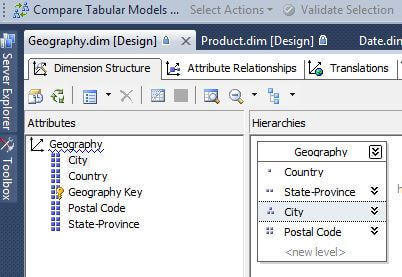
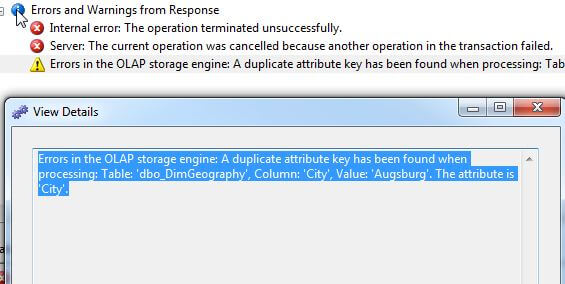
This condition will lead to errors when the dimension or cube is
processed. At
this point if the cube is processed, a duplicate attribute error,
shown below, is returned when attempting to process the dimension.
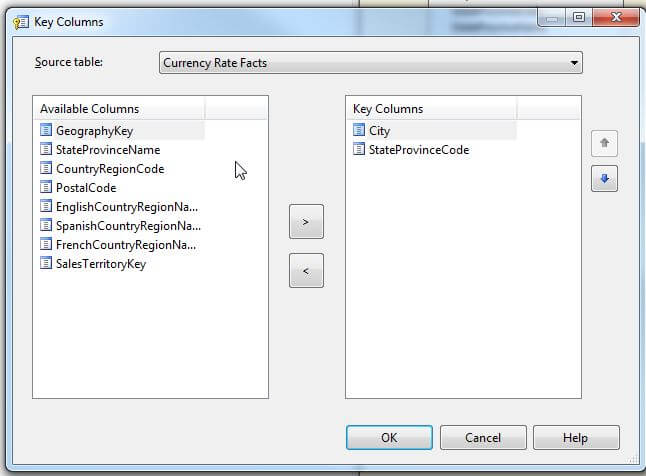
The fix for this particular problem is pretty straight forward in that we actually need to define the key for the city field to actually be a collection made up of the City and the State-Providence, as displayed next.
Now that we defined the composite key, we must define a NameColumn as shown in the screen shot below.
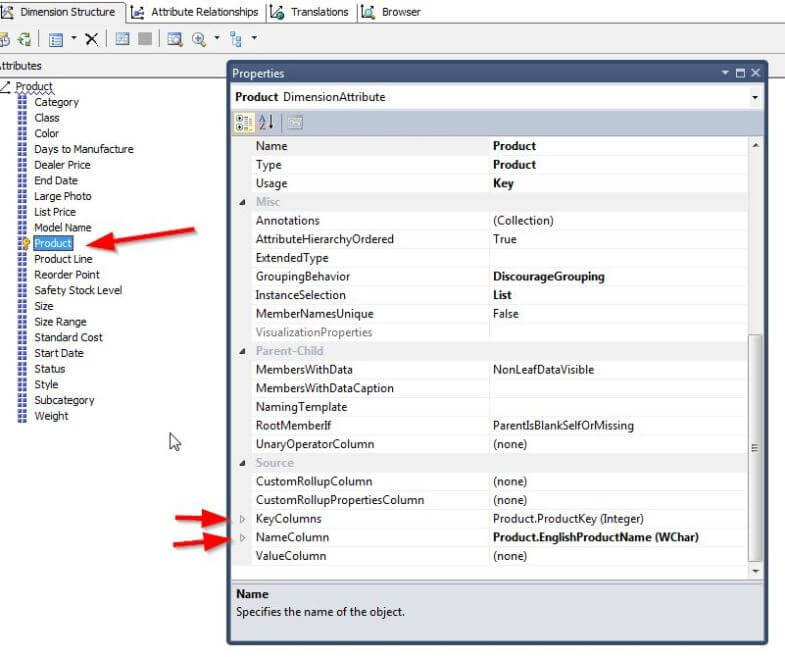
Of course it is not a requirement that a composite key be defined before utilizing a distinct NameColumn. Another common use for this situation is in the Product dimension of AdventureWorks. The main key for the Product Dimension is the Product Attribute which is an integer field. Although that attribute as a number may be helpful, more often than not, you will want to return a "friendly" name to the end user, and thus the Productname field is used to display the name field opposed to the product number. This setup is shown below.
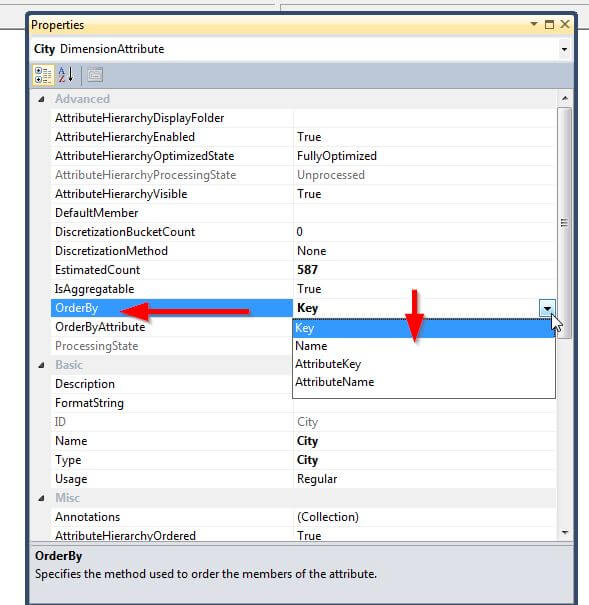
The NameColumn and KeyColumn field can also be used specifically to set the Orderby property for the attribute. Dates are a
perfect example; if you use the date name field, which is a string, then the April dates
will come first. To get around this issue, we can use the key field in
the OrderBy property, shown next, to have the dates appear in the
correct order. For more details on using the Order by function, please see Koen Verbeeck's
tip on Sorting a dimension attribute by another dimension attribute in SQL Server Analysis Services.
The date attribute is a perfect transition for the use of the ValueName field. The ValueColumn field allows us to still display a "user friendly" label while at the same time providing details to the client application instructing it to implement any special filter functionality. In the date example, additional predefined filters, such as "This Year" or "Last Year" are available when the field is defined as a date. However, if NameColumn is defined as a string, which is most common, these filters will be absent. However, we can define the ValueColumn as a date field, which in turns tells the application to use the special filters. The below screen shot shows how the date field looks when attempting to filter on the date field without the ValueColumn populated.
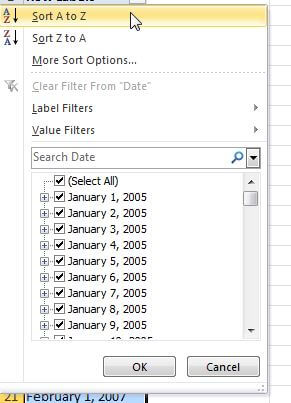
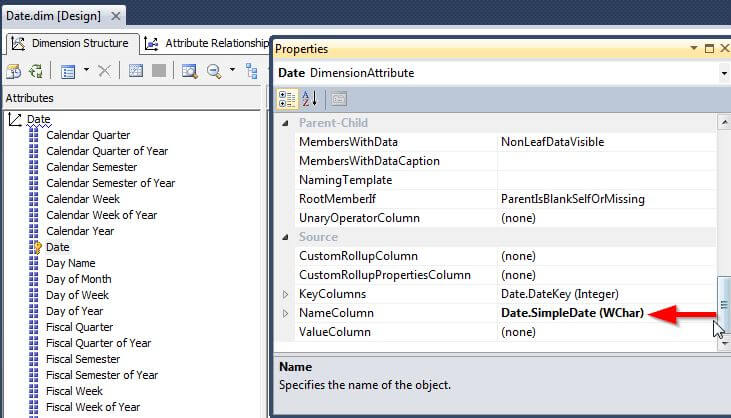
Now let us change the ValueColumn to use the date field as displayed in the following illustration.
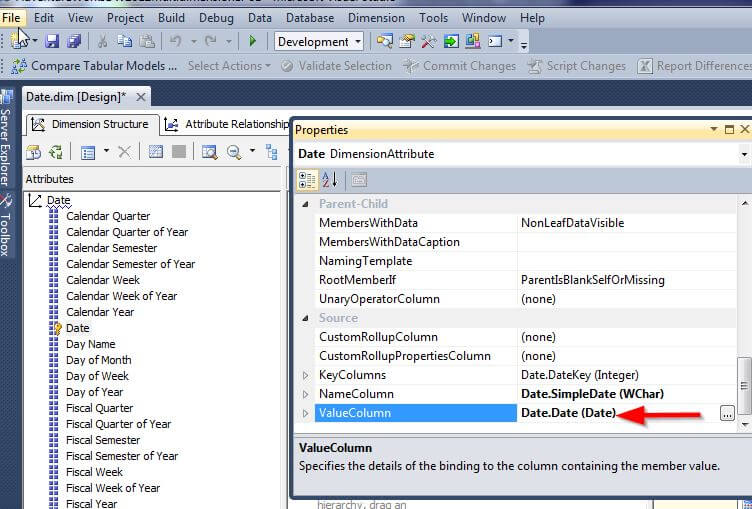
Now when we explore the filters for the date field, as illustrated next, the date filter functionality is now available based on the ValueColumn setting.
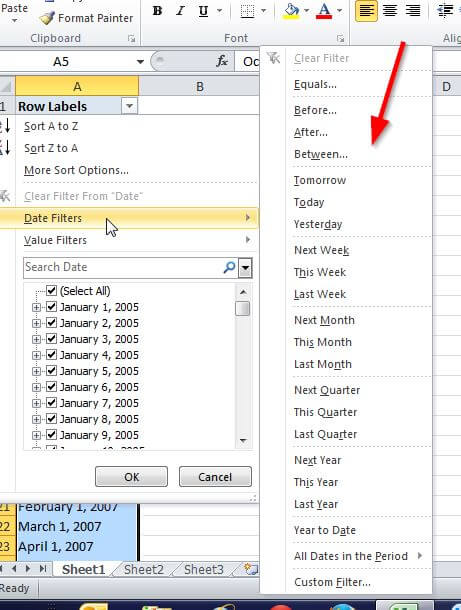
Conclusion
Within a dimension, each attribute has three column properties which greatly impact the various settings that are displayed to the end user application. The KeyColumn controls how the attribute is joined back to the dimension key. The NameColumn is the actual text displayed to the user. Both of these values can be used to control the default ordering sent to the client. Furthermore, the ValueColumn is used to control how the attribute interacts with the client used to display the data, for instance special data filters.
Next Steps
- Check out these resources:






About the author
 Scott Murray has a passion for crafting BI Solutions with SharePoint, SSAS, OLAP and SSRS.
Scott Murray has a passion for crafting BI Solutions with SharePoint, SSAS, OLAP and SSRS.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2014-06-27
