By: Robert L. Davis | Updated: 2015-11-16 | Comments | Related: > Performance Tuning
Problem
Hash indexes, used for SQL Server in-memory OLTP, are not ordered by the index keys and scans on hash indexes can significantly hinder performance. Additionally, hash index functions require that all key columns be supplied in equality expressions. If any of the key columns are not referenced by the criteria of the query, the hash index may not be used to find buckets with matching columns. Likewise, non-equality expressions on the key columns will result in a scan because the function requires explicit values, not a range of values.
Identifying queries that yield scans on nonclustered index hashes is difficult to find unless you examine the active plan cache. Querying the cache on a production server can have a noticeable affect if the query is not well targeted to only return the data you really want to see and filtered to reduce the the amount of cache that has to be scanned. This means careful parsing of the XML.
Solution
There are essentially two ways to deal with scans on hash nonclustered indexes in SQL Server. You can change the query so that it includes all index keys in equality statements or you can create a non-hashed nonclustered index. Depending on your workload, it may be best to replace the hashed index with the non-hashed index, or it may be best to add the non-hashed index in addition to the hashed index. The decision is workload dependent and the only way to tell for sure is to test the workload with both scenarios.
Fixing it is another task. For this tip, we are focusing on identifying the query plans that are experiencing scans on hash indexes. In order to do this, we need to query three Dynamic Management Views (DMVs) and one system catalog. These are the DMVs and catalog we will query:
- sys.dm_exec_cached_plans: Returns cached execution statistics about cached query plans.
- sys.dm_exec_query_plan(): Returns the query plan in XML format. Cross apply to sys.dm_exec_cached_plans to get the plan_handle and filter on the dbid column (database ID) to limit the amount of cache that has to be scanned. Not filtering on dbid can negatively affect performance.
- sys.dm_exec_sql_text(): Returns the source of the statement in the query (procedure name or ad hoc). Cross Apply to sys.dm_exec_cached_plans to get the plan_handle.
- sys.hash_indexes: Returns information about hashed indexes. This is where it gets tricky. We join this catalog to parsed values in the XML query plan.
Query to find Plans with Scans on SQL Server In Memory OLTP Hashed Indexes
Below is the query that you can use to find plans that have scans on hashed indexes. We will take a look at this further with an example below.
WITH XMLNAMESPACES ('http://schemas.microsoft.com/sqlserver/2004/07/showplan' AS sqlx)
SELECT ProcedureName = IsNull(object_name(st.objectid, st.dbid), N'Ad hoc or object not found'),
qp.query_plan AS QueryPlan,
IndexName = I.n.value('(//sqlx:IndexScan/sqlx:Object/@Index)[1]', 'sysname'),
TableName = I.n.value('(//sqlx:IndexScan/sqlx:Object/@Schema)[1]', 'sysname') + N'.' + I.n.value('(//sqlx:IndexScan/sqlx:Object/@Table)[1]', 'sysname'),
SQLText = I.n.value('(//sqlx:StmtSimple/@StatementText)[1]', 'varchar(max)')
FROM sys.dm_exec_cached_plans AS cp
Cross Apply sys.dm_exec_query_plan(cp.plan_handle) AS qp
Cross Apply sys.dm_exec_sql_text(cp.plan_handle) AS st
Cross Apply qp.query_plan.nodes('//sqlx:IndexScan[@Storage="MemoryOptimized"]') As I(n)
Inner Join sys.hash_indexes HI On Quotename(HI.name) = I.n.value('(//sqlx:IndexScan/sqlx:Object/@Index)[1]', 'sysname')
And HI.object_id = OBJECT_ID(I.n.value('(//sqlx:IndexScan/sqlx:Object/@Schema)[1]', 'sysname') + N'.' + I.n.value('(//sqlx:IndexScan/sqlx:Object/@Table)[1]', 'sysname'))
WHERE qp.dbid = DB_ID()
AND I.n.exist('//sqlx:IndexScan/sqlx:Object[@IndexKind="NonClusteredHash"]') = 1;Example
For this example, I am going to use the AdventureWorks2014 database (upgraded to SQL Server 2016) and implement the Extensions to AdventureWorks to Demonstrate In-Memory OLTP. I am restoring this database as AdventureWorks2016imoltp on my server. In order to demonstrate this, I need to first identify a memory-optimized hash index with multiple columns.
Query to Return Hash Index with Most Columns
Use AdventureWorks2016imoltp;
Declare @TableName nvarchar(260),
@IndexName sysname;
-- Get the hashed index with the highest number of columns
Select @TableName = OBJECT_SCHEMA_NAME(HI.object_id) + N'.' + OBJECT_NAME(HI.object_id),
@IndexName = HI.name
From sys.hash_indexes As HI
Inner Join sys.index_columns IC On HI.object_id = IC.object_id
And HI.index_id = IC.index_id
Group By HI.object_id, HI.name
Having Count(*) > 1
Order By Count(*) Desc;
-- View the table name, index name, and column list for the selected index
Select TableName = @TableName,
IndexName = @IndexName,
KeyColumns = Stuff(
(Select N', ' + c.name As [text()]
From sys.index_columns As IC
Inner Join sys.columns As C On C.object_id = IC.object_id
And C.column_id = IC.column_id
Where HI.index_id = IC.index_id
And HI.object_id = IC.object_id
FOR XML PATH('')), 1, 2, '')
From sys.hash_indexes As HI
Where HI.object_id = OBJECT_ID(@TableName)
And HI.name = @IndexName;Now that I know to query table Sales.SalesOrderDetail_inmem and target index imPK_SalesOrderDetail_SalesOrderID_SalesOrderDetailID, I will only reference one of the columns listed and use it in an inequality expression. This means I am violating both conditions for efficient use of a hash index. I'm not referencing all columns, and I'm not using equality expressions. There are other indexes on the table, so I am going to provide a query hint to ensure it uses the hash index. If you are playing along at home, be sure to check Include Actual Execution Plan in SQL Server Management Studio (SSMS) before running the query.
Query that Performs Scan on Hash Index
Select SalesOrderID, SalesOrderDetailID From Sales.SalesOrderDetail_inmem with(index(imPK_SalesOrderDetail_SalesOrderID_SalesOrderDetailID)) Where SalesOrderDetailID > 1;
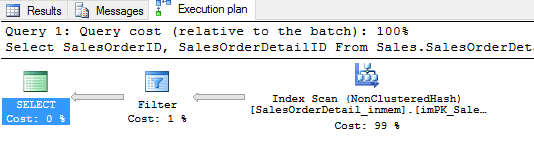
The execution plan above shows that it performs a scan on the hash index. Since I know that scans on hash indexes run slowly, I can either create a memory-optimized non-hashed index or I can rewrite the query so that it includes all key columns of the index in equality statements. In this case, rewriting the query to use equality statements would either change the output of the query, or it would have to include a long list of hard coded values. In this scenario, I am going to opt for the non-hashed index as the easier solution.
Since we cannot create a memory-optimized index on an existing table (it can only be created as part of the CREATE TABLE statement), I will create a new table named Sales.SalesOrderDetail2_inmem that is an exact copy of Sales.SalesOrderDetail_inmem except with an additional index named IX_SalesOrderDetail2_SalesOrderdetailID that is a memory-optimized non-hashed index on SalesOrderDetailID.
Query that Performs Scan on Hash Index
CREATE TABLE [Sales].[SalesOrderDetail2_inmem]( [SalesOrderID] int NOT NULL INDEX IX_SalesOrderDetail2_SalesOrderID HASH WITH (BUCKET_COUNT=10000000), [SalesOrderDetailID] bigint IDENTITY NOT NULL INDEX IX_SalesOrderDetail2_SalesOrderdetailID, [CarrierTrackingNumber] [nvarchar](25) NULL, [OrderQty] [smallint] NOT NULL, [ProductID] [int] NOT NULL INDEX IX_SalesOrderDetail2_ProductID HASH WITH (BUCKET_COUNT=1000000), [SpecialOfferID] [int] NOT NULL, [UnitPrice] [money] NOT NULL, [UnitPriceDiscount] [money] NOT NULL CONSTRAINT [IMDF_SalesOrderDetail2_UnitPriceDiscount] DEFAULT ((0.0)), [ModifiedDate] [datetime2] NOT NULL , CONSTRAINT [imPK_SalesOrderDetail2_SalesOrderID_SalesOrderDetailID] PRIMARY KEY NONCLUSTERED HASH ( [SalesOrderID], [SalesOrderDetailID]) WITH (BUCKET_COUNT=50000000) ) WITH (MEMORY_OPTIMIZED=ON); GO SET IDENTITY_INSERT Sales.SalesOrderDetail2_inmem ON; INSERT INTO Sales.SalesOrderDetail2_inmem ([SalesOrderID], [SalesOrderDetailID], [CarrierTrackingNumber], [OrderQty], [ProductID], [SpecialOfferID], [UnitPrice], [UnitPriceDiscount], [ModifiedDate]) SELECT [SalesOrderID], [SalesOrderDetailID], [CarrierTrackingNumber], [OrderQty], [ProductID], [SpecialOfferID], [UnitPrice], [UnitPriceDiscount], [ModifiedDate] FROM Sales.SalesOrderDetail; SET IDENTITY_INSERT Sales.SalesOrderDetail2_inmem OFF;
In order to compare queries, I'm going to choose a value other than 1 because SalesOrderDetailID is an identity column, supplying a value of >1 is basically every row except for 1 which would make a seek essentially the same as a scan. I'm going to arbitrarily choose >121116 as a nice middle of the table value. I'm going to run each version of the query with STATISTICS TIME turned on so we can see the difference in execution times.
Queries to Compare Scan on Hash Index Versus Seek on Non-hashed Index
Set Statistics Time On; Select SalesOrderID, SalesOrderDetailID From Sales.SalesOrderDetail_inmem with(index(imPK_SalesOrderDetail_SalesOrderID_SalesOrderDetailID)) Where SalesOrderDetailID > 121116; Set Statistics Time Off; Go Set Statistics Time On; Select SalesOrderID, SalesOrderDetailID From Sales.SalesOrderDetail2_inmem Where SalesOrderDetailID > 121116; Set Statistics Time Off;
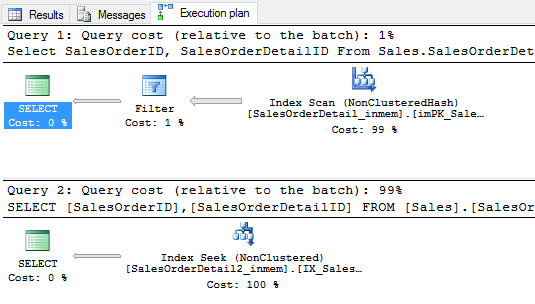
Again, I am running these queries with Include Actual Execution Plan selected. First thing we will see is that the second query uses the new index without a query hint to perform a seek. A seek is preferable over a scan because it is faster. The query cost relative to the batch is misleading in the execution plans though. It says that the scan is 1% of the total cost of the batch and the seek is 99% of the total cost. Is the seek really 99 times as expensive?
This is why I included the STATISTICS TIME in the output. Let's look at how fast these queries really are. The execution time for the 2 queries are below and we can see that the scan took 18 ms to execute while the seek took less than 1 ms.
SQL Server Execution Times: CPU time = 16 ms, elapsed time = 18 ms. SQL Server Execution Times: CPU time = 0 ms, elapsed time = 0 ms.
Next Steps
- Incorporate this query into your dev team's test process for in-memory OLTP tables using hashed indexes.
- Utilize this query as part of your standardized troubleshooting for your production systems that host in-memory OLTP tables with hashed indexes.






About the author
 Robert Davis is a SQL Server Certified Master, MVP, and experienced DBA, evangelist, speaker, writer, and trainer.
Robert Davis is a SQL Server Certified Master, MVP, and experienced DBA, evangelist, speaker, writer, and trainer.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2015-11-16
