By: Dallas Snider | Updated: 2016-08-29 | Comments (1) | Related: More > Big Data
Problem
I need to load data from a SQL Server table to a Hadoop Distributed File System. How can I use Sqoop to transfer the data? Can you provide the syntax and an example? Also, how do you validate the data was loaded?
Solution
Apache's Sqoop is designed to bulk-load data from relational databases to the Hadoop Distributed File System (HDFS). For this tip we will examine a Sqoop Linux command that will access a table. We will complete this tip with an example using the AdventureWorksDW2014 database. This tip is written using SQL Server 2014 and a Cloudera virtual machine.
The Sqoop command we will examine is listed below and we will break down each argument in the following bullet points. Please note that the command is supposed to be on one complete line or with the backslash (the Linux command line continuation character) at the end of each line except the last.
sqoop import --connect 'jdbc:sqlserver://aaa.bbb.ccc.ddd:pppp;databasename=yourDatabaseName' --username 'sqoopLogin' -P --table tblNameOfYourTable
- sqoop import - The executable is named sqoop and we are instructing it to import the data from a table or view from a database to HDFS.
- --connect - With the --connect argument, we are passing in the jdbc connect string for SQL Server. In this case, we use the IP address, port number, and database name.
- --username - In this example, the user name is a SQL Server login, not a Windows login. Our database is setup to authenticate in mixed mode. We have a server login named sqoopLogin, and we have a database user name sqoopUser which is a member of the db_datareader role and has a default schema of dbo.
- -P - This will prompt the command line user for the password. If Sqoop is rarely executed, this might be a good option. There are multiple other ways to automatically pass the password to the command, but we are trying to keep it simple for this tip.
- --table - This is where we pass in the name of the table.
Next, we will run an example to pull data from the DimCustomer table in the dbo schema in the AdventureWorksDW2014 database. It is a good idea to put the command in a script for repeatability and editing purposes.
[hdfs@localhost ~]$ cat ./sqoopCommand.sh sqoop import --connect 'jdbc:sqlserver://aaa.bbb.ccc.ddd:1433;databasename=AdventureWorksDW2014' --username 'sqoopLogin' -P --table DimCustomer [hdfs@localhost ~]$
The output from the sqoop command is shown below.
[hdfs@localhost ~]$ ./sqoopCommand.sh 16/07/26 19:58:00 INFO sqoop.Sqoop: Running Sqoop version: 1.4.5-cdh5.2.0 Enter password: 16/07/26 19:58:03 INFO manager.SqlManager: Using default fetchSize of 1000 16/07/26 19:58:03 INFO tool.CodeGenTool: Beginning code generation 16/07/26 19:58:04 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM [DimCustomer] AS t WHERE 1=0 16/07/26 19:58:04 INFO orm.CompilationManager: HADOOP_MAPRED_HOME is /usr/lib/hadoop-0.20-mapreduce Note: /tmp/sqoop-training/compile/adbf42b983ee80803b7d06c5a086bfb3/DimCustomer.java uses or overrides a deprecated API. Note: Recompile with -Xlint:deprecation for details. 16/07/26 19:58:07 INFO orm.CompilationManager: Writing jar file: /tmp/sqoop-training/compile/adbf42b983ee80803b7d06c5a086bfb3/DimCustomer.jar 16/07/26 19:58:07 INFO mapreduce.ImportJobBase: Beginning import of DimCustomer 16/07/26 19:58:09 WARN mapred.JobClient: Use GenericOptionsParser for parsing the arguments. Applications should implement Tool for the same. 16/07/26 19:58:10 INFO db.DBInputFormat: Using read commited transaction isolation 16/07/26 19:58:10 INFO db.DataDrivenDBInputFormat: BoundingValsQuery: SELECT MIN([CustomerKey]), MAX([CustomerKey]) FROM [DimCustomer] 16/07/26 19:58:11 INFO mapred.JobClient: Running job: job_201607151351_0004 16/07/26 19:58:12 INFO mapred.JobClient: map 0% reduce 0% 16/07/26 19:58:31 INFO mapred.JobClient: map 50% reduce 0% 16/07/26 19:58:45 INFO mapred.JobClient: map 100% reduce 0% 16/07/26 19:58:48 INFO mapred.JobClient: Job complete: job_201607151351_0004 16/07/26 19:58:48 INFO mapred.JobClient: Counters: 23 16/07/26 19:58:48 INFO mapred.JobClient: File System Counters 16/07/26 19:58:48 INFO mapred.JobClient: FILE: Number of bytes read=0 16/07/26 19:58:48 INFO mapred.JobClient: FILE: Number of bytes written=1185232 16/07/26 19:58:48 INFO mapred.JobClient: FILE: Number of read operations=0 16/07/26 19:58:48 INFO mapred.JobClient: FILE: Number of large read operations=0 16/07/26 19:58:48 INFO mapred.JobClient: FILE: Number of write operations=0 16/07/26 19:58:48 INFO mapred.JobClient: HDFS: Number of bytes read=497 16/07/26 19:58:48 INFO mapred.JobClient: HDFS: Number of bytes written=4787411 16/07/26 19:58:48 INFO mapred.JobClient: HDFS: Number of read operations=5 16/07/26 19:58:48 INFO mapred.JobClient: HDFS: Number of large read operations=0 16/07/26 19:58:48 INFO mapred.JobClient: HDFS: Number of write operations=4 16/07/26 19:58:48 INFO mapred.JobClient: Job Counters 16/07/26 19:58:48 INFO mapred.JobClient: Launched map tasks=4 16/07/26 19:58:48 INFO mapred.JobClient: Total time spent by all maps in occupied slots (ms)=63132 16/07/26 19:58:48 INFO mapred.JobClient: Total time spent by all reduces in occupied slots (ms)=0 16/07/26 19:58:48 INFO mapred.JobClient: Total time spent by all maps waiting after reserving slots (ms)=0 16/07/26 19:58:48 INFO mapred.JobClient: Total time spent by all reduces waiting after reserving slots (ms)=0 16/07/26 19:58:48 INFO mapred.JobClient: Map-Reduce Framework 16/07/26 19:58:48 INFO mapred.JobClient: Map input records=18484 16/07/26 19:58:48 INFO mapred.JobClient: Map output records=18484 16/07/26 19:58:48 INFO mapred.JobClient: Input split bytes=497 16/07/26 19:58:48 INFO mapred.JobClient: Spilled Records=0 16/07/26 19:58:48 INFO mapred.JobClient: CPU time spent (ms)=10680 16/07/26 19:58:48 INFO mapred.JobClient: Physical memory (bytes) snapshot=446173184 16/07/26 19:58:48 INFO mapred.JobClient: Virtual memory (bytes) snapshot=2954584064 16/07/26 19:58:48 INFO mapred.JobClient: Total committed heap usage (bytes)=127401984 16/07/26 19:58:48 INFO mapreduce.ImportJobBase: Transferred 4.5656 MB in 40.1166 seconds (116.5404 KB/sec) 16/07/26 19:58:48 INFO mapreduce.ImportJobBase: Retrieved 18484 records. [hdfs@localhost ~]$
Notice the last line of output above shows that 18,484 records were retrieved. This corresponds to the 18,484 records in the table as we see in the image below. Also in the image below, we see the first 10 records in the DimCustomer table.
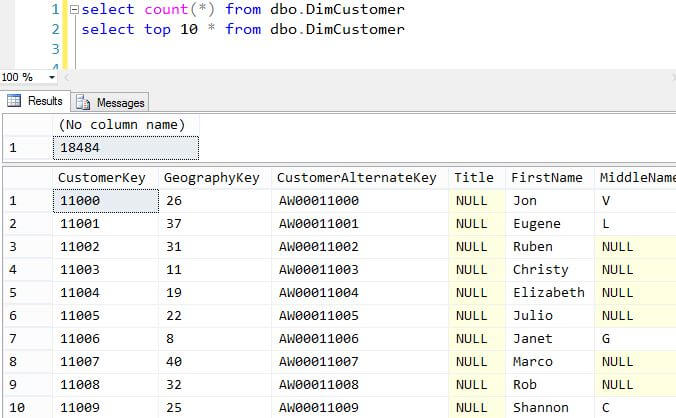
After executing the sqoop command, we can execute the hdfs dfs -ls command below to see the directory that was created by default with the table name on the HDFS.
[hdfs@localhost ~]$ hdfs dfs -ls Found 1 items drwxrwxrwx - training supergroup 0 2016-07-26 19:58 DimCustomer [hdfs@localhost ~]$
We can use the hdfs dfs -ls command below to list the contents of the DimCustomer directory. Notice how 4 partitions were created by default.
[hdfs@localhost ~]$ hdfs dfs -ls ./DimCustomer Found 6 items -rw-rw-rw- 1 training supergroup 0 2016-07-26 19:58 DimCustomer/_SUCCESS drwxrwxrwx - training supergroup 0 2016-07-26 19:58 DimCustomer/_logs -rw-rw-rw- 1 training supergroup 1195545 2016-07-26 19:58 DimCustomer/part-m-00000 -rw-rw-rw- 1 training supergroup 1194415 2016-07-26 19:58 DimCustomer/part-m-00001 -rw-rw-rw- 1 training supergroup 1196819 2016-07-26 19:58 DimCustomer/part-m-00002 -rw-rw-rw- 1 training supergroup 1200632 2016-07-26 19:58 DimCustomer/part-m-00003 [hdfs@localhost ~]$ hdfs dfs -ls DimCustomer
The hdfs dfs -cat command below will display the first 10 records in the first partition on the HDFS.
[hdfs@localhost ~]$ hdfs dfs -cat DimCustomer/part-m-00000|head 11000,26,AW00011000,null,Jon,V,Yang,false,1971-10-06,M,null,M,[email protected],90000.0000,2,0,Bachelors,Licenciatura,Bac + 4,Professional,Profesional,Cadre,1,0,3761 N. 14th St,null,1 (11) 500 555-0162,2011-01-19,1-2 Miles 11001,37,AW00011001,null,Eugene,L,Huang,false,1976-05-10,S,null,M,[email protected],60000.0000,3,3,Bachelors,Licenciatura,Bac + 4,Professional,Profesional,Cadre,0,1,2243 W St.,null,1 (11) 500 555-0110,2011-01-15,0-1 Miles 11002,31,AW00011002,null,Ruben,null,Torres,false,1971-02-09,M,null,M,[email protected],60000.0000,3,3,Bachelors,Licenciatura,Bac + 4,Professional,Profesional,Cadre,1,1,5844 Linden Land,null,1 (11) 500 555-0184,2011-01-07,2-5 Miles 11003,11,AW00011003,null,Christy,null,Zhu,false,1973-08-14,S,null,F,[email protected],70000.0000,0,0,Bachelors,Licenciatura,Bac + 4,Professional,Profesional,Cadre,0,1,1825 Village Pl.,null,1 (11) 500 555-0162,2010-12-29,5-10 Miles 11004,19,AW00011004,null,Elizabeth,null,Johnson,false,1979-08-05,S,null,F,[email protected],80000.0000,5,5,Bachelors,Licenciatura,Bac + 4,Professional,Profesional,Cadre,1,4,7553 Harness Circle,null,1 (11) 500 555-0131,2011-01-23,1-2 Miles 11005,22,AW00011005,null,Julio,null,Ruiz,false,1976-08-01,S,null,M,[email protected],70000.0000,0,0,Bachelors,Licenciatura,Bac + 4,Professional,Profesional,Cadre,1,1,7305 Humphrey Drive,null,1 (11) 500 555-0151,2010-12-30,5-10 Miles 11006,8,AW00011006,null,Janet,G,Alvarez,false,1976-12-02,S,null,F,[email protected],70000.0000,0,0,Bachelors,Licenciatura,Bac + 4,Professional,Profesional,Cadre,1,1,2612 Berry Dr,null,1 (11) 500 555-0184,2011-01-24,5-10 Miles 11007,40,AW00011007,null,Marco,null,Mehta,false,1969-11-06,M,null,M,[email protected],60000.0000,3,3,Bachelors,Licenciatura,Bac + 4,Professional,Profesional,Cadre,1,2,942 Brook Street,null,1 (11) 500 555-0126,2011-01-09,0-1 Miles 11008,32,AW00011008,null,Rob,null,Verhoff,false,1975-07-04,S,null,F,[email protected],60000.0000,4,4,Bachelors,Licenciatura,Bac + 4,Professional,Profesional,Cadre,1,3,624 Peabody Road,null,1 (11) 500 555-0164,2011-01-25,10+ Miles 11009,25,AW00011009,null,Shannon,C,Carlson,false,1969-09-29,S,null,M,[email protected],70000.0000,0,0,Bachelors,Licenciatura,Bac + 4,Professional,Profesional,Cadre,0,1,3839 Northgate Road,null,1 (11) 500 555-0110,2011-01-27,5-10 Miles [hdfs@localhost ~]$
Next Steps
Please experiment with different tables.
Check out these other tips and tutorials on T-SQL on MSSQLTips.com.






About the author
 Dr. Dallas Snider is an Assistant Professor in the Computer Science Department at the University of West Florida and has 18+ years of SQL experience.
Dr. Dallas Snider is an Assistant Professor in the Computer Science Department at the University of West Florida and has 18+ years of SQL experience.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2016-08-29
