By: Simon Liew | Updated: 2016-09-19 | Comments (7) | Related: 1 | 2 | 3 | 4 | 5 | 6 | > Functions System
Problem
SQL Server Developers have a variety of innovative ways to use the COUNT function in SQL Server. Often times the assumption is that one syntax provides better performance than the others. This tip will explain the differences between the following COUNT function varieties: COUNT(*) vs. COUNT(1) vs. COUNT(column_name) to determine if there is a performance difference.
Solution
There are more efficient ways than using the COUNT() function if the goal is just to retrieve the total row count from a table. One way is to retrieve the row count directly from SQL Server sys.partitions DMV. But most of the time, the COUNT function is still used when counting a subset of rows based on filter criteria specified with in the WHERE clause of a T-SQL statement.
In terms of behavior, COUNT(1) gets converted into COUNT(*) by SQL Server, so there is no difference between these. The 1 is a literal, so a COUNT('whatever') is treated as equivalent.
COUNT(column_name) behaves differently. If the column_name definition is NOT NULL, this gets converted to COUNT(*). If the column_name definition allows NULLs, then SQL Server needs to access the specific column to count the non-null values on the column.
COUNT(*) vs. COUNT(1) vs. COUNT(column_name) Performance Comparison
A test table is created in SQL Server 2016 Developer Edition on RTM CU1.
SET NOCOUNT ON; CREATE TABLE #Count (ID INT IDENTITY(1,1) PRIMARY KEY CLUSTERED , ColumnWithNulls CHAR(100) NULL DEFAULT 'Allow NULLs' , ColumnWithNoNulls CHAR(100) NOT NULL DEFAULT 'Do not allow NULLs' , LargeColumn CHAR(5000) NOT NULL DEFAULT 'Large column'); GO CREATE NONCLUSTERED INDEX NCI_Count_ColumnWithNoNulls ON #Count (ColumnWithNoNulls) GO INSERT INTO #Count DEFAULT VALUES GO 10000 UPDATE #Count SET ColumnWithNulls = NULL WHERE ID % 2 = 0 GO
Here are a few COUNT query runs with row counts. Note: the above code creates 5000 records and 2500 of the records have a NULL value for column ColumnWithNulls.
| Query |
Row Count |
|---|---|
| SELECT COUNT(*) FROM #Count WHERE ID > 5000 | 5000 |
| SELECT COUNT(1) FROM #Count WHERE ID > 5000 | 5000 |
| SELECT COUNT(LargeColumn) FROM #Count WHERE ID > 5000 | 5000 |
| SELECT COUNT(ColumnWithNulls) FROM #Count WHERE ID > 5000 | 2500 |
Interpretation of Results
SELECT COUNT(*)
Looking at the execution plan, the Aggregate operation AggType is countstar and the ScalarString is Count(*). SQL Server is actually pretty smart as it can choose an efficient route to get the record count. In this case, there is a clustered index and a non-clustered index which does not allow NULL. SQL Server uses index NCI_Count_ColumnWithNonNulls and performs a smaller index scan to get the table row count.
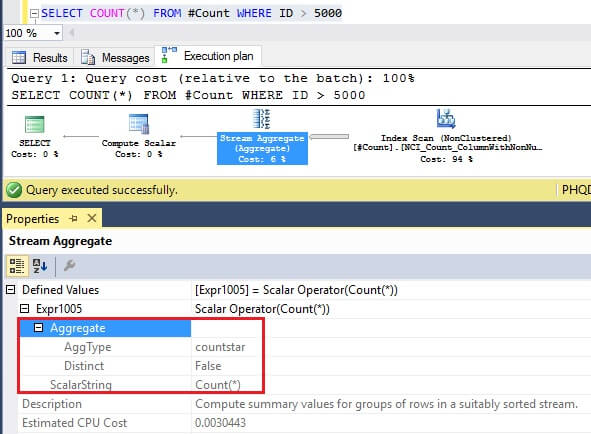
SELECT COUNT(1)
In this execution plan, COUNT(1) gets converted to use AggType countstar and ScalarString is Count(*).
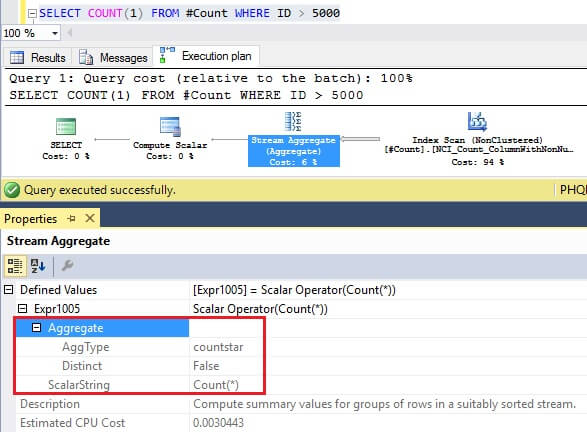
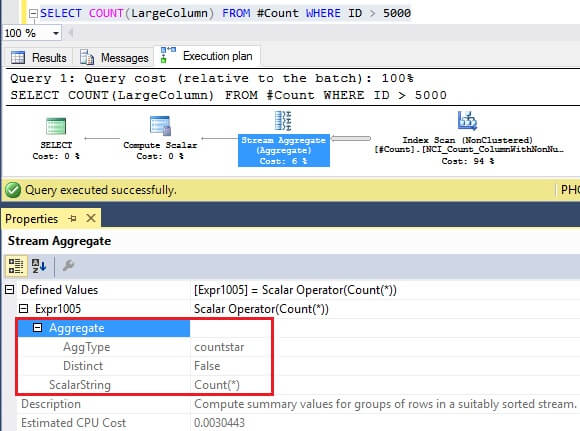
SELECT COUNT(LargeColumn)
There is no index defined on column LargeColumn, but this column definition does not allow NULLs. When a count is performed on this column, SQL Server then uses COUNT(*) and has the flexibility to choose a path it deems efficient to return the row count.
In this case, SQL Server can still maintain a scan on the nonclustered index NCI_Count_ColumnWithNoNulls to get the table row count.
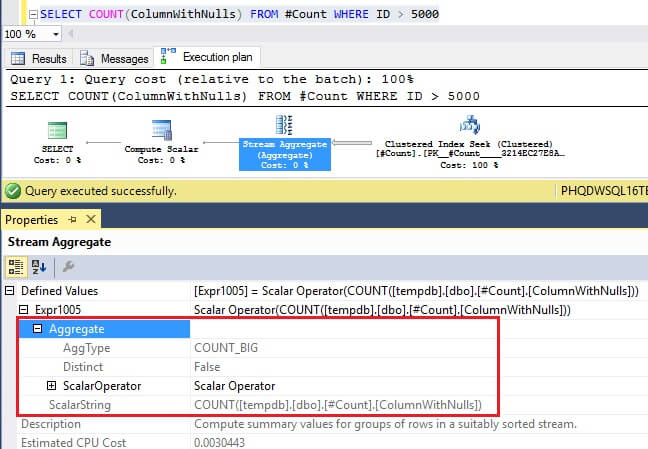
SELECT COUNT(ColumnWithNulls)
There is no index defined on column ColumnWithNulls and the column definition allows NULLs. SQL Server performs a count on the column using the clustered index. This would make sense because SQL Server needs to exclude counting rows with NULLs, so it will need to access all rows in the column.
The COUNT function itself is converted to use AggType COUNT_BIG. Typically, you would want to create a nonclustered index here, so that SQL Server would be able to perform a scan on a smaller index.
Summary
Typically I would recommend using COUNT(*) instead of many other options as it is also what SQL Server interprets. There is no performance gain by specifying a literal in the COUNT function.
COUNT(column_name) is applicable when the row count should exclude null values from the table, but if the column_name definition does not allow NULLs, then it is equivalent to COUNT(*).
Next Steps
- Keep these performance tests in mind next time you are coding to capture a row count.
- Check out these resources:






About the author
 Simon Liew is an independent SQL Server Consultant in Sydney, Australia. He is a Microsoft Certified Master for SQL Server 2008 and holds a Master’s Degree in Distributed Computing.
Simon Liew is an independent SQL Server Consultant in Sydney, Australia. He is a Microsoft Certified Master for SQL Server 2008 and holds a Master’s Degree in Distributed Computing.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2016-09-19
