By: Scott Murray | Comments (3) | Related: > Analysis Services Development
Problem
What are the different methods of dealing with errors in SQL Server Analysis Services (SSAS) processing and should I change the default options? What are the SSAS error processing options for a cube, a partition, or a dimension? How can you change the SSAS error processing configuration?
Solution
SQL Server Analysis Services (SSAS) actually offers an array of various error handling techniques for common issues that surface when processing a cube, a partition, or a dimension. These properties allow you to set various error number thresholds for stopping processing while at the same time telling SSAS how to handle specific errors that occur. As with many features, you need to be careful to use these options appropriately and with full knowledge of the impact on your data. Many of the options often would violate foreign key constraint issues that normally would surface in a normalized OLTP database. To the contrary, the error processing options provide a great way for cube processing to continue when only minor or immaterial errors occur during cube processing which in turn provides for great "up and running" time for the cubes themselves.
We will use the Adventure Works databases as the basis for our SSAS cube processing. The 2014 versions of the regular and data warehouse databases, along with the SSAS cube database backups are available on Codeplex at https://msftdbprodsamples.codeplex.com/releases/view/125550. Once you download and install the SQL Server databases and the MultiDimensional SSAS cube database, we will subsequently use SQL Server Data Tools (SSDT-BI) for Visual Studio 2013 to work through the cube processing examples.Setting the SSAS ErrorConfiguration Properties
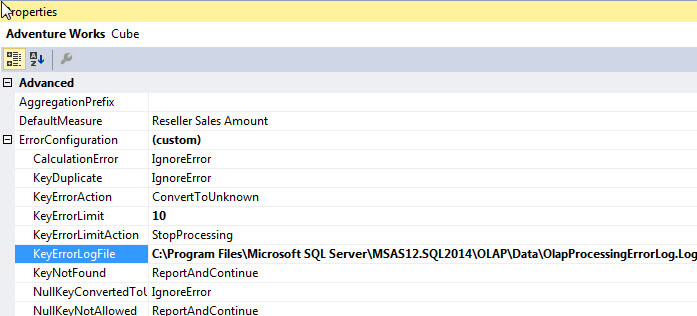
As shown in the next illustration the default error configuration for an SSAS cube is not surprisingly "default". In actuality, 9 properties make up the error configuration setting and each property has its own default value as shown in the second illustration below.
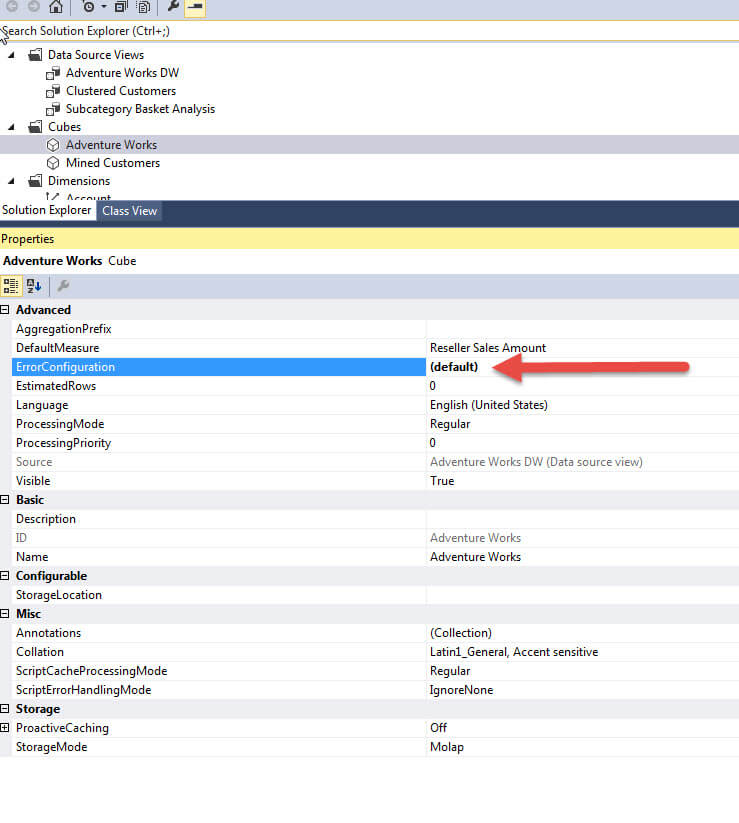
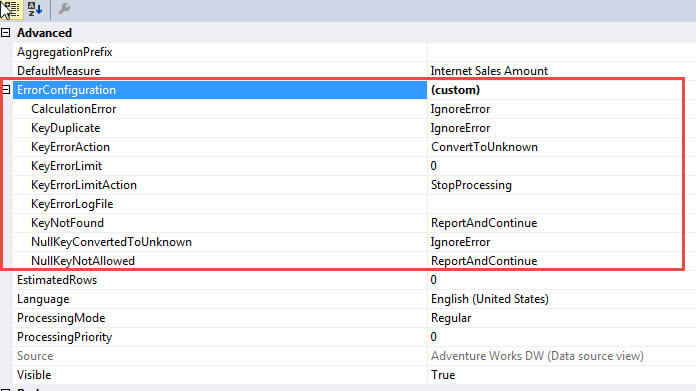
Each of the 9 properties controls slightly different processing results and several of the settings have the same potential values that can be selected. The properties include:
- CalculationError - Determines what occurs when an error is found in a calculation created on the Calculation tab.
- KeyDuplicate - Determines what occurs when duplicate keys are found in a dimension.
- KeyErrorAction - Determines what action is implemented when a KeyNotFound error occurs. The two options are ConvertToUnknown and DiscardRecord.
- KeyErrorLimit - Determines how many errors can be recorded before processing stops, -1 allows for unlimited errors.
- KeyErrorLogFile - Notes the location of the SSAS processing error log file, the SSAS service account must have access to the directory.
- KeyNotFound - Determines what occurs when a foreign key in the fact table does not have a matching primary key value in the related dimension table.
- NullKeyConvertedToUnknown - Determines what occurs when null values are converted to unknown members.
- NullKeyNotAllowed - Determines what occurs when null values are not allowed.
The option grid below shows the actions available for the CalculationError, KeyNotFound, KeyDuplicate, NullKeyNotAllowed, and NullKeyConvertedToUnknow:
|
Error Option | Log Error? | Count Error? | Continue Processing? |
|---|---|---|---|
| IgnoreError | No | No | Yes |
| ReportAndContinue | Yes | Yes | Yes |
| ReportAndStop | Yes | Yes | No |
The difficult thing with setting the error configurations is that they can be set in one or more of all the following places:
- Cube properties
- Dimension properties
- Partition properties
- During processing of any of the above
Furthermore, NULL processing methods always occur first before the error configurations are implemented and in some cases the Unknown Member settings in a dimension must be set in a specific way to interact with the error configuration properties.
SQL Server Analysis Services Error Processing Example
So what does all this mean; it means that you need to make sure you understand and use the proper setting when you process your cubes, partitions, and dimensions.
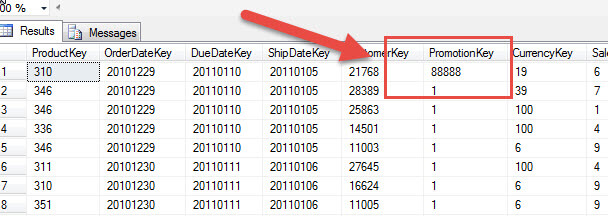
Let us look at a few examples; I am going to make changes to the PromotionKey field in the FactInternetSales fact table and the related primary key, PromotionKey in the DimPromotion table. To be able to show you the various examples, I did need to remove the constraint on the PromotionKey field in the fact table. I then updated the PromotionKey in the fact table to a value that I knew was not a valid primary key value in the Promotion Dimension source table. As illustrated below, I updated the value to 88888.
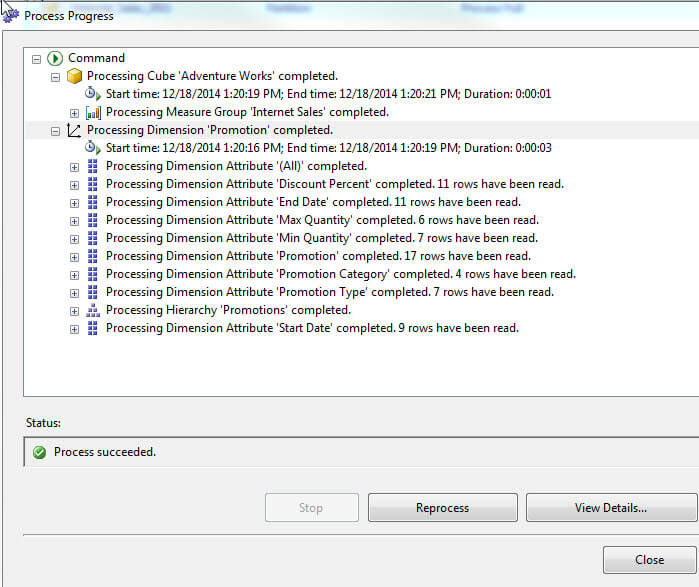
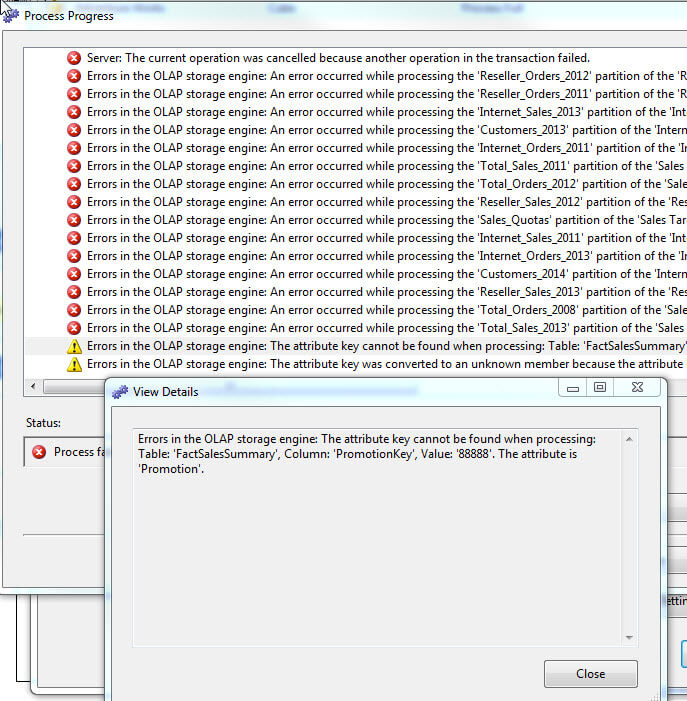
Now when the cube is processed the below attribute key not found error results.
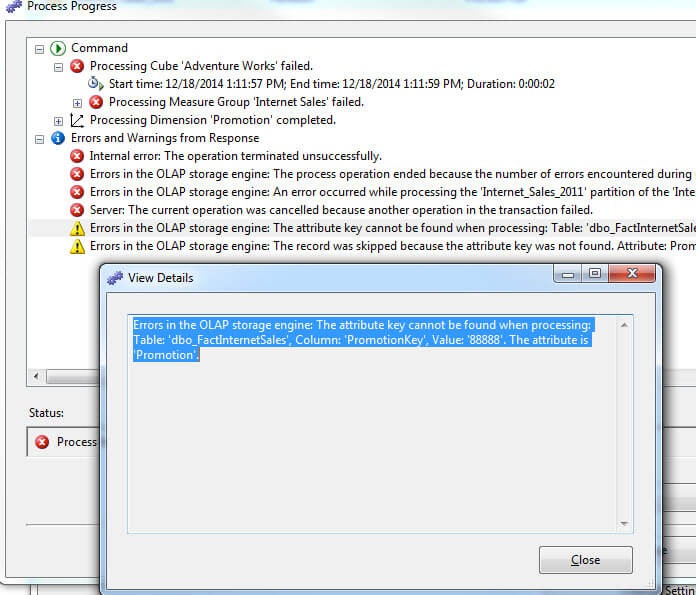
One option, which is shown below, is to change the KeyNotFound to IgnoreError. This change means that any key not found errors will not be counted in the error count nor will they be logged. Also, based on the KeyErrorAction field which is set to ConvertToUnknown, the invalid PromotionKey value will be converted to Unknown.
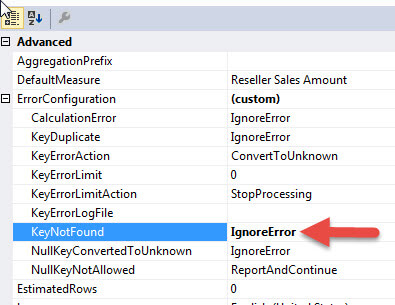
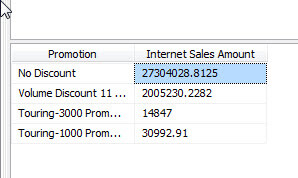
The result of this setting is that the cube processes without reporting any errors as shown below. Of course, this result is a false positive, in that the cube did process fine; however, the offending data row was actually "quarantined" so to speak and the data is not included in the fact table measure values reported to the client application and report. The row is absent from the data, and we actually have no knowledge that a problem even existed.
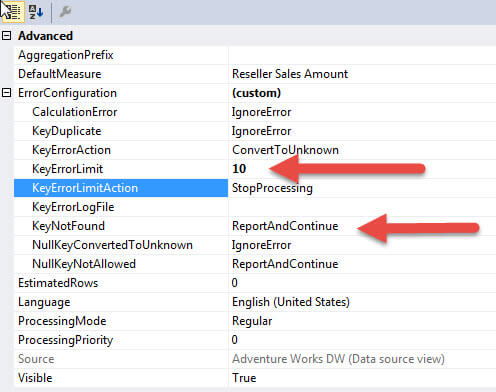
We could create a similar situation processing wise while at least getting a report of the errors by changing two fields: 1) change the KeyNotFound property to ReportAndContinue and 2) Adjusting the KeyErrorLimit to a number below which we will accept errors. In this scenario, we are requesting that the error be reported (both via the processing window and the log, which we will discuss later) and also that processing will stop if we see more than 10 errors.
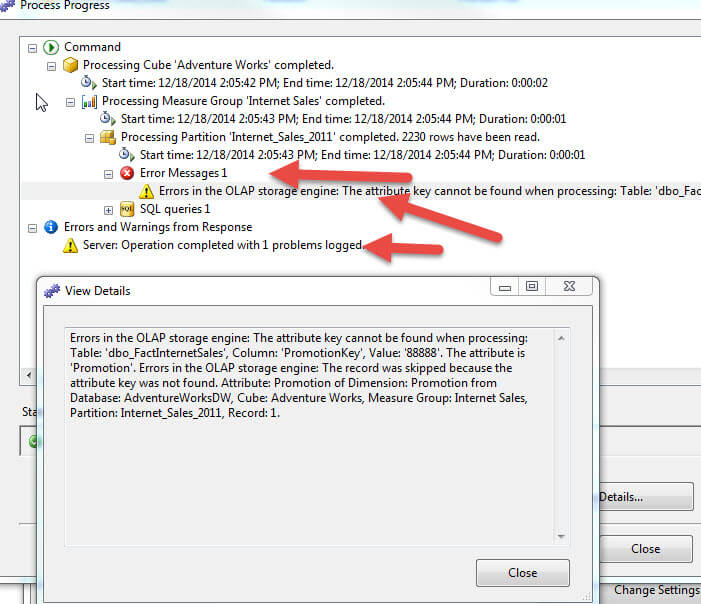
Now when the cube is processed, the processing still completes and the row is still removed from the measure data. However, we receive a notification that a key error does exist, as displayed next. An error message is displayed in the processing window, that specifically tells us what error occurred, i.e. the missing promotion value.
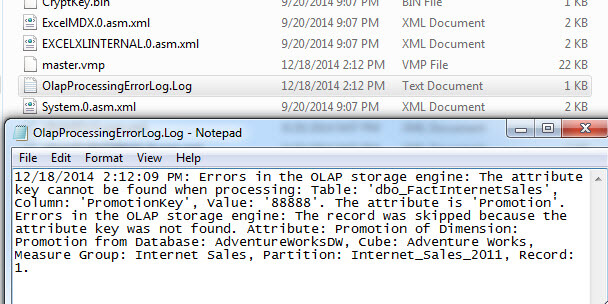
Next, by adding a path and file name to the KeyErrorLogFile property, the errors will get logged to a log file.
The below error log clearly shows the PromotionKey error while still processing the cube to completion. Even so, the invalid row is still removed from the cube results; using the cube browser a copy of the data results are displayed in the second screen print below and do not include the invalid key data row.
Up to this point, the offending row has been removed from the dataset returned to the client application. We could allow the row to show as an "Unknown" value by making two adjustments to the dimension that is causing the error, Promotion for our example. First, within the dimension properties, the UnknownMember property needs to be set to Visible. Second, the UnknownMemberName should be updated to a relevant value for your situation as this name will be what is displayed to the end user.
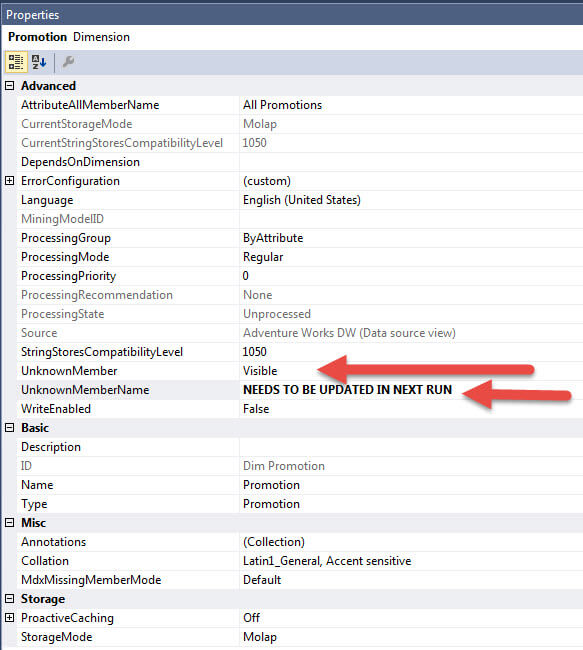
Now when the cube data is reviewed, the offending row is displayed with, in the below example, with a specific name of "NEED TO BE UPDATED IN NEXT RUN".
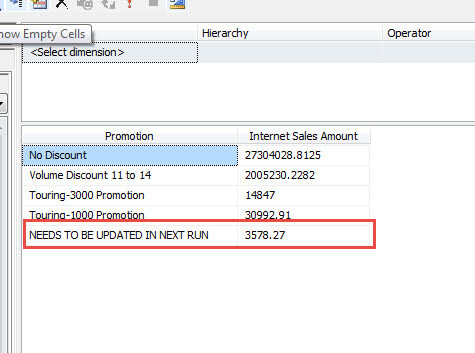
Although we concentrated on KeyNotFound property, similar error configuration processing methods could be followed with the KeyDuplicate, CalculationError, NullKeyConvertedToUnknown, and NullKeyNotAllowed error properties, and thus will not go over those in detail.
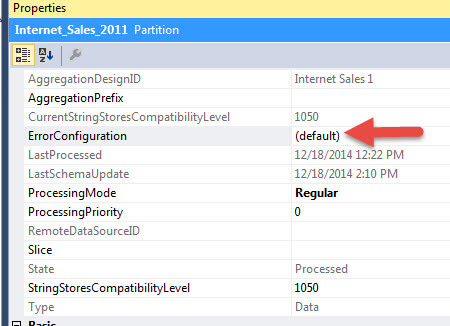
In addition to the cube error configuration property settings, these same setting can be adjusted both at the partition and dimension level, as shown in the next two figures, which can override the cube settings.
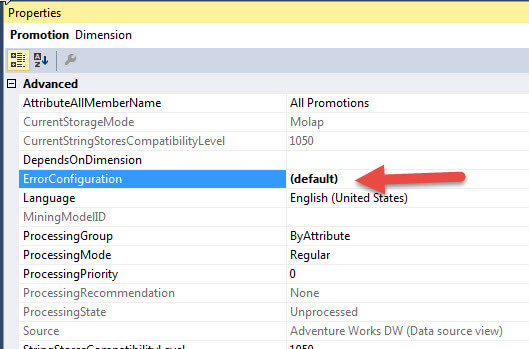
Furthermore, during the actual cube processing, we can adjust / override how errors are handled. First, the cube processing must be initiated and then the Change Settings button clicked as illustrated below.
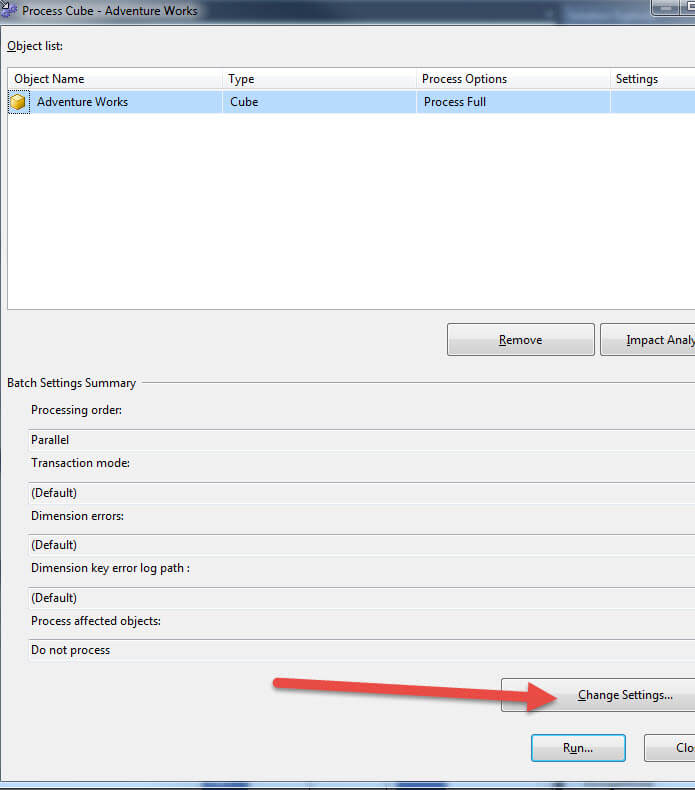
Next, clicking on the Dimension key errors tab and then Use customer error configuration radio button, allows us to adjust the error setting at processing "run time."
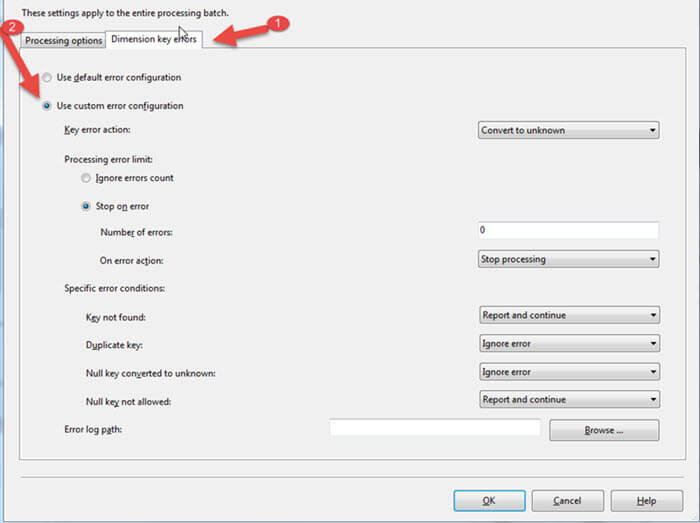
In the above screen print example, I left the Number of errors to 0; thus a single error will now stop processing of the cube. As such, the cube quickly errors out with these "run time" settings; allowing no errors for this example.
Conclusion
Out of the box, SSAS has default settings for handling errors; these settings, which exist under the ErrorConfiguration property, allow for various outcomes to occur while processing a cube, partition, or dimension. Five of the properties control whether an error is reported and processing continues, or an error is reported and processing stops, or whether the error ignored and not reported.
Furthermore, NullProcessing of values is handled first during processing, as this defines how the NullKeyConvertedToUnknown and NullKeyNotAllowed errors are handled. When the number of allowable errors is increased to a number greater than zero, the cube will continue processing until the number of errors reported meets the new threshold level.
However, when the error method is set to report and continue or ignore, the offending rows will not be included in the measure values unless the UnknownMember properties are set for the related dimension. To further complicate the situation, the ErrorConfiguration settings can be set at the cube level, the partition level, the dimension level, or during the processing itself.
With all these scenarios, much care must be followed when using the non-default ErrorConfiguration settings.
Next Steps
- Check out these resources






About the author
 Scott Murray has a passion for crafting BI Solutions with SharePoint, SSAS, OLAP and SSRS.
Scott Murray has a passion for crafting BI Solutions with SharePoint, SSAS, OLAP and SSRS.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
