By: Daniel Farina | Updated: 2015-07-10 | Comments (5) | Related: > Integration Services Performance
Problem
You have developed an ETL project that loads the contents of a flat file into a SQL Server database and after performing some tests you notice that there is a bottleneck with the transformations that slows the SSIS package execution. In this tip I will show you how we can speed up the SSIS package by using the Balanced Data Distributor Transformation.
Solution
You probably know that a project involving extraction, transformation and loading of data (ETL) is a resource intensive task, specially these days when we have to process large amounts of data. You also probably know that analysts need to make quick decisions based on the information, so having the data loaded as quickly as possible is a must.
When analyzing ETL process performance we have to measure the time spent on each step, say the extraction phase, the data transformation and the final load. Usually the transformation phase is the longest and this is what I will cover in this tip.
There is a data transformation component for SQL Server Integration Services available to download for free in the Microsoft SQL Server 2014 Feature Pack called the Balanced Data Distributor that will allow us to increase the speed of the data transformation process.
SSIS Balanced Data Distributor Transformation
This transformation splits one source of data evenly to a number of outputs, which is known as Round Robin distribution. This takes advantage of the parallel processing capabilities of modern computers. It's very easy to use because you don't have to configure anything, just connect a data source and configure as many destinations as you want.
Usage Scenario for the Balanced Data Distributor Transformation
There are some conditions that must be met in order to take advantage of this transformation. The first and most obvious is that the data source must be big enough to justify its usage. But even if you have a huge data source this transformation could be worthless unless the next condition is true. The data source must be read faster than the rest of the transformations. In that case we can benefit from running the transformations in parallel.
The last condition to meet is that the data doesn't need to be sorted at the destination, because when we split the source into many transformations the output won't be ordered.
Sample Demonstration of the Balanced Data Distributor Transformation
For this example I will use code from two of my previous tips Export SQL Server Data with Integration Services to a Mainframe to generate a sample binary file and Importing Mainframe Data including Packed Numbers with SQL Server Integration Services to load its content back to a database. The difference is that this time we will load data in parallel.
The first step is to create a sample database.
USE [master] GO CREATE DATABASE [TestDB] CONTAINMENT = NONE ON PRIMARY ( NAME = N'TestDB_file1', FILENAME = N'E:\MSSQL\TestDB_1.mdf', SIZE = 128MB , MAXSIZE = UNLIMITED, FILEGROWTH = 64MB) LOG ON ( NAME = N'TestDB_log_file1', FILENAME = N'E:\MSSQL\TestDB_1.ldf', SIZE = 8MB, MAXSIZE = 2048GB, FILEGROWTH = 8MB) GO ALTER DATABASE TestDB SET RECOVERY SIMPLE GO
Now we create a sample table.
USE SampleDB
GO
IF OBJECT_ID('Customers','U') IS NOT NULL
BEGIN
DROP TABLE Customers
END
GO
CREATE TABLE Customers
(
CustomerID INT IDENTITY (1, 1) NOT NULL,
CustomerName VARCHAR (50) NOT NULL,
CustomerAddress VARCHAR (50) NOT NULL,
CustomerCategory TINYINT NOT NULL,
CustomerBalance DECIMAL(10,2) NOT NULL
)
We need to fill the table with sample data in order to export it to a file following the instructions of this tip Export SQL Server Data with Integration Services to a Mainframe. To generate test data you can take a look at tips like Generating SQL Server Test Data with Visual Studio 2010 and Populating a SQL Server Test Database with Random Data.
After completing those steps we have a flat file with test data ready to be loaded and we can use the Integration Services package included in the Importing Mainframe Data including Packed Numbers with SQL Server Integration Services tip. You can also download the code from these tips including the code from this tip from this link.
Before starting to load data we will truncate our sample table.
USE SampleDB GO TRUNCATE TABLE dbo.Customers GO
We will use the non-parallel version as shown below and we will measure the time to load the 2.5GB file I have created for this tip. I put my source file on a RAM drive to have a very fast data source. The next image shows the data flow after executing.

As you can see in the image below the package took 55 minutes to load the file.

Now after truncating the table we are going to load the same file, but this time we use the Balanced Data Distributor Transformation to parallelize our workload.
In order to create a parallel version of this package we will copy and paste the Script Component and the OLEDB Destination tasks until we have the desired number of parallel executions and add the Balanced Data Distributor Transformation (I created 4 of these). Then we connect the Flat File Source to the Balanced Data Distributor as an input and the Script Components as outputs like on the next screen capture.

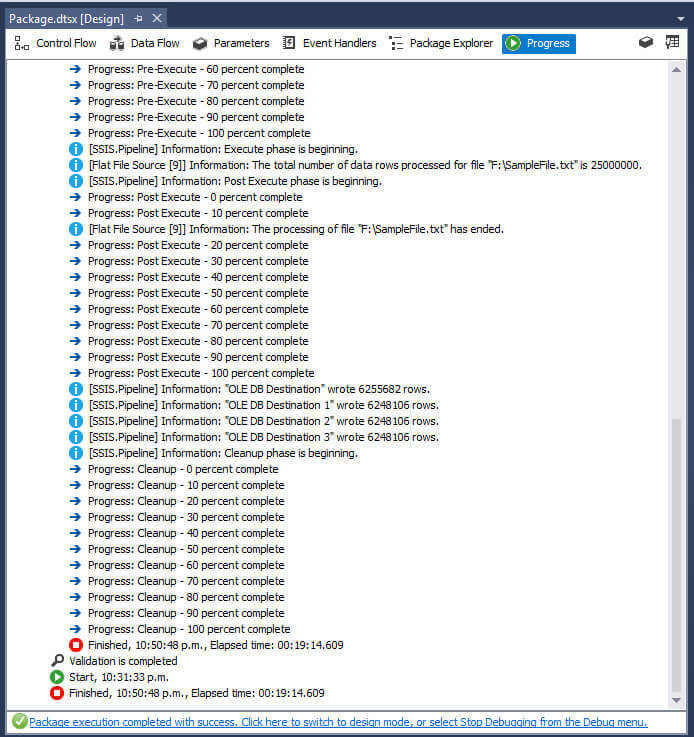
The next image shows the execution log where you can see that it took only 19 minutes to load the same file.
Next Steps
- You can download a copy of this sample project from this link.
- If you want to go deeper into Data Flow performance take a look at this tip Improve SSIS data flow buffer performance.
- The following tip will cover the basics to import data into SQL Server as fast as possible: Making data imports into SQL Server as fast as possible.
- Check out Integration Services Performance Tips Category.
- Check out Integration Services Data Flow Transformations Tips Category.






About the author
 Daniel Farina was born in Buenos Aires, Argentina. Self-educated, since childhood he showed a passion for learning.
Daniel Farina was born in Buenos Aires, Argentina. Self-educated, since childhood he showed a passion for learning.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2015-07-10
