By: Aaron Bertrand | Updated: 2014-07-31 | Comments (5) | Related: > Performance Tuning
Problem
It is often generalized that seeks are better than scans in terms of retrieving data from SQL Server. The index hint FORCESCAN was recently introduced so that you could coerce the optimizer to perform a scan instead of a seek. Which might lead you to wonder: Why would I ever want a scan instead of a seek?
Solution
In reality, sometimes a seek is the optimal approach, but in some cases a scan can actually be better. I recently blogged about this in general terms in my post, "T-SQL Tuesday #56: Assumptions." And Rob Farley went much deeper in his post, "Scans are better than Seeks. Really."
This could be for a couple of reasons, but they all come down to plan stability and predictable performance:
- When you can't improve indexes
In some cases you will have queries that could optimally use an index to seek, if only it had an additional key column, some INCLUDE columns, or a filter. However, in some cases, you don't have the ability to make changes to indexes - either because of the change process required to address short-term problems, permissions, vendor lock-down, or violation of support agreements.
Lacking those index changes, the optimizer will need to choose between an index scan and a seek (usually a range scan) with key lookups (or RID lookups, in the case of a heap). Which it chooses will depend on the parameters supplied to the query and the cardinality estimates of the rows that will return (which will in turn rely on the presence of statistics and how up-to-date they are). Sometimes it will choose a seek based on a low estimated row count, but this will end up being a poor choice because the actual row count was much higher - which can lead to a lot of those costly lookups, and other side effects like spills to tempdb based on a memory estimate that was also too low.
- When you have wildly-varying, parameter-sensitive plans
Similarly, you may have cases where you have optional parameters (think of multiple search criteria with customized paging and sorting). Again, the plan that gets cached and re-used will depend on what parameters were passed in when the query was first compiled (popularly known as "parameter sniffing"). One answer here - especially since it is usually not possible to create indexes to support every combination of parameters - is to use dynamic SQL. Dynamic SQL is an ambitious refactoring, and can contribute to plan cache bloat if you don't enable optimize for ad hoc workloads. Another answer is OPTION (RECOMPILE); more on this below, but this is not always optimal either.
In the short term, if you have service-level agreements (SLAs) for query response time, it may be better to always run a query in 5-7 seconds, than to sometimes run in 2 seconds and sometimes run in 42 seconds (never mind 42 minutes).
- When cardinality estimates are useless
For tables that undergo huge variations in cardinality (or queries that often go way outside the histogram), and where you can't increase the frequency or sampling of statistics updates, you may find that a scan will lead to more consistent and predictable performance - compared to a seek that is sometimes faster but sometimes much slower. Again, if it is okay for all queries to run "fast enough," but unacceptable for any query to run "really slow," it may be beneficial to force all instances of the query to scan instead of sometimes seek fast and sometimes seek really slow.
- When OPTION (RECOMPILE) is not a good alternative
You can overcome a lot of these "bad plan" problems using OPTION (RECOMPILE), but in some cases the cost of recompiling *every time* can be prohibitive - especially in cases where the system is already CPU-bound, or where the compilation time is actually quite high compared to the runtime of the query itself.
- Other possibilities
You may also try other hints like OPTIMIZE FOR UNKNOWN before trying FORCESCAN, or changing the WHERE clause to make a seek impossible, by introducing some non-sargable predicate. The absolute last resort would be to use conditional T-SQL to determine which version of the query to call depending on the parameter values; this solution is less than optimal because it creates a lot of redundant code and makes your queries that much harder to maintain.
A Simple Example
Using AdventureWorks2012, create the following index on the Sales.SalesOrderHeader table:
CREATE INDEX IX_SOH_OrderDate ON Sales.SalesOrderHeader(OrderDate, CustomerID, TotalDue);
Now, compare these two queries:
DECLARE @start_date DATETIME = '20060101', @end_date DATETIME = '20120102'; SELECT SalesOrderID, OrderDate, CustomerID, TotalDue, OnlineOrderFlag FROM Sales.SalesOrderHeader WITH (FORCESCAN) WHERE OrderDate >= @start_date AND OrderDate < @end_date; SELECT SalesOrderID, OrderDate, CustomerID, TotalDue, OnlineOrderFlag FROM Sales.SalesOrderHeader WITH (FORCESEEK) WHERE OrderDate >= @start_date AND OrderDate < @end_date;
Runtime results, as shown in SQL Sentry Plan Explorer:

Here we see that the query that was forced to seek actually took longer, used more CPU, and had to perform a much larger number of reads. We can see why when comparing the plans. The scan shows a trivial plan:
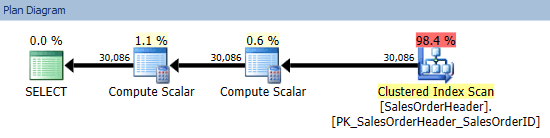
While the seek has to perform an expensive key lookup to go get the single bit column that is not covered by the index:
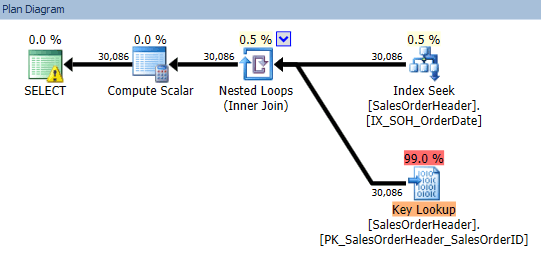
Ideally, we would have added OnlineOrderFlag to the index, to eliminate that costly key lookup. But, as mentioned above, changing the index is not always possible (and may have other unknown side effects you might not have the luxury to explore). Feel free to play with this and adjust the start and end dates so that you have very low and very high row counts. You will see that sometimes the seek fares better, but sometimes the scan is much more efficient.
Conclusion
Index tuning is always my preferred method to solving issues with particular query plans. If index tuning is out of the question, OPTION (RECOMPILE) is usually my next attempt, and after that I would go to dynamic SQL with optimize for ad hoc workloads enabled. If I have way too much volatility in cardinality and/or plan stability, my next choice would be to see if FORCESCAN can overcome this, at least in the short term.
Have you found FORCESCAN beneficial in your scenario? I'd love to know about situations where you made use of this hint, and how much it helped. Comment below or hit me up on twitter - (@AaronBertrand)!
Next Steps
- Review the following tips and other resources:
- Understanding SQL Server Indexing
- Index Scans and Table Scans (Tutorial)
- SQL Server Performance Tuning with Hypothetical Indexes
- The SQL Server Performance Tuning Tips Category
- FORCESCAN is documented on MSDN both under Table Hints and Query Hints.






About the author
 Aaron Bertrand (@AaronBertrand) is a passionate technologist with industry experience dating back to Classic ASP and SQL Server 6.5. He is editor-in-chief of the performance-related blog, SQLPerformance.com, and also blogs at sqlblog.org.
Aaron Bertrand (@AaronBertrand) is a passionate technologist with industry experience dating back to Classic ASP and SQL Server 6.5. He is editor-in-chief of the performance-related blog, SQLPerformance.com, and also blogs at sqlblog.org.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2014-07-31
