By: Sadequl Hussain | Updated: 2015-06-25 | Comments (5) | Related: 1 | 2 | 3 | > PostgreSQL
Problem
Scenario 1: We have a PostgreSQL instance running on our network. We are trying to move away from PostgreSQL and want to access the data from our new SQL Server environment. We need to migrate the data before the box can be shut down. Is there a simple way to directly read data from that server while we build our new database in SQL Server?
Scenario 2: We have a third-party application that runs on SQL Server. We are predominantly a Linux shop and that's one of our few Windows servers. The vendor has recently released a Linux version of their product and we are thinking about Postgres. We were wondering if there's a simple way of accessing SQL Server data from PostgreSQL.
Solution
In a previous MSSQLTip article, author Daniel Calbimonte had shown us how SSIS can be used to import data from a PostgreSQL instance into SQL Server. The driver that sat between SQL Server and Postgres in that example was an OLEDB provider, a commercial product from PGNP. Also we saw the PostgreSQL instance was hosted in a Windows server. In most commercial environments, people tend to run PostgreSQL in *nix-like operating systems like Linux. This makes the access pattern a bit more involved.
On other hand, accessing SQL Server data from PostgreSQL is not an uncommon scenario: it's a question often raised by our community.
In this three-part series, we will create a very simple database infrastructure with one SQL Server instance and one PostgreSQL instance. We will then see how one server's data can be accessed by the other, effectively creating a two-way street.
This installment of the series will focus on creating the infrastructure and ensuring a communication channel between the two machines. In the second part, we will see how SQL Server can make use of a linked server talking to a native PostgreSQL ODBC driver. Granted, ODBC is not the best method of accessing remote data where speed is the main concern, but at least the driver is free and if you are not too worried about data transfer speeds, you can give it a try. In the third and final part, we will cover PostgreSQL's Foreign Data Wrapper (FDW) feature and see how it can be used to access SQL Server data.
Assumptions
Before going further, let's get a clear picture of our database environment:
- We are running a SQL Server 2012 64-bit Standard Edition instance on a Windows 2012 server.
- Our PostgreSQL version is 9.3. The instance is running on a Red Hat Enterprise Linux (RHEL) 7.1 system.
- We will install a sample database called World in our PostgreSQL box. We will talk about this database shortly.
- We will create a small database in SQL Server and import one or more tables from the World database into it.
- We will install the AdventureWorks sample database in our SQL Server system.
- We will create a small database in PostgreSQL and import one or more tables from AdventureWorks into it.
- We are running both database servers in Amazon Web Service (AWS) Elastic Compute Cloud (EC2) platform. In your case you could be running both the servers in AWS, another cloud platform, entirely on-premises or even in a hybrid setup. You could also be running both the machines in virtual servers hosted in your laptop.
- We are using SQL Server Management Studio (SSMS) to connect to the SQL instance.
- We are using pgAdmin-III to connect to the Postgres instance.
Preparing the Database Infrastructure
Network Configuration
For the SQL and Postgres machines to communicate, first they need to be able to reach each other over the network. This means they can be in the same LAN segment, or be able to connect over the WAN as part of a VPN setup, or even run in the same host machine as two local virtual servers. Whatever it is, they need to at least "see" each other by ping-ing each machine. That's the first thing we need to ensure.
In our current setup, we are running both the machines in AWS, in the same VPC (Virtual Private Cloud), but in different subnets that are physically separated in two different Availability Zones. That means their IP addresses will be from different ranges (10.5.1.0/24 and 10.51.2.0/24 in this case as shown in the image below). However, both the subnets are part of the same VPC - and therefore part of a bigger IP address range - and they share the same network route table that allows them to communicate with each other.

You might be connecting your on-premises server to a cloud-hosted box. If that's the case, the on-premises box will need to be part of your VPN network that connects to the cloud instance and vice versa. If you are running both machines in your corporate network, that's great. Chances are, you probably don't have to worry about network configuration much. If the network part is too unknown for you to figure out, have a chat to your network guys. And finally, if you are following this article with two virtual servers hosted in your local machine, no need to do anything at all. The machines will be part of the same network you are connecting to the Internet with.
Firewall Configuration
Next, we need to ensure that any firewall running in either machine is allowing traffic from the other end. So the PostgreSQL server should allow traffic coming to Port 5432 from the SQL Server box (or whatever port we have chosen Postgres to run on) and the SQL box needs to allow traffic coming to Port 1433 from the Postgres system (or whatever port SQL Server is running on).
Firewalls can be configured at multiple levels and you need to find out what applies in your case. It could be enforced via hardware appliance, via network rules or even at the operating system level. The ports you need to allow need to be opened at each of these layers.
In our setup for this article, we had to open up ports at three levels:
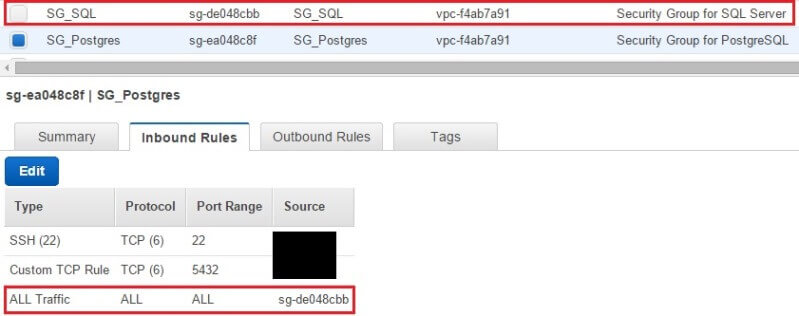
Port Changes - 1
At the network level, where AWS security groups control traffic going to the instance. We created two security groups for our machines, each with different set of rules. For those who don't know, AWS security groups are high-level virtual firewalls that can be configured to allow traffic either coming in or going out of a server. A security group can be defined only once and "attached" to multiple boxes, meaning each machine will have the same firewall rules applied to it. Machines belonging to the same security group will allow traffic from other boxes in that group. For VPC based systems you can modify security group rules anytime without rebooting the machines.
The following images show two security groups (SG) we created. One is for the Postgres server and the other is for the SQL Server box. You can see the SG_Postgres security group allows SSH (this lets us administer the server remotely), traffic coming to Port 5432 (for PostgreSQL) and any traffic from the other security group. SG_Postgres allows any traffic to leave the box. Similarly, SG_SQL allows RDP (for remote access to the server), traffic coming to Port 1433 (for SQL Server) and any traffic coming from SG_Postgres. When we say "any traffic coming from the other security group" it means the boxes would be able to send out not only SQL traffic to each other, but communicate on any other protocol like ICMP (for ping), UDP, etc. You can tighten it down to certain ports only for security best practices - but for now, we are keeping it all open between the two machines.
Again, this configuration doesn't apply if you are not using EC2 instances in
Amazon cloud.

Port Changes - 2
Next, we had to configure our OS-level firewall. Although our SQL Server machine had Windows Firewall on, we didn't have to configure it for anything. However, our Red Hat Enterprise Linux box was running the newer Firewall daemon and we had to allow Postgres traffic through it. If the Linux box in your setup is running older IPTables firewall, you need to configure IPTables to allow Postgres traffic.
The commands we ran in our Postgres Linux box were these:
$ sudo firewall-cmd --permanent --add-port=5432/tcp
This permanently adds port 5432 to the firewall rules. This allows us to remotely
connect to the PostgreSQL instance from an application like pgAdmin and it also
allows SQL Server to connect to it.
$ sudo firewall-cmd --reload
This reloads the firewall daemon without restarting it. Next, it's time to allow the SQL Server port:
$ sudo firewall-cmd --permanent --add-port=1433/tcp
$ sudo firewall-cmd --reload
Needless to say, you need your network or infrastructure team's to help modify the firewall rules at any level if you don't have administrator or root access to the systems.
Port Changes 3
The third change we made was at PostgreSQL configuration level. Postgres has its own built-in access rules and in the next section we will see how that's changed.
Once all the configurations are done, verify the machines can reach each other via ping commands.
Install and Configure PostgreSQL
This section is here if you want to play with your own copy of PostgreSQL and following this article as a tutorial. In a sense it's good because you can try out in your own setup before applying anything to production. If you are experienced and confident about making changes to your existing Postgres environment, we recommend you still read through as we'll talk about configuration later.
In the steps below we are showing how to install and configure PostgreSQL 9.3 from scratch in an empty server. The commands are applicable for Red Hat-based systems like RHEL, CentOS or Scientific Linux. If you are using Debian-basd Linux distributions like Ubuntu, you need to use appropriate package installation commands like apt-get. We are also assuming you are using a terminal or console-based application like PuTTy to remotely log into the server using Secure SHell (SSH).
Step 1: Log in to your Linux server via SSH as the root user or a user with sudo privileges.
Step 2: First, we will need to download the yum repository for PostgreSQL and for that we will need the wget utility. Install the wget tool if it's not already there.
Step 3: Download the PostgreSQL 9.3 RPM repository:
$ sudo wget http://yum.postgresql.org/9.3/redhat/rhel-7Server-x86_64/pgdg-redhat93-9.3-1.noarch.rpm
Step 4: Install the RPM repository:
$ sudo rpm -ivh pgdg-redhat93-9.3-1.noarch.rpm
Step 5: Install Postgres Server and its components:
$ sudo yum install postgresql93-server -y
$ sudo yum install postgresql93-contrib -y
$ sudo yum install postgresql93-devel -y
Step 6: Initialize PostgreSQL (we assume you are using the default
location for your data directory. Again this will be different for Debian-based
Linux distributions) :
$ sudo /usr/pgsql-9.3/bin/postgresql93-setup initdb
Step 7: Change some parameters in postgresql.conf
$ sudo vi /var/lib/pgsql/9.3/data/postgresql.conf
- Uncomment the listen_addresses parameter and change its value from 'localhost' to '*', so it should look like listen_addresses=*. This will allow PostgreSQL to listen from any IP address, not just from the local host itself.
- Uncomment the port parameter so it looks like port=5432. This enables the default PostgreSQL port.
Save and exit the vi editor.
Step 8: Edit the pg_hba.conf file.
$ sudo vi /var/lib/pgsql/9.3/data/pg_hba.conf
This is the part you need to consider even when making changes to an existing PostgreSQL instance. That's because this is where you tell PostgreSQL to accept SQL Serve's traffic. At the end of the file, add one line for the IP address of your SQL Server machine:
host all all <ip server="" sql="" of="" address=""> /32 trust</ip>
Add one line for your local machine's network IP address range
host all all <ip of="" address="" ip="" machine's="" your="" or="" network="" local="" range=""> trust</ip>
Save the file and exit vi.
So what's happening here? Well, remember in the last section we talked about configuring Postgres' own internal firewall? That's the change we just made. pg_hba.conf is one of the most important PostgreSQL configuration files. It controls who can access the PostgreSQL instance running in the machine. The first parameter, "host", specifies any access request coming from a non-localhost entity, i.e. from outside the box. The next parameter specifies which databases are allowed in the access request. We are specifying "all" - meaning our SQL Server instance would be able to connect to any database in the Postgres instance. The next parameter specifies the user account to be used by the connection. Again we are setting this to "all", meaning the connection can use any valid user account within Postgres. Next comes the IP address or the address range the connection can come from. In both cases the address/range needs to be specified in standard CIDR format. This means for a single IP address like our SQL Server instance this will be in the form XXX.XXX.XXX.XXX/32 and for any IP range it will be XXX.XXX.XXX.XXX/n - where n defines the size of the network. Finally, we are specifying the authentication method as "trust". By this we are saying the connection does not require an md5 checksum-ed password authentication.
Long story short, we have given our SQL Server box access to the PostgreSQL instance.
Step 9: Start PostgreSQL Service:
$ sudo systemctl start postgresql-9.3.service
Step 10: Enable the service:
$ sudo systemctl enable postgresql-9.3.service
Step 11: Change the built-in postgres user account password. We can do this by first switching to the postgres user account and then invoking the psql command-line utility. PostgreSQL's psql is similar to SQL Server's older osql/isql or newer sqlcmd tool. Once logged into psql, change the password::
$ sudo su - postgres $ psql postgres# \password Enter new password: Enter it again: postgers# \q $
Now our PotgreSQL instance is ready.
Restoring a Sample PostgreSQL Database
We will now restore a sample database. Just like SQL Server has its AdventureWorks sample database, Postgres has a number of sample databases created by the user community. Some of these samples can be found in PgFoundry: a software repository for Postgres related tools and products. We will be downloading the world database from there and restoring it. World has a list of cities, countries and the languages spoken in each.
Step 1: Log into the PostgreSQL box again if you are not already logged in there.
Step 2: Run the following command to download the compressed archive of the world sample database:
$ sudo wget http://pgfoundry.org/frs/download.php/527/world-1.0.tar.gz
Step 3: Next, decompress the tar archive file and copy it to the /tmp directory. We will also need to change the owner of the uncompressed directory and its contents to user postgres :
$ sudo gzip -dv world-1.0.tar.gz
$ sudo tar -xf world-1.0.tar
$ cp -R dbsamples-0.1/ /tmp/
$ sudo chown -R postgres:postgres /tmp/dbsamples-0.1/
If you look under the /tmp/dbsamples-0.1/world directory now, you will see it's got two files. One is a small README file that describes the sample database and the other is a SQL script file. This is the plain-text dump of the world database. Its purpose is like a SQL Server script file that generates a database structure and populates it with data.
$ sudo ls -l /tmp/dbsamples-0.1/world/
total 200
-rw-r--r--. 1 postgres postgres 414 May 21 08:13 README
-rw-r--r--. 1 postgres postgres 198552 May 21 08:13 world.sql
We won't look inside the file here, but import it directly in the next step.
Step 4: Switch to the postgres user
$sudo su - postgres
Step 5: Create a database called world. Note how we are embedding the "CREATE DATABASE" SQL command as a parameter to psql.
$ psql -U postgres -c "CREATE DATABASE world OWNER postgres;"
Step 6: Import the world.sql file:
$ psql -U postgres -d world -a -f /tmp/dbsamples-0.1/world/world.sql
The SQL commands will flash and scroll on the screen as they are executed against the world database.
Step 7: Check from the command line if the tables have been created in the world database:
$ psql -U postgres -d world -c "\dt;"
This will show three simple tables:

It's not a huge sample database, but our first concern is to connect to it from SQL Server, and it's sufficient for that purpose. As mentioned before, there are other sample databases for PostgreSQL that you can play with. One such sample database is SportsDB. This database has a huge structure with many tables that you can experiment importing into SQL.
Install pgAdmin-III to Manage PostgreSQL
SQL Server Management Studio (SSMS) is the front-end tool of choice for SQL Server DBAs and developers. Likewise, PostgreSQL admins and developers often use a tool called pgAdmin-III. This tool is freely available from both the PostgreSQL official site or pgadmin.org. The latest version of the tool at the time of this writing is v1.20.0. pgAdmin is available for Windows, Mac OS and desktop distribution of Linux like Fedora.
Downloading pgAdmin for Windows and installing it is a fairly straightforward process like any other Windows app, so we won't cover it here.
What we will see in the image below is the dialog box that appears when you try to connect to a PostgreSQL instance from pgAdmin.

In this case we are connecting to our PostgreSQL instance from outside the cloud as an Internet user (local computer not connected via VPN), so we have to use the machine's public IP address from AWS. The name field can have any meaningful name, the host field should have the server's network name or IP address. The port is self-explanatory, we left the MaintenanceDB field to its default value of postgres. We have decided to connect to the instance as the super user postgres (equivalent to SQL Server's "sa" user) and decided pgAdmin should remember its password. We can also specify an existing or new server group to add our instance to.
Once registered, you can view the Postgres instance from the navigation pane:

We can see our world database when we expand the Databases node. As we saw before, there are three tables under the public schema.
Right clicking on any of the tables and choosing Scripts > CREATE Script option from the pop-up menu will open a new query window with the CREATE TABLE command loaded in it. We have created two scripts here: one for the city table and another for the country table.
CREATE TABLE city ( id integer NOT NULL, name text NOT NULL, countrycode character(3) NOT NULL, district text NOT NULL, population integer NOT NULL, CONSTRAINT city_pkey PRIMARY KEY (id) ) WITH (OIDS=FALSE);
ALTER TABLE city OWNER TO postgres;
Now we need to create a corresponding city table in our destination database in SQL Server to import the data. There are differences between SQL Server and PostgreSQL data types and there are differences in their SQL syntax too, so the script we generated can't be directly run against SQL Server. Instead, we need to modify the script so it looks like this:
CREATE TABLE city
( id int NOT NULL, name varchar(50) NOT NULL, countrycode char(3) NOT NULL, district varchar(50) NOT NULL, population int NOT NULL, CONSTRAINT city_pkey PRIMARY KEY (id) )
In the same way, the country table has the following generated script in pgAdmin:
CREATE TABLE country ( code character(3) NOT NULL, name text NOT NULL, continent text NOT NULL, region text NOT NULL, surfacearea real NOT NULL, indepyear smallint, population integer NOT NULL, lifeexpectancy real, gnp numeric(10,2), gnpold numeric(10,2), localname text NOT NULL, governmentform text NOT NULL, headofstate text, capital integer, code2 character(2) NOT NULL, CONSTRAINT country_pkey PRIMARY KEY (code), CONSTRAINT country_capital_fkey FOREIGN KEY (capital) REFERENCES city (id) MATCH SIMPLE ON UPDATE NO ACTION ON DELETE NO ACTION,
CONSTRAINT country_continent_check CHECK (continent = 'Asia'::text OR continent = 'Europe'::text OR continent = 'North America'::text OR continent = 'Africa'::text OR continent = 'Oceania'::text OR continent = 'Antarctica'::text OR continent = 'South America'::text))
WITH (OIDS=FALSE);
ALTER TABLE country OWNER TO postgres;
We are changing this script as well:
CREATE TABLE country ( code char (3) NOT NULL, name varchar (50) NOT NULL, continent varchar (20) NOT NULL, region varchar (50) NOT NULL, surfacearea real NOT NULL, indepyear smallint, population int NOT NULL, lifeexpectancy real, gnp numeric(10,2), gnpold numeric(10,2), localname varchar (50) NOT NULL, governmentform varchar (80) NOT NULL, headofstate varchar (50), capital integer, code2 char (2) NOT NULL, CONSTRAINT country_pkey PRIMARY KEY (code), CONSTRAINT country_capital_fkey FOREIGN KEY (capital) REFERENCES city (id), CONSTRAINT country_continent_check CHECK (continent IN ( 'Asia', 'Europe','North America', 'Africa', 'Oceania', 'Antarctica', 'South America')) )
Postgres' text data type is similar to varchar data type in SQL Server. We have changed the data type "character" to "char", changed the way constraints are defined and did away with the owner and OID definition.
Obviously the city script needs to be run first as the foreign key from the country table depends on it. For now, let's save the modified scripts somewhere. We will come back to these in a short while.
Configure SQL Server Instance
Being in a SQL Server community site, we won't be taking the readers through SQL Server installation process. We assume you know it very well.
We have installed a SQL Server 2012 64-bit Standard Edition instance on our Windows Server 2012 box.
We then connected to the database instance from Management Studio and created a small database called world. We ran the modified city script and then the country script in that database. The newly created tables are shown below:

That's it. We are now ready to import data into our SQL tables from Postgres.
Conclusion
In this first installment of the three-part series, we have created a two-node, heterogeneous database infrastructure. We have established a communication channel between the two machines, have installed a PostgreSQL instance and configured it to accept SQL Server traffic. Along the way we have seen a new database client tool called pgAdmin. We have touched on data type differences between the two platforms and saw how there should be a data mapping exercise present in real-life migrations.
All that remains now are the actual data access methods from both ends. That's what we will see in next two parts.
Next Steps
- Stay tuned for the next two parts of this series
- Try and practice installing and configuring PostgreSQL in a stand-alone machine
- Visit PostgreSQL official website for more information
- Check the network setup in your own production environment when planning for migrations. Chat to your network administrators about configurations, firewall rules, etc.






About the author
 Sadequl Hussain has been working with SQL Server since version 6.5 and his life as a DBA has seen him managing mission critical systems.
Sadequl Hussain has been working with SQL Server since version 6.5 and his life as a DBA has seen him managing mission critical systems.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2015-06-25
