By: Fikrat Azizov | Updated: 2016-02-08 | Comments (2) | Related: > Indexing
Problem
SQL Server 2012 is known for a few amazing performance features and columnstore index is one of them. According to Microsoft, this new type of index can bring up to a 10x performance improvement for certain queries and is recommended for large data warehouse and real time operational analytics solutions. Columnstore indexes are best suited for queries involving large table scans, especially fact/dimension joins and aggregations, which are typical to data warehouses. However, some data warehouse reports targeting a smaller data range may still benefit more from traditional B-Tree indexes than columnstore indexes. The choice between B-Tree and columnstore is further complicated with SQL Server 2014, which allows a hybrid solution, tables with both B-tree and columnstore indexes. In this tip I'll explore a few query types with different data ranges to see the advantages of each option.
Solution
SQL Server Columnstore Index Overview
Columnstore index performance optimizations are based on few basic factors:
-
Data is stored in a compressed form in columnstore indexes and depending on the nature of the data this compression can reach a 7X reduction. Compression enables queries to generate significantly less I/O operations, as compared to traditional B-Tree indexes, thus resulting in better performance. Because the index is based on an entire column rather than row or page, columnstore indexes achieve more compression than traditional row/page compression, see Niko's research.
-
Data inside a columnstore index is stored on a per-column basis, rather than per-row basis (which is specific to B-Tree indexes). To achieve that, each column included in a columnstore index is divided into smaller (approximately 1 million values) groups, called segments, see this article for details. This new storage mechanism allows column pages to be read independently from columnstore indexes, which is a big advantage, because typical data warehouse queries do not need all the columns from the underlying index.
-
Advanced query execution technology processes chunks of columns called batches in a streamlined manner. A "batch" is an object that contains about 1000 rows. Batch processing can reduce CPU consumption 7X to 40X compared to the older, row-based query execution methods. With SQL Server 2014 batch mode is being used for a wider range of query processing operators as compared to SQL Server 2012, making this feature even more attractive.
The columnstore index feature has
undergone significant changes since it was first introduced in SQL Server 2012. It used
to be a non-updateable nonclustered columnstore index based on clustered B-Tree
index. SQL Server 2014 has introduced a clustered columnstore index, which excludes
the possibility of having any kind of other indexes on the same table, although old
style non-clustered columnstore indexes based on clustered B-Tree indexes are still
an option. SQL Serve 2016 now allows updateable nonclustered columnstore indexes
based on a clustered B-Tree index, as well as B-Tree indexes based on clustered
columnstore indexes. You can learn more about columnstore indexes
here.
When should I use a SQL Server columnstore index?
Despite all its advantages, columnstore technology can't be a recipe for all tables in your data warehouse and the decision to move to this technology should be taken on an individual table basis based on query workload analysis. There are a few factors which might be important on deciding to move to columnstore indexes:
- Data range - If the majority of queries on a given table involve large index scans, that table would likely be a good candidate for columnstore index, see this article.
- Index coverage - If existing nonclustered B-Tree indexes do not fully satisfy queries due to the absence of certain fields, execution plans involving those queries would contain extra lookup operators. That involves clustered index reads on top of nonclustered index reads. Although in many cases performance of these indexes could be improved by simply adding missing fields to these indexes (therefore making them fully covering, see this tip), if the number/sizes of these fields is too high, this enhancement can hurt performance of data I/O transactions. So, in this particular scenario clustered columnstore index could be a better solution, as it could contain all required fields.
- Large nonclustered B-Tree indexes - Sometimes nonclustered B-Tree indexes, created to satisfy multiple queries could contain too many fields. Because this type of index store data per-row basis, queries requiring fewer fields are forced to read redundant information. Columnstore indexes would be good replacement in these cases as they would read only needed fields.
With this being said, the primary focus of this tip is to understand data range factors importance. So let's jump into an example.
Preparing test environment
For the purpose of this test we'll use the free BI database from Contoso BI Demo Dataset - please download ContosoBIDemobak and install the ContosoRetailDW database. Once the database is ready, run the following query to create a nonclustered covering B-Tree index on the FactOnlineSales table:
CREATE NONCLUSTERED INDEX [IDX_ProductKey_Covering] ON [dbo].[FactOnlineSales] ([ProductKey] ASC) INCLUDE([CustomerKey],[SalesOrderNumber],[SalesQuantity],[SalesAmount], [DiscountQuantity],[DiscountAmount]) GO
Then run this query to first to create a copy of the FactOnlineSales table with the clustered columnstore index on it:
CREATE TABLE [dbo].[FactOnlineSales_CI]( [OnlineSalesKey] [int] IDENTITY(1,1) NOT NULL, [DateKey] [datetime] NOT NULL, [StoreKey] [int] NOT NULL, [ProductKey] [int] NOT NULL, [PromotionKey] [int] NOT NULL, [CurrencyKey] [int] NOT NULL, [CustomerKey] [int] NOT NULL, [SalesOrderNumber] [nvarchar](20) NOT NULL, [SalesOrderLineNumber] [int] NULL, [SalesQuantity] [int] NOT NULL, [SalesAmount] [money] NOT NULL, [ReturnQuantity] [int] NOT NULL, [ReturnAmount] [money] NULL, [DiscountQuantity] [int] NULL, [DiscountAmount] [money] NULL, [TotalCost] [money] NOT NULL, [UnitCost] [money] NULL, [UnitPrice] [money] NULL, [ETLLoadID] [int] NULL, [LoadDate] [datetime] NULL, [UpdateDate] [datetime] NULL ) ON [PRIMARY] GO -------------------------------- --Copy the data Insert into FactOnlineSales_CI ([DateKey] ,[StoreKey],[ProductKey],[PromotionKey] ,[CurrencyKey],[CustomerKey] ,[SalesOrderNumber] ,[SalesOrderLineNumber] ,[SalesQuantity],[SalesAmount] ,[ReturnQuantity],[ReturnAmount],[DiscountQuantity],[DiscountAmount],[TotalCost] ,[UnitCost],[UnitPrice] ,[ETLLoadID],[LoadDate] ,[UpdateDate]) select [DateKey],[StoreKey] ,[ProductKey],[PromotionKey],[CurrencyKey],[CustomerKey],[SalesOrderNumber],[SalesOrderLineNumber],[SalesQuantity],[SalesAmount],[ReturnQuantity],[ReturnAmount],[DiscountQuantity],[DiscountAmount] ,[TotalCost],[UnitCost],[UnitPrice] ,[ETLLoadID],[LoadDate] ,[UpdateDate] from [dbo].[FactOnlineSales] GO --Create clustered columnstore index CREATE CLUSTERED COLUMNSTORE INDEX [ClusteredColumnStoreIndex] ON [dbo].[FactOnlineSales_CI] GO
Lastly, run this query to create a second copy of the FactOnlineSales table with a clustered B-Tree index, nonclustered B-Tree and nonclustered columnstore index:
CREATE TABLE [dbo].[FactOnlineSales_BT_CI]( [OnlineSalesKey] [int] IDENTITY(1,1) NOT NULL, [DateKey] [datetime] NOT NULL, [StoreKey] [int] NOT NULL, [ProductKey] [int] NOT NULL, [PromotionKey] [int] NOT NULL, [CurrencyKey] [int] NOT NULL, [CustomerKey] [int] NOT NULL, [SalesOrderNumber] [nvarchar](20) NOT NULL, [SalesOrderLineNumber] [int] NULL, [SalesQuantity] [int] NOT NULL, [SalesAmount] [money] NOT NULL, [ReturnQuantity] [int] NOT NULL, [ReturnAmount] [money] NULL, [DiscountQuantity] [int] NULL, [DiscountAmount] [money] NULL, [TotalCost] [money] NOT NULL, [UnitCost] [money] NULL, [UnitPrice] [money] NULL, [ETLLoadID] [int] NULL, [LoadDate] [datetime] NULL, [UpdateDate] [datetime] NULL, CONSTRAINT [PK_FactOnlineSales_SalesKey_BI_CI] PRIMARY KEY CLUSTERED ([OnlineSalesKey] ASC) ) ON [PRIMARY] GO -------------------------------- --Copy the data Insert into FactOnlineSales_BT_CI ([DateKey] ,[StoreKey],[ProductKey],[PromotionKey] ,[CurrencyKey],[CustomerKey] ,[SalesOrderNumber] ,[SalesOrderLineNumber] ,[SalesQuantity],[SalesAmount] ,[ReturnQuantity],[ReturnAmount],[DiscountQuantity],[DiscountAmount],[TotalCost] ,[UnitCost],[UnitPrice] ,[ETLLoadID],[LoadDate] ,[UpdateDate]) select [DateKey],[StoreKey] ,[ProductKey],[PromotionKey],[CurrencyKey],[CustomerKey],[SalesOrderNumber],[SalesOrderLineNumber],[SalesQuantity],[SalesAmount],[ReturnQuantity],[ReturnAmount],[DiscountQuantity],[DiscountAmount] ,[TotalCost],[UnitCost],[UnitPrice] ,[ETLLoadID],[LoadDate] ,[UpdateDate] from [dbo].[FactOnlineSales] GO --Create B-Tree index CREATE NONCLUSTERED INDEX [IDX_ProductKey_Covering] ON [dbo].[FactOnlineSales_BT_CI] ([ProductKey] ASC) INCLUDE ( [CustomerKey],[SalesOrderNumber],[SalesQuantity], [SalesAmount],[DiscountQuantity],[DiscountAmount]) GO --Create nonclustered columnstore index CREATE NONCLUSTERED COLUMNSTORE INDEX [IDX_NC_CI] ON [dbo].[FactOnlineSales_BT_CI] ( [ProductKey], [CustomerKey], [SalesOrderNumber], [SalesQuantity], [SalesAmount], [DiscountQuantity], [DiscountAmount] )WITH (DROP_EXISTING = OFF) GO
We've got almost 6X compression rate in this case (154 MB for columnstore index vs. 929 MB for B-tree)
Test execution
You can download test scripts from here. As part of the first set of tests (cases 1-14), I have run the following query with different parameter values against the FactOnlineSales and FactOnlineSales_CI tables to understand the data range impact on performance:
--Q1 SELECT [ProductKey],[CustomerKey],[SalesOrderNumber] ,[SalesQuantity] ,[SalesAmount] , [DiscountQuantity],[DiscountAmount] FROM [ContosoRetailDW].[dbo].[FactOnlineSales] where productkey between @p1 and @p2; SELECT [ProductKey],[CustomerKey],[SalesOrderNumber] ,[SalesQuantity] ,[SalesAmount] , [DiscountQuantity],[DiscountAmount] FROM [ContosoRetailDW].[dbo].[FactOnlineSales_CI] where productkey between @p1 and @p2
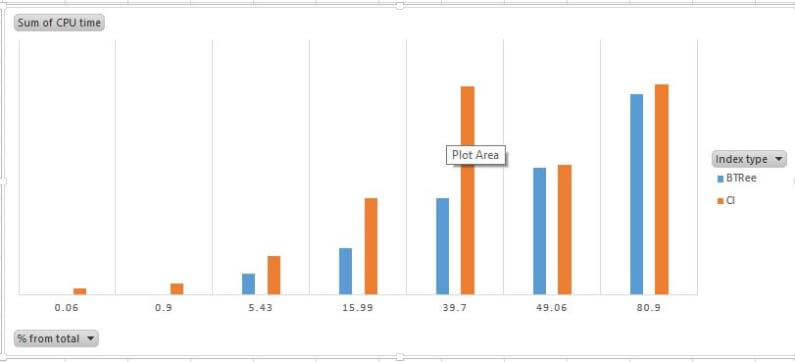
Parameter values selected for these tests would fetch various data ranges from 0.06% to 80.9% of the entire set (12,627,608 rows). I've recorded elapsed time, CPU time, logical reads as well as query processing mode (Batch/Row for columnstore indexes only) from the actual execution plan.
The next set of tests (15-18) are based on simple aggregation queries and is designed to compare an index scan on B-Tree against a columnstore index scan.
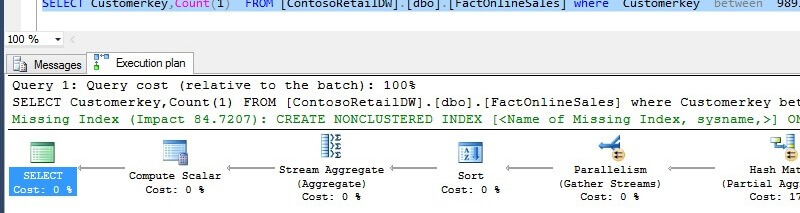
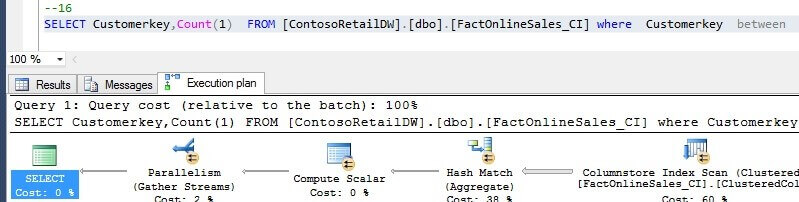
--Q2 SELECT Customerkey,Count(1) FROM [ContosoRetailDW].[dbo].[FactOnlineSales] where Customerkey between @p1 and @p2 GROUP BY Customerkey SELECT Customerkey,Count(1) FROM [ContosoRetailDW].[dbo].[FactOnlineSales_CI] where Customerkey between @p1 and @p2 GROUP BY Customerkey
The last set of tests (19-21) are based on a query similar to Q1 and is designed to test execution behavior when the table hosts both types of indexes.
--Q3 SELECT Customerkey,Count(1) FROM [ContosoRetailDW].[dbo].[FactOnlineSales_BT_CI] where Customerkey between @p1 and @p2 GROUP BY Customerkey
Please note, to make sure queries are not using cache data from previous executions I've cleared the cache with the following commands:
dbcc freeproccache dbcc dropcleanbuffers
Test results - Index seek vs. columnstore scan performance
Below you can see test results for query Q1 (test results spreadsheet is available for download here):
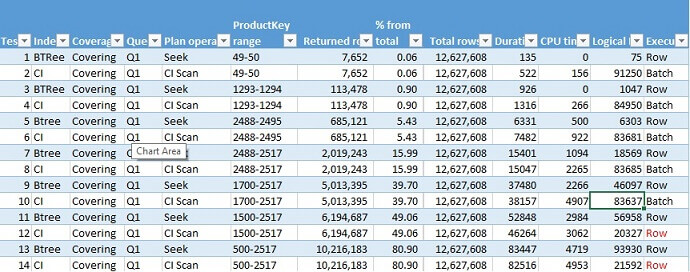
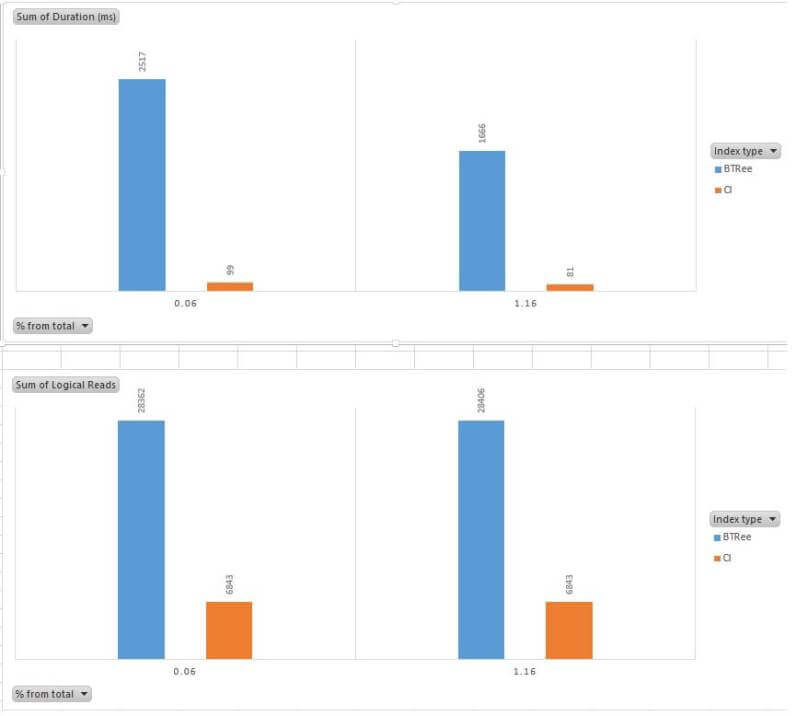
Here is the graphical representation of comparison for duration (elapsed time) and logical reads:
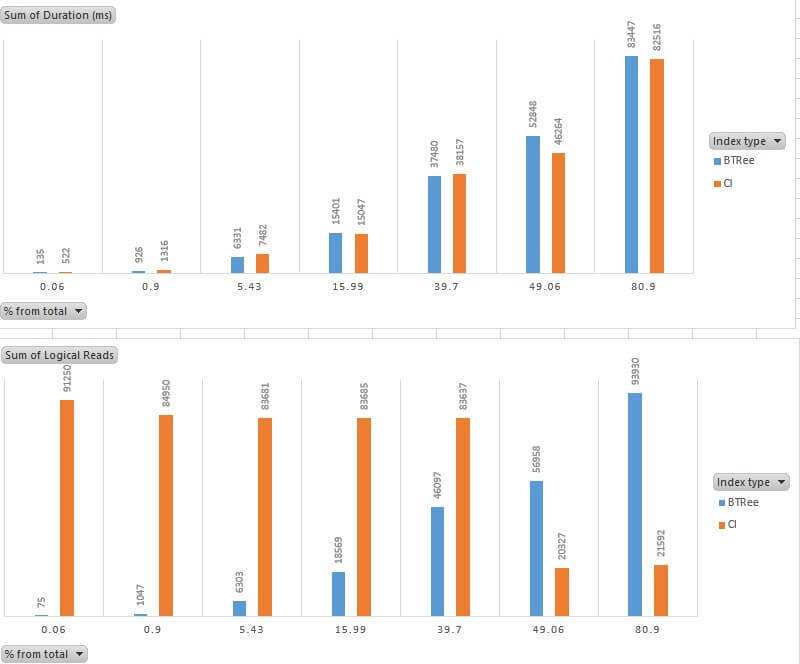
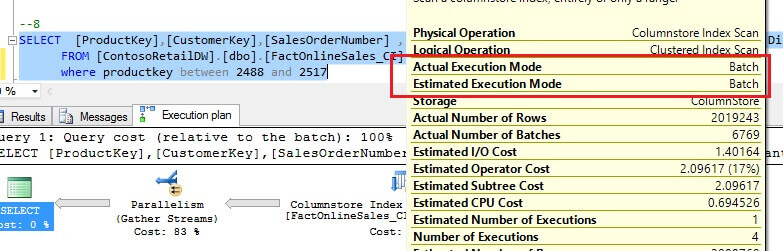
As you can see from the above charts, the columnstore index has become more efficient when the query output exceeds 49% of the entire table. What is strange here, is while logical reads for columnstore index has dropped significantly (2-4 times) above this threshold, execution duration time has dropped less than 10%. I've examined execution plans for columnstore indexes and found a possible explanation, all columnstore queries with data ranges up to 39.7% have been executed in batch mode and in multiple threads, as you can see on this execution plan:
However, above a 49% data range, SQL selects a less efficient plan with a single thread and row processing mode:
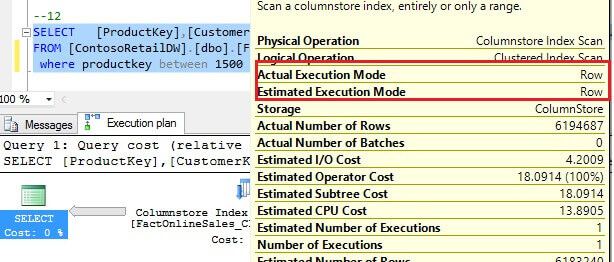
Unfortunately, my searches on explanation for this behavior didn't reveal anything, as information on row/batch execution is very thin at the moment.
We have quite a different picture with CPU consumption. Columnstore performance has never exceeded B-Tree indexes in these tests, which could be explained by the extra decompression load required for columnstore indexes:
Index Scan vs. Columnstore Scan SQL Server Performance
Aggregation query (Q2) produces an index scan execution plan for the B-Tree index:
Here is the same query's execution plan for the columnstore index, using batch processing mode:
As you can see from the below graphical representation of the test results for aggregation query (Q2), columnstore is a clear winner even with a smaller data range :
Hybrid Table Performance
When we have both types of indexes available on the same table, depending on the data range, SQL Server chooses the appropriate index, as you might expect. Here is the execution plan for the smaller range (test case 19):
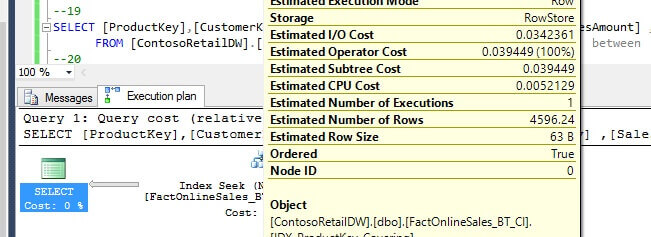
However, as the data range increases and reaches 5.43% and above, SQL switches to columnstore index:
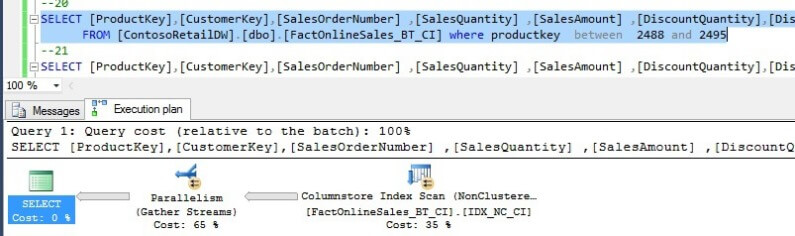
Here are test results:

Now, if you compare test results for cases #20 and #5 you'll notice that SQL Server preferred the columnstore index, even if the B-Tree index might be more efficient.
Next Steps
- Here are my summary of findings:
- Data warehouse solutions with the mix of full scan and seek query workload require caution when implementing columnstore indexes. If performance of a small range query workload is critical, those queries need to be identified and tested with columnstore indexes to ensure that performance is acceptable.
- Another thing to consider is that the data range threshold to determine when columnstore indexes are more efficient than B-Tree indexes could be much lower than we've seen in the above tests, depending how wide (in terms of number of key/included fields)
- B-Tree index is helpful whether or not it fully covers your query.
- If it's not easy to choose between B-Tree and columnstore, then the hybrid solution could be an option, however you'd need to deal with the inconvenience related to the non-updateable nature of nonclustered columnstore indexes.
- Read more about columnstore indexes here and here.
- Read more about execution plan analysis here.






About the author
 Fikrat Azizov has been working with SQL Server since 2002 and has earned two MCSE certifications. He’s currently working as a Solutions Architect at Slalom Canada.
Fikrat Azizov has been working with SQL Server since 2002 and has earned two MCSE certifications. He’s currently working as a Solutions Architect at Slalom Canada.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2016-02-08
