By: Robert Biddle | Updated: 2014-07-30 | Comments (23) | Related: More > Integration Services Development
Problem
You want to reduce the load time of your SSIS packages, but you found that the source of the problem is that you are doing full comparisons between your source system and your destination. Perhaps you've come to find that your source system has been difficult for you to detect when data changes have occurred.
Solution
SQL Server includes an internal mechanism that detects when there are changes to a row. In SQL Server 2005, the rowversion data type was added to essentially replace the timestamp data type. This data type is read-only and automatically populated by SQL Server much in the same way an identity value is handled.
The value stored for rowversion is a hexadecimal value and is essentially a binary(8). Whenever there is an insert or update to a table with a rowversion column, the rowversion value will automatically increment. By querying this value, we can select rows that have changed and create processes that incrementally extract data.
One of the great things about rowversion is that it exists in all versions of SQL Server, unlike Change Data Capture which exists only in Enterprise Edition.
SQL Server Timestamp Data Type
If you check the documentation for the rowversion type, you'll find a note in Books Online that mentions that the timestamp syntax is deprecated.
However, you may find that when you add a rowversion column to a table that a column of timestamp data type has been created. This is because timestamp is the synonym for rowversion.
The following is from Books Online (http://technet.microsoft.com/en-us/library/ms182776(v=sql.110).aspx:
"timestamp is the synonym for the rowversion data type and is subject to the behavior of data type synonyms. In DDL statements, use rowversion instead of timestamp wherever possible."
Adding a Rowversion to a SQL Server Table
Here's an example of a table with a Rowversion column.
CREATE TABLE [dbo].[RowVersionDemo]( [DemoID] [int] IDENTITY(1,1) NOT NULL, [FirstName] [varchar](50) NULL, [LastName] [varchar](50) NULL, [Address1] [varchar](50) NULL, [City] [varchar](50) NULL, [Region] [varchar](50) NULL, [PostalCode] [varchar](20) NULL, [VersionStamp] [rowversion] NOT NULL, CONSTRAINT [PK_RowVersionDemo] PRIMARY KEY CLUSTERED ([DemoID] ASC) ) ON [PRIMARY]
I typically call my rowversion column VersionStamp. I don't like to use SQL keywords for column names so this works out quite well. You can, however, name it anything. I've seen many places actually simply name it "rowversion".
For existing tables, you can simply use the following syntax:
alter table <tablename> add VersionStamp rowversion;
This can take quite a bit of time to run on larger tables, however, and it might be a good idea to schedule a maintenance window in production systems.
Using Rowversion for SQL Server ETL
One of the more useful cases for rowversion is ETL. We can utilize the rowversion values in order to do incremental extracts.
The first thing we will want to do in this case is to define an upper bound. SQL Server has two built-in objects that are used to help with determining the max row version. They are @@dbts and min_active_rowversion().
In general, it can be safely said that you should almost always use min_active_rowversion. If you look up min_active_rowversion on Books Online, then you will find an example that demonstrates the difference between @@dbts and min_active_rowversion.
In your ETL process, you'll want to store the min_active_rowversion in a utility table. Then, the next time your process runs, you will extract any data greater than that value.
The Process
In this particular demonstration, we are going to follow these steps:- Get the Last Successfully Extracted Rowversion (LSERV).
- Get the current rowversion in the database with min_active_rowversion.
- Extract records with a rowversion value greater than LSERV (incremental extract).
- Load the extracted records to a staging table.
- Insert into destination from staging where records do not exist in the destination.
- Update records in the destination from staging where records do exist in both.
- Update the LSERV value with min_active_rowversion.
Staging is a completely optional process for this. It is a recommended approach, however, for performance reasons. Staging many updates to a table and running an update with a join is often much faster than using SSIS's OLE DB Command transformation.
Database Setup
Before creating the SSIS package for this demo, we will need to create some tables.
We will need the following:
- A source table populated with some sample records.
- A utility table that stores the last rowversion we used in our extraction.
- A destination table that stores the output of our ETL process.
- A staging table that is used for updates in our ETL process.
Here's the source table:
CREATE TABLE [dbo].[RowVersionDemo]( [DemoID] [int] IDENTITY(1,1) NOT NULL, [FirstName] [varchar](50) NULL, [LastName] [varchar](50) NULL, [Address1] [varchar](50) NULL, [City] [varchar](50) NULL, [Region] [varchar](50) NULL, [PostalCode] [varchar](20) NULL, [VersionStamp] [rowversion] NOT NULL, CONSTRAINT [PK_RowVersionDemo] PRIMARY KEY CLUSTERED ([DemoID] ASC) ) ON [PRIMARY]
And some insert statements to populate it with some sample data:
insert dbo.RowVersionDemo (FirstName,LastName,Address1,City,Region,PostalCode)
values ('Debra','Shields','P.O. Box 458, 8841 Arcu St.','Newcastle','NS','72745');
insert dbo.RowVersionDemo (FirstName,LastName,Address1,City,Region,PostalCode)
values ('Grace','Ewing','243 Non, St.','Orlando','NW','33894-145');
insert dbo.RowVersionDemo (FirstName,LastName,Address1,City,Region,PostalCode)
values ('Rhoda','Kerr','P.O. Box 128, 751 Cursus, Street','Oklahoma City','OK','88991');
insert dbo.RowVersionDemo (FirstName,LastName,Address1,City,Region,PostalCode)
values ('Evan','Harris','Ap #168-9244 Mauris Rd.','Taupo','NI','62784');
insert dbo.RowVersionDemo (FirstName,LastName,Address1,City,Region,PostalCode)
values ('Clinton','Gates','Ap #788-801 Mauris. Rd.','Acquedolci','Sicilia','4557');
Here's the utility table:
create table dbo.ETLRowversions ( RowversionID int not null identity(1,1), SchemaName nvarchar(128), TableName nvarchar(128), VersionStamp varchar(50), constraint PK_ETLRowversions primary key clustered (RowversionID) );
Insert a record that will be used to hold our rowversion value.
insert dbo.ETLRowVersions (SchemaName,TableName) values ('dbo','RowVersionDemo');
Here's the destination table:
create table dbo.RowversionExport ( DemoKey int not null identity(1,1), DemoID int not null, FirstName varchar(50), LastName varchar(50), Address1 varchar(50), City varchar(50), Region varchar(50), PostalCode varchar(20), VersionStamp binary(8), constraint PK_RowversionExport primary key clustered(DemoKey) );
Notice I set the VersionStamp data type to binary(8) instead of rowversion. This is because rowversion is read-only and we would not be able to copy the source rowversion value to the destination table.
Lastly, here's the staging table:
create table dbo.Stage_RowversionExport ( DemoID int not null, FirstName varchar(50), LastName varchar(50), Address1 varchar(50), City varchar(50), Region varchar(50), PostalCode varchar(20), VersionStamp binary(8) ); create nonclustered index Stage_RowversionExport_Idx on dbo.Stage_RowversionExport(DemoID);
Now that we have the tables in place, we can build the SSIS package.
SSIS Demo with RowVersion
In this demo, we will create an SSIS package that extracts data from our source table and stores it in a destination table. The process will use rowversion to do incremental extractions. This means that the next time the package runs, it will only extract data that has changed.Initial Setup
- Make sure you've completed the Database Setup steps first.
- Create a new SSIS package.
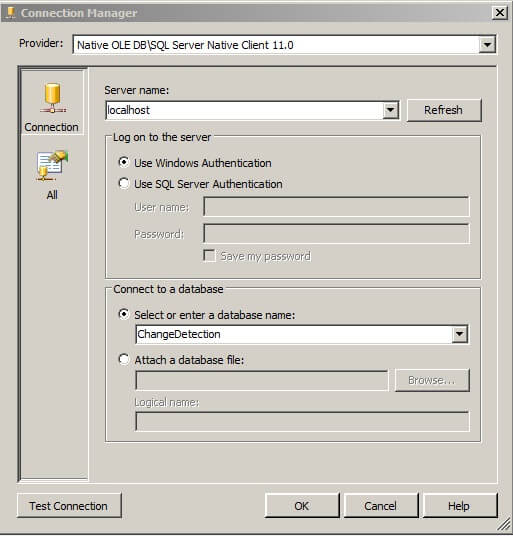
- Create a Connection for your database in the Connection Manager.
Get the Max Rowversion
In SSIS development, I often set a default value for variables.
- Drag an Execute SQL Task control onto the Control Flow. Rename the task as Get MaxRV.
- Open the Execute SQL Task.
- Set the Connection to your database connection you created.
Set the SQLStatement to:
select ? = CONVERT(varchar(50),min_active_rowversion(),1)
Since 2008, the CONVERT function very conveniently handles conversion between binary and string types.
Click the Parameter Mapping page inside the Execute SQL Task Editor.
- Click Add.
- Change the Variable Name to User::MaxRV.
- Change the Direction to Output.
- Change the Data Type to VARCHAR.
- Change the Parameter Name to 0.

Click OK.
Get the Last Rowversion
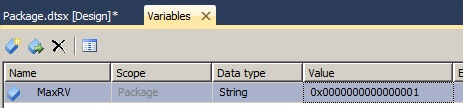
- Create a variable in your SSIS package called LSERV.
- (LSERV = Last Successfully Extracted Row Version).
- Data Type is String
- Value is 0x0000000000000001
- Drag another Execute SQL Task control onto the Control Flow.
- Rename the task as Get LSERV.
- Open the Execute SQL Task.
- Set the Connection to your database connection you created.
Set the SQLStatement to:
Select ? = isnull(VersionStamp,'0x0000000000000001') from dbo.ETLRowversions where SchemaName = 'dbo' and TableName = 'RowVersionDemo'
Click the Parameter Mapping page inside the Execute SQL Task Editor.
- Click Add.
- Change the Variable Name to User::LSERV.
- Change the Direction to Output.
- Change the Data Type to VARCHAR.
- Change the Parameter Name to 0.

Click OK.
Connect Get MaxRV and Get LSERV tasks together.
Extracting the Data
Now we will query our table. I will use the sample table and 5 records from above for this demo.
SSIS has trouble handling binary parameters. Because of this, we need to generate an expression for our SQL statement to be used for our data extraction.
- Create a variable in your SSIS package called SQLStatement.
- Data Type is String.
- Click the ellipsis next to the Expression column.
Use the following Expression:
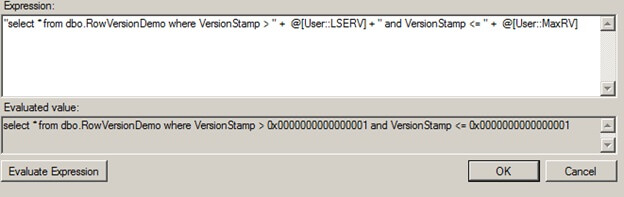
"select * from dbo.RowVersionDemo where VersionStamp > " + @[User::LSERV] + " and VersionStamp <= " + @[User::MaxRV]
After clicking the Evaluate Expression button, you'll see the following:
Click OK.
Drag a Data Flow Task onto the Control Flow. Connect Get LSERV to the Data Flow Task.
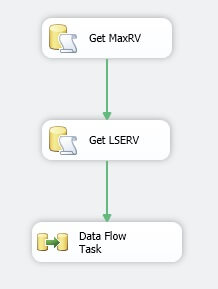
- Open the Data Flow Task. This will take you to a different tab.
- Drag OLE DB Source to the Data Flow Task canvas.
- Edit the OLE DB Source.
- Change the Data access mode to SQL command from variable.
- In the Variable name dropdown, choose User::SQLStatement.
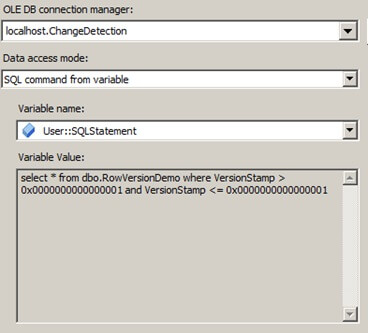
Click Preview. You should have no results returned, but there are no errors. This is because we specified default values for our rowversion variables.
Click OK.
Check for Existing Records
One common way to handle the checking of whether a record is an insert or update is to use a Lookup transformation in SSIS. This works well as long as the data set is not massive. In the case of larger data sets, it is often better to stage all of the data and use a T-SQL Merge statement.
Drag a Lookup transformation to the Data Flow Task. Connect the OLE DB Source to the Lookup transformation.
On the first page, change the drop-down from "Fail component" to "Redirect rows to no match output".
- Go to the Connection page.
- Click the bullet next to "Use results of an SQL query:"
For the query, use the following:
select DemoID from dbo.RowVersionExport
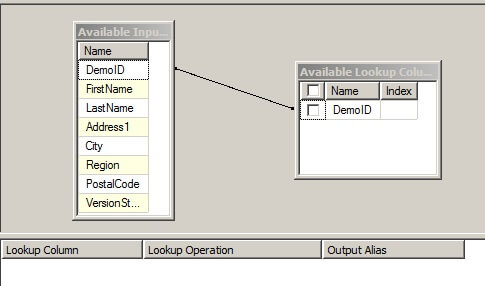
- Go to the Columns page.
- Connect DemoID to DemoID.
- Make sure to click the checkbox
- Click OK.
Output to Destination
Drag an OLE DB Destination control to the Data Flow canvas. Connect the Lookup transformation to it. When prompted, choose the Lookup No Match Output.
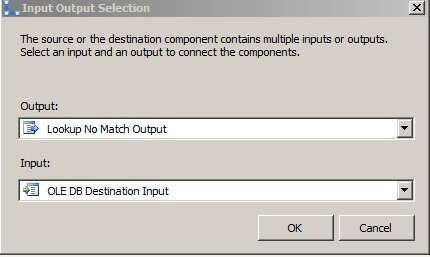
Rename the OLE DB Destination to Inserts.
Double-click the control to open it for editing. In the drop-down that is blank, change it to our destination table: dbo.RowversionExport
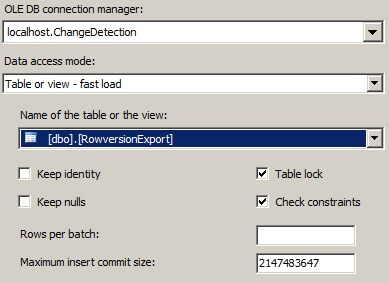
Click the Mappings page and verify that the mappings look correct.
Click OK.
Staging Updates
In the case of ETL with SQL Server, many have discovered that bulk inserting data to a staging table and running a single update is much faster than sending a stream of update statements. We will use this approach in this example. Alternatively, if you do not want to use a staging table at all, then you would need to use the OLE DB Command with SSIS.
Drag an OLE DB Destination control to the Data Flow canvas. Connect the Lookup transformation to it. Automatically, the "Lookup Match Output" should be assigned as the output from the Lookup Transformation.
Rename the OLE DB Destination to Updates.
- Double-click the control to open it for editing.
- In the drop-down that is blank, change it to "dbo.Stage_RowversionExport".
- Click the Mappings page and verify that the mappings look correct.
Click OK.
Now your Data Flow Task should look like the following:
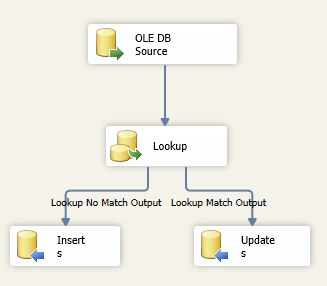
In this particular example, we are going to update the destination and overwrite the record there with any record that has changed from the source.
Go back to the Control Flow.
- Drag an Execute SQL Task onto the Control Flow.
- Rename the task to "Update From Stage".
- Connect the Data Flow Task to this task.
- Double-click the control to open it for editing.
- Change the Connection to your database.
Change the SQLStatement to the following:
update dest set dest.FirstName=stg.FirstName, dest.LastName=stg.LastName, dest.Address1=stg.Address1, dest.City=stg.City, dest.Region=stg.Region, dest.PostalCode=stg.PostalCode, dest.VersionStamp=stg.VersionStamp from dbo.Stage_RowversionExport stg join dbo.RowversionExport dest on stg.DemoID = dest.DemoID
Click OK.
Handling the Staging Table
However, we're not done with the staging table. Currently with this model, we have no way to clean out the table and there's an issue with an index on it. Indexes can reduce the load time of bulk insert operations.
To deal with this, we will bring another Execute SQL Task into our Control Flow.
Name the task "Truncate Stage". We'll want to move the connector from Get LSERV and connect it to Truncate Stage, then the connector from Truncate Stage should go to Data Flow Task.
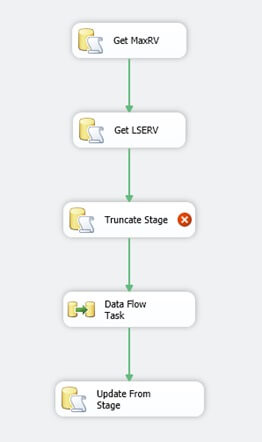
Double-click Truncate Stage to edit it.
Set the Connection to your database.
Set the SQLStatement to the following:
truncate table dbo.Stage_RowversionExport go alter index all on dbo.Stage_RowversionExport disable
Now this will ensure that our indexes are disabled and that this table is cleared out. This will allow for fast loads to our staging table. However, we need to re-enable this index at some point.
Rebuild the Indexes
After the Data Flow Task, and before Update From Stage, create a new Execute SQL Task.
Name this "Rebuild Indexes".
Double-click the task to edit it.
Set the Connection to your database.
Set the SQLStatement to the following:
alter index all on dbo.Stage_RowversionExport rebuild
Click OK.
Update our Utility Table
Finally, we're on the last step of the process. All we need to do now is update our utility table with the rowversion values and then we can rerun this process as much as we like.
Create a new Execute SQL Task. Name this to "Update LSERV". Connect Update From Stage to the new task.
Double-click the task to edit it.
Change the connection to your database.
Set the SQLStatement to the following:
update dbo.ETLRowVersions set VersionStamp = ? where TableName = 'RowVersionDemo' and SchemaName = 'dbo'
- Click the Parameter Mapping page.
- Click the Add button.
- Change the Variable Name to User::MaxRV.
- Change the Data Type to VARCHAR.
- Change the Parameter Name to 0.

Click OK.
Time to Execute!
The package is built, and we should be able to run it to review the results and see how the incremental load process works. The first run will insert everything to the export table, which is expected.
Now let's insert a record and update a record. When we rerun the package, we should see the results.
Current results of the RowversionExport table:

Execute the following statements in SQL Server Management Studio:
update dbo.RowVersionDemo
set LastName = 'Swords'
where LastName = 'Shields';
insert dbo.RowVersionDemo (FirstName,LastName,Address1,City,Region,PostalCode)
values ('Clio','Wilder','208-5401 Enim St.','Fort Worth','TX','6278');
Notice the different VersionStamp value in our source data after the update statement.
Run the SSIS package again.
Then we have the output from this. This will have the newly inserted record and the change from the update will be there as well.

Next Steps
- See Change Data Capture tips.
- Use hash values to determine what has changed for an update.
- Look into using the Merge statement to handle the loading from staging, like this tip.
- Download the sample solution for this tip.






About the author
 Robert Biddle is a Data Architect with over 10 years of experience working with databases. He specializes in data warehousing and SSIS.
Robert Biddle is a Data Architect with over 10 years of experience working with databases. He specializes in data warehousing and SSIS.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2014-07-30
