By: Sadequl Hussain | Updated: 2016-06-27 | Comments (9) | Related: More > Database Administration
Problem
We are an agile software development team. We develop, test and deploy new versions of our application code in short sprints. Each sprint sees us adding new features, fixing bugs, etc. Our automated Continuous Integration (CI) process makes it easy for us to deploy code without breaking anything. However we have to make changes to the SQL Server database backend sometimes and it's a manual process. The database schema files are kept in version control system, but there's no simple way to manage those changes at database level. For example, we can't see who made a database change and when, or what version of database schema we are running in an environment. Is there a simple way to manage this process?
Solution
Most IT shops see their applications going through a lifecycle. As the SQL Server application is upgraded, enhanced or retired, changes to the database structure become inevitable. There is also a degree of frequency involved in these changes. Large, monolithic applications have very few changes made over time. Compared to that, today's Internet-enabled applications have a short delivery cycle. Application developers release small, but frequent changes to the code and the code is Continuously Integrated (CI) with what's stored in the Version Control System (VCS).
Part of these frequent changes may involve changing the SQL Server database structure. Perhaps a new feature needs a new column to be added or a bug fix needs a stored procedure to be changed. In traditional waterfall method, many different database changes are packaged in one "big bang" release. In agile software development, multiple small database changes can happen over a short period of time.
While changes to the application code can be managed by version control systems (SVN, Git, etc.) and CI tools (Bamboo, Jenkins, etc.), database changes don't follow the same principle. Some changes can be handled by a CI tool, some changes need a SQL Server DBA manually running some script while other changes can be ad-hoc as part of maintenance. Unfortunately standardizing all these methods is not so simple, and often this is the part that slows down the whole application release process.
Here are some examples:
Scenario 1: Your developers have given you a large SQL script file to run in the production server. The script was created by reverse engineering the development database. However, when you run the script, it throws multiple errors. The change is cancelled and rolled back, but now you have a production database different from development, test and QA environment. How do you track this version difference? As the application release cycles progresses, more changes are made to the non-production databases. How do you add up all those changes in the script file so when you run it, it will bring up production database to the latest version?
Scenario 2: Different developers in your team are working on different parts of your database. How do you add up all those changes so they are applied in correct order? If the changes are made in different release cycles, how do you know who made the change and when was that made?
Scenario 3: A critical patch needs a new database schema change to be rolled out in both development and production servers. However, you can't run the same SQL script in both environments. The script references linked servers, databases and user accounts which are different in two environments. You maintain two sets of scripts and need to keep them in sync. If you are using multiple scripts for the database, the process becomes even more complex.
Scenario 4: You are not sure if the database in your production server has the same structure as the one in QA. You can always generate script files from both databases and compare them side-by-side, but the comparison mainly shows differences for white spaces and headers. How do you sift through all those false highlights? Even if you are using a diff tool that can show schema differences and generate a script to merge the differences, how do you know those changes won't break anything?
Scenario 5: The script file for the database schema is maintained in a version control system. At any time you can compare the changes made to the file over time. But how can you be sure each of those changes were actually applied to the database? Was version 1.x applied to the database or was it skipped and version 2.x was applied instead?
As you can see, the problems may seem difficult to solve at first. Fortunately there are some tools that can help you answer these questions. In this tip series, we will talk about one such tool, called Liquibase.
Introducing Liquibase
Liquibase (www.liquibase.org) is an open source database change management and deployment tool written by Nathan Voxland. It is written in Java and was first released in 2006. Liquibase offers an elegant solution to the database change management problem. It works with a number of database platforms including Microsoft SQL Server. The tool has a very small footprint and can be automated with a number of existing build tools. There is also a commercial version available which we will talk about later.
How Liquibase Works
Before using Liquibase, let's understand a few key concepts.
At the heart of Liquibase is what's called a database changelog file. A changelog is nothing but a plain text file which includes one or more changesets. A changelog can include other changelogs in a hierarchical fashion.
A changeset is the basic unit of change for a database. This change can be a schema change like adding or dropping tables or it can be changing the data itself. Liquibase is platform agnostic, which means it does not care what the underlying database engine is, the same change can be applied to multiple database platforms. That becomes possible because the changeset does not say how the change has to be made, rather what needs to be done. The actual change is made by the code generated by the Liquibase engine and passed on to the database driver. A changeset can incorporate one or more atomic changes (adding table, modifying column, adding indexes, adding rows, etc.), but when it runs, Liquibase considers all those changes as part of a single changeset.
The contents of a changeset include two types of information: the metadata about the change and the change instruction itself.
The metadata about the change includes a number of attributes that uniquely identifies it in the changelog file and defines how the change will be applied. We will see these attributes as we go along, but the two mandatory attributes we need to know now are the id and author of the changeset. A combination of these two attributes uniquely identifies the changeset within the changelog.
When Liquibase runs for the first time against a database, it creates two new tables in it. One of these tables is called DATABASECHANGELOG and the other is called DATABASECHANGELOGLOCK. With each run, Liquibase takes the name of a changelog file as one of its parameters. It looks into the changelog file and starts applying the changesets from the beginning. When it successfully applies a changeset's change, it adds a new row in the DATABASECHANGELOG table. This row information includes:
- The changeset id
- The changeset author name
- The changelog file name
- An MD5 checksum of the changeset
- Date and time the change was applied
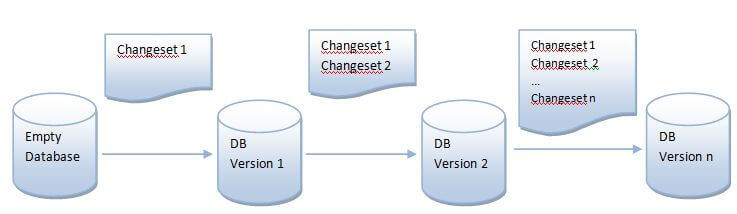
The id, author name and the file name uniquely identifies a change within the DATABASECHANGELOG table. The next time Liquibase runs the same changelog file, it again looks at the changesets from beginning and checks what's stored in the DATABASECHANGELOG table. If the change has already been applied, it skips the changeset and moves on to the next one. There is exception to this rule, but this is the default behavior. Even if the changeset id and author name remains the same, but the contents of the changeset is modified, Liquibase throws an error. That's because Liquibase calculates the MD5 checksum of the changeset content and compares it with what's stored in the DATABASECHANGELOG table. When it sees a difference, it raises the error. This means any new change will have to be part of a new and separate changeset. So if your changeset creates a new table in the database, Liquibase will not attempt to recreate it the next time it runs. If you decide to add an index to the table, you can't add that change to the same changeset. It has to come after the original changeset and defined separately. With progressive changes like this made over time, each change can be tracked easily. And this is how Liquibase keeps a database's version manageable: it incrementally updates the database with each new changeset from the changelog. The changelog file thus becomes a living document of every change made to the database and it's backed by the DATABASECHANGELOG table. The following image shows the concept:
Installing Liquibase
We will now see how to install Liquibase. It's a cross platform tool, so you can run it from Windows, Mac OS X or Linux. It can be installed either in a developer workstation or a build server. In our tests, we installed it in a laptop running Windows 10 Home Edition. We wrote our database changelogs locally and applied them to a remote SQL Server 2014 instance.
As a prerequisite, the first thing you need to ensure is that you have Java installed and configured in your workstation. In the following image, we are running Oracle Java Version 8:
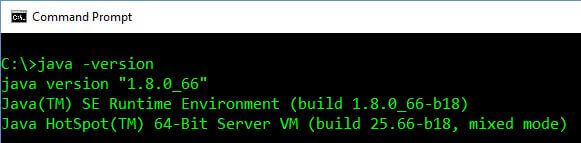
To be on the safe side, it's best to use Java 8 and use Oracle JDK. Also, if you don't have Java installed on your computer, you can download it from the Oracle site.
Liquibase connects to databases using JDBC drivers. So the next thing is to download and install the JDBC Driver for Microsoft SQL Server. This can be downloaded from the Microsoft site. The download is available in both .exe format for Windows and .tar.gz format for Mac OS X or Linux. By default, the .exe file extracts the driver in the following directory:
"%System Root%:\Program Files\Microsoft JDBC Driver 4.0 for SQL Server
For Mac OS X or Linux, download the compressed tar archive in a directory and uncompress it.
With both Java and the JDBC driver installed, it's now time to install Liquibase. Installing Liquibase is very simple. All you need to do is download the correct distribution for your computer's operating system and uncompress the archive. At the time of this writing, the latest version is 3.4.2 and it can be downloaded from here. For our Windows computer, we downloaded the liquibase-3.4.2-bin.zip file and unzipped it under C:\Liquibase:
Finally, we added the path to this directory in the Windows PATH variable:
With all that done, we are now ready to write our own changelog files and run them with Liquibase.
Our First Changelog File
Changelog files can be written in four different formats:
- XML
- YAML
- JSON
- Formatted SQL
The following code snippet shows our simple database changelog file written in XML. It creates a new table in the database and adds three fields in that table. Note how the change log uses a predefined XSD schema and how we are defining attributes for the changeset (id, author etc.). The actual change is contained within the <changeset></changeset> tags. Another thing you may notice is that we are not saying which database this changeset is meant for. This is actually specified at runtime.
<?xml version="1.0" encoding="UTF-8"?>
<databaseChangeLog xmlns="http://www.liquibase.org/xml/ns/dbchangelog" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.liquibase.org/xml/ns/dbchangelog http://www.liquibase.org/xml/ns/dbchangelog/dbchangelog-3.1.xsd">
<changeSet id="1" author="sadequl_hussain"> <createTable tableName="customer"> <column name="id" type="int"> <constraints primaryKey="true" nullable="false"/> </column> <column name="customer_name" type="varchar(50)"> <constraints nullable="false"/> </column> <column name="active" type="boolean" defaultValueBoolean="true"/> </createTable> </changeSet> </databaseChangeLog>
If you are a SQL Server Developer or DBA, you would be comfortable with traditional T-SQL script files. The same changelog can be written in Liquibase formatted SQL:
--liquibase formatted sql
--changeset sadequl_hussain:1 CREATE TABLE [dbo].[customer] ( [id] INT NOT NULL PRIMARY KEY, [customer_name] VARCHAR(50) NOT NULL, [active] BOOLEAN DEFAULT TRUE );
The first line in the SQL file has to be a comment that states it's a Liquibase formatted SQL file. Similarly, each changeset is preceded with a comment line that starts with the keyword "changeset". This is followed by a series of key value attribute pairs separated by a colon. In this example, we have specified the author name and id attributes separated by a colon (:).
Needless to say, the same changelog can also be written in YAML or JSON. Non-SQL developers would usually prefer those formats.
As you can imagine, if the database schema changes quite frequently, a single changelog can quickly become very large and unwieldy. In later part of this blog series, we will see how that can be managed.
Running Liquibase
Now that we have written our changelog, we can apply it to our database with the liquibase command. Liquibase is a command line tool, so we need to run it from the command prompt (Windows) or the terminal window (Linux / Mac OS X). Let's assume we have named the xml file as dbchangelog.xml and the Liquibase formatted SQL file as dbchangelog.sql. The Liquibase command syntax is shown below:
liquibase <options> <command><command parameters>
There are a number of options and a number of commands available for Liquibase. At a minimum, the following options need to be specified when running Liquibase:
- changeLogFile: This specifies the path and file name of the changelog
- username: The username Liquibase will connect to the database with
- password: password for the account Liquibase will connect to the database with
- url: JDBC URL for the database instance and the database
- driver: The JDBC driver class name
For our purpose, we will run the update command which will apply the changeset against a target database. We have already created a SQL Server 2014 database called "liquibase_test" in our test instance. Also, we created a SQL Server login called "liquibase" and mapped that as a db_owner in the database. This is the account Liquibase will use to connect to the database.
The command is shown below:
liquibase
--driver=com.microsoft.sqlserver.jdbc.SQLServerDriver
--classpath="C:\\Program Files\\Microsoft JDBC Driver 4.0 for SQL Server\\sqljdbc_4.0\\enu\\sqljdbc4.jar"
--url="jdbc:sqlserver://<SQL Server name or IP>:1433;databaseName=liquibase_test;integratedSecurity=false;"
--changeLogFile="D:\Liquibase\databaseChangeLog\dbchangelog.xml"
--username=liquibase
--password=liquibase
Update
We have broken down the command in separate lines for clarity's sake. For your use case, you need to replace the parameter values as necessary. Also, Liquibase commands and their parameters are case sensitive. The first part of the command or option starts in lower case and the latter parts are in uppercase.
A successful run will print the following messages on screen:
INFO 19/04/16 9:07 PM: liquibase: Successfully acquired change log lock
INFO 19/04/16 9:07 PM: liquibase: Creating database history table with name: [dbo].[DATABASECHANGELOG]
INFO 19/04/16 9:07 PM: liquibase: Reading from [dbo].[DATABASECHANGELOG]
INFO 19/04/16 9:07 PM: liquibase: D:/Liquibase/databaseChangeLog/dbchangelog.xml: D:/Liquibase/databaseChangeLog/dbchangelog.xml::1::sadequl_hussain: Table customer created
INFO 19/04/16 9:07 PM: liquibase: D:/Liquibase/databaseChangeLog/dbchangelog.xml: D:/Liquibase/databaseChangeLog/dbchangelog.xml::1::sadequl_hussain: ChangeSet D:/Liquibase/databaseChangeLog/dbchangelog.xml::1::sadequl_hussain ran successfully in 1605ms
INFO 19/04/16 9:08 PM: liquibase: Successfully released change log lock
Liquibase Update SuccessfulOnce complete, we can check the database. There will be two tables other than the "customers" table: the DATABASECHANGELOG and DATABASECHANGELOGLOCK table. These two tables are automatically generated by Liquibase the first time it runs and is updated in every subsequent run.
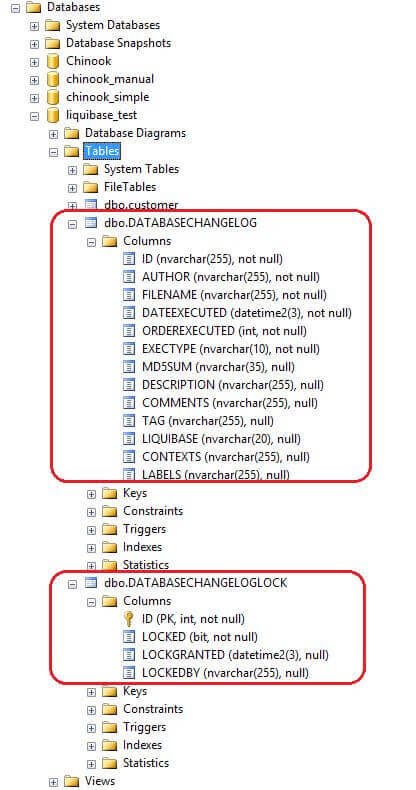
Selecting from DATABASECHANGELOG table shows us the single record that has just been added:

As you can see, the combination of ID, AUTHOR and FILENAME fields would uniquely identify each changeset. It also shows the MD5 checksum of the changeset.
Liquibase Properties file
We don't have to type all the options every time we run Liquibase. It's cumbersome and error prone. Instead, we can create a text file called liquibase.properties in the directory where we are running Liquibase from and define all the options there. At run time, Liquibase uses the options from this file. The code below shows the contents of the liquibase.properties file we created:
driver: com.microsoft.sqlserver.jdbc.SQLServerDriver classpath: ..\\Program Files\\Microsoft JDBC Driver 4.0 for SQL Server\\sqljdbc_4.0\\enu\\sqljdbc4.jar changeLogFile: D:\\Liquibase\\databaseChangeLog\\dbchangelog.xml url: jdbc:sqlserver://<SQL Server name or IP>:1433;databaseName=liquibase_test;integratedSecurity=false; username: liquibase password: liquibase
Note how the class path has been defined with relative to the current directory. This is because we are running Liquibase from C:\Liquibase directory. With the file created, we can run Liquibase with only one extra option: defaultsFile. This parameter defines the path to the liquibase.properties file:
c:\Liquibase>liquibase --defaultsFile="C:\Liquibase\liquibase.properties" update
Liquibase Update Successful
How Liquibase Manages Database Integrity
This time Liquibase skips over the changeset and does not try to recreate the table. That's because at run time it compares the changeset's id, author and the changelog file name with what's stored in the DATABASECHANGELOG table. If there is an entry in the table, it checks the MD5 checksum stored in the table against the MD5 checksum computed from the file. If they are the same, Liquibase knows the changeset has already been applied, so it does not run it again. If the MD5 checksums are different, Liquibase throws an error and exits because it has no way of knowing what changes have been applied to the object. If there is no entry in the table for that changeset, Liquibase applies the changeset.
To illustrate the point, we have modified the existing changeset in our changelog file for the customer table. We have decided to include a new column here.
<?xml version="1.0" encoding="UTF-8"?>
<databaseChangeLog xmlns="http://www.liquibase.org/xml/ns/dbchangelog" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.liquibase.org/xml/ns/dbchangelog http://www.liquibase.org/xml/ns/dbchangelog/dbchangelog-3.1.xsd">
<changeSet id="1" author="sadequl_hussain"> <createTable tableName="customer"> <column name="id" type="int"> <constraints primaryKey="true" nullable="false"/> </column> <column name="customer_name" type="varchar(50)"> <constraints nullable="false"/> </column> <column name="active" type="boolean" defaultValueBoolean="true"/> </createTable> <addColumn tableName="customer"> <column name="join_date" type="datetime"/> </addColumn> </changeSet> </databaseChangeLog>
Trying to apply the changelog file will generate an error:
Unexpected error running Liquibase: Validation Failed:
1 change sets check sum
D:/Liquibase/databaseChangeLog/dbchangelog.xml::1::sadequl_hussain is now: 7:b2b86fa580e6b8fabc016d36a6ca4bd6This is happening because we decided to change an existing changeset that has already been applied. The MD5 checksum of the changeset has changed and Liquibase can't match it with what's stored in the database. If we refactored the new column into its own changeset, there would be no problem:
<?xml version="1.0" encoding="UTF-8"?>
<databaseChangeLog xmlns="http://www.liquibase.org/xml/ns/dbchangelog" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.liquibase.org/xml/ns/dbchangelog http://www.liquibase.org/xml/ns/dbchangelog/dbchangelog-3.1.xsd">
<changeSet id="1" author="sadequl_hussain"> <createTable tableName="customer"> <column name="id" type="int"> <constraints primaryKey="true" nullable="false"/> </column> <column name="customer_name" type="varchar(50)"> <constraints nullable="false"/> </column> <column name="active" type="boolean" defaultValueBoolean="true"/> </createTable> </changeSet> <changeSet id="2" author="sadequl_hussain"> <addColumn tableName="customer"> <column name="join_date" type="datetime"/> </addColumn> </changeSet> </databaseChangeLog>
And that's how Liquibase helps in maintaining a consistent database change chain. Every change has to be part of a different changeset: you cannot modify a changeset that has already been run (although there is an exception to this rule).
Generating Changelogs
Suppose you have a database and you want to reverse engineer it. This is the opposite of what we have been doing so far. The database may be Liquibase controlled or it may be the first time you are running Liquibase on it. The command generateChangeLog can help you create an XML changelog file from the database.
In the following example, we have restored the AdventureWorks 2012 database in our SQL Server instance. And once again, we had to grant the liquibase user account access to the database.
We then ran the generateChangeLog command to create an XML changelog file for the dbo user (the line breaks and tabs are used for clarity).
liquibase --driver=com.microsoft.sqlserver.jdbc.SQLServerDriver --classpath="C:\\Program Files\\Microsoft JDBC Driver 4.0 for SQL Server\\sqljdbc_4.0\\enu\\sqljdbc4.jar" --url="jdbc:sqlserver://<SQL Server name or IP>:1433;databaseName=AdventureWorks2012;integratedSecurity=false;" --changeLogFile="D:\Liquibase\databaseChangeLog\AdventureWorks2012ChangeLog.xml" --username=liquibase --password=liquibase --logLevel=info generateChangeLog
INFO 23/04/16 1:04 PM: liquibase: D:\Liquibase\databaseChangeLog\AdventureWorks2012ChangeLog.xml does not exist, creating Liquibase 'generateChangeLog' Successful
The changelog file name is the one Liquibase will generate. Note how we have introduced another new option, logLevel. When specified, this option will output command results in one of the five different levels: off, debug, info, warning and severe. If specified with a log level of warning for example, only messages classed as warning or severe will be displayed. We are using a log level of info. Unless the option logFile is specified, logLevel will send the command output to the screen. Also, remember that we could specify all properties in a liquibase.properties file.
The generated changelog can be viewed here. You will notice it has only three table definitions, all from the dbo schema. That's because by default Liquibase will try to generate the code for default dbo schema. No functions, triggers or stored procedures were exported, although the AdventureWorks database has a number of stored procedures under the dbo schema. Unfortunately this is a limitation of open source Liquibase; the commercial version does not have this limitation.
Now, AdventureWorks has a number of schemas. Your own database may have more than one schema too. How do you export objects from those schemas? The answer is, you can use another switch in your command, defaultSchemaName and specify the schema you wish to export. In the code sample below, we are using almost the same command as before, except it has an added option and a different output file:
liquibase --driver=com.microsoft.sqlserver.jdbc.SQLServerDriver --classpath="C:\\Program Files\\Microsoft JDBC Driver 4.0 for SQL Server\\sqljdbc_4.0\\enu\\sqljdbc4.jar" --url="jdbc:sqlserver://<SQL Server name or IP>:1433;databaseName=AdventureWorks2012;integratedSecurity=false;" --changeLogFile="D:\Liquibase\databaseChangeLog\AdventureWorks2012_SalesSchema_ChangeLog.xml" --username=liquibase --password=liquibase --defaultSchemaName=Sales --logLevel=info generateChangeLog
The newly generated file can be seen here. In this case Liquibase generated objects from the Sales schema only. There are no functions or stored procedures with this schema, but there are some triggers associated with some of the tables. None of those triggers are exported. View definitions however, were scripted.
If you have a large number of schemas in your SQL Server database, you have to repeat this step to generate changelogs for each of those schemas. Obviously this can be time consuming, but with a little bit of scripting and automation, the command can be called for all schemas.
Once the schema objects are generated, you would want to export data from those tables. For that, another option is used: diffTypes, and it has to have a value of "data". The command is shown below:
liquibase --driver=com.microsoft.sqlserver.jdbc.SQLServerDriver --classpath="C:\\Program Files\\Microsoft JDBC Driver 4.0 for SQL Server\\sqljdbc_4.0\\enu\\sqljdbc4.jar" --url="jdbc:sqlserver://<SQL Server name or IP>:1433;databaseName=AdventureWorks2012;integratedSecurity=false;" --changeLogFile="D:\Liquibase\databaseChangeLog\AdventureWorks2012_SalesSchema_Data_ChangeLog.xml" --username=liquibase --password=liquibase --defaultSchemaName=Sales --logLevel=info --diffTypes="data" generateChangeLog
The output will be another XML file with a large number of INSERT tags. This will be your changelog file for importing data.
Conclusion
This has been a basic introduction to Liquibase and how it works. In the next part of this series, we will introduce some advanced features and see why this is such a powerful tool. Meanwhile, if you are really interested to get your hands dirty, you can start reverse engineering another sample SQL Server database. This one is available from the Microsoft Codeplex site. It's called chinook and can be found here. The database is fairly simple: it has a number of tables with various constraints and sample data. We would recommend you download the sample and restore it in your test server and use Liquibase to reverse engineer it. Once you are confident, you can start rolling out simple views as an experiment.
Next Steps
- Download Liquibase and install in your local workstation
- Refer to Liquibase documentation to learn about its features
- Create basic changesets and apply them to a test database






About the author
 Sadequl Hussain has been working with SQL Server since version 6.5 and his life as a DBA has seen him managing mission critical systems.
Sadequl Hussain has been working with SQL Server since version 6.5 and his life as a DBA has seen him managing mission critical systems.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2016-06-27
