By: John Miner | Updated: 2016-11-28 | Comments (6) | Related: > Azure
Problem
Azure SQL Database is a Platform As A Service (PAAS)
offering from Microsoft. It is really great for databases that are less than or
equal to 1 TB in size or larger databases that can be sharded (split) into smaller
ones that meet this requirement. Here are the sizing
details for both single and elastic Azure SQL Databases.
Many commercial off the shelf systems (COTS)
contain modules that you can buy. For instance, a given SAP R/3 installation might
have human resource, plant maintenance, material management, project systems, production
planning, quality management, sales and distribution, financial accounting, asset
accounting and fund management modules. It would not be uncommon for the database
developer to query multiple related databases from a single database for reporting.
How can this same business requirement be solved
with Azure SQL database?
Solution
Microsoft has provided the database developer with elastic database query that allows multiple databases to be accessed from a single end point. Before the release of this feature, an extract, transform and load (ETL) job would be required to duplicate the data.
Business Problem
This article continues with the Big Jon Investments sample database. Please
see my article on
Azure
Create Database Copy for more details on how to setup this environment.
Like most companies, the business owners have decided to change the requirements
of the copied database. Instead of capturing cumulative data for the
GSPC mutual fund, they only want to save off the current monthly data. A new
database that leverages elastic database queries will be created to join the data
into one logical view.
Preparing Data
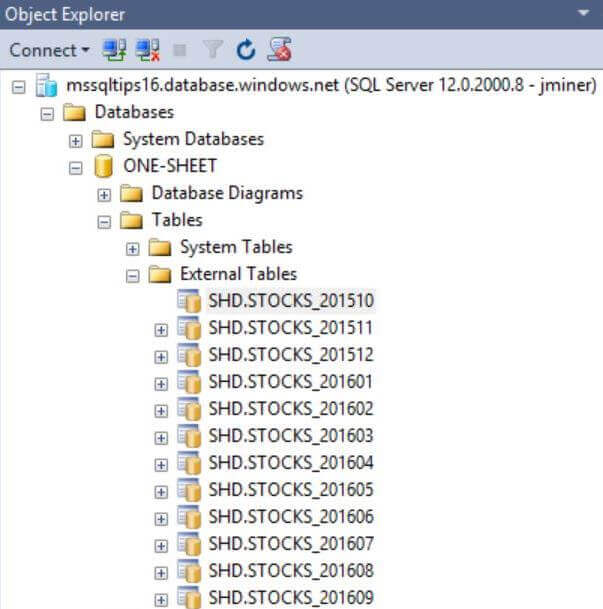
The image below shows the current proof of concept environment. The [PORTFOLIO-201510] database contains just October information and the [PORTFOLIO-201511] database contains both October and November information. This trend continues until the [PORTFOLIO-201609] database has 12 months of cumulative data.
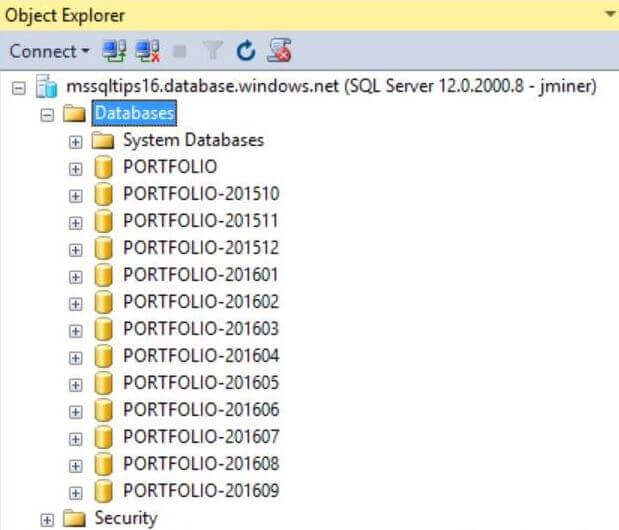
How can we reduce the amount of data in
each Azure SQL Database (COPY) to one month?
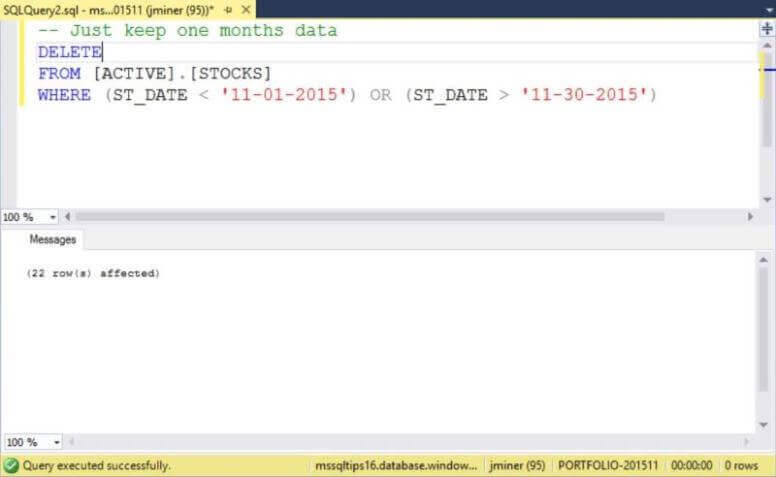
One way to accomplish this goal is to write a custom DELETE statement for each database.
The image below is the correct statement to leave just November data in the [PORTFOLIO-201511]
database.
Database Setup
The syntax for querying related databases (vertical partitioning) from one Azure
SQL database using
elastic database query resembles
polybase.
However, it is not!
PolyBase is a technology that accesses and combines both non-relational and relational
data from within SQL Server 2016. Query results can be moved from either Hadoop
or Azure blob storage to a SQL Server 2016 relational table or vice versa.
To solve our business problem, we are going to work through the following steps.
- For each database, do the following:
- Create a contained database user
- Give this user [db_owner rights].
- Create a new database.
- Create a new schema.
- Create a master encryption key.
- Create a database scoped credential.
- For each database, do the following:
- Define an external data source.
- Define an external table.
- Create one view to [UNION ALL] external tables.
The transact SQL code below creates a contained database user named [USR_CROSS_DBMS] and grants that user [db_owner] rights. Manually connect to each of the twelve databases and execute the code below.
-- -- Step 1 - Execute on all databases -- -- Remove existing user DROP USER IF EXISTS [USR_CROSS_DBMS] GO -- Create new user CREATE USER USR_CROSS_DBMS WITH PASSWORD = '4WhOjG4bgIW8w7d0', DEFAULT_SCHEMA=[ACTIVE] GO -- Add user to the database owner role EXEC sp_addrolemember N'db_owner', N'USR_CROSS_DBMS' GO
When writing code, it is import that the Transact SQL is restartable. That means
the existence of an object should be checked before creating the object. Remove
any existing objects before creating a new object.
The Transact SQL code below creates a database called [ONE-SHEET], a schema
referred to as [SHD], a master encryption key and a database scoped credential
designated as [CRD_CROSS_DBMS].
For more information, see the MSDN articles on
CREATE MASTER KEY ENCRYPTION and
CREATE DATABASE
SCOPED CREDENTIAL.
-- -- Step 2 - Create new database (run from master) -- -- Delete existing database DROP DATABASE IF EXISTS [ONE-SHEET] GO -- Create new database CREATE DATABASE [ONE-SHEET] ( EDITION = 'STANDARD', SERVICE_OBJECTIVE = 'S0' ) GO -- -- Step 3 - Create new schema (run from user defined database) -- -- Delete existing schema. DROP SCHEMA IF EXISTS [SHD] GO -- Add new schema. CREATE SCHEMA [SHD] AUTHORIZATION [dbo] GO -- -- Step 4 - Create master key -- -- Drop master key IF EXISTS (SELECT * FROM sys.symmetric_keys WHERE name = '##MS_DatabaseMasterKey##') DROP MASTER KEY; -- Create master key CREATE MASTER KEY ENCRYPTION BY PASSWORD = 'Qkmof0SV3yxReKEP'; GO -- -- Step 5 - Database Credential -- -- Drop db credential IF EXISTS(SELECT * FROM sys.database_credentials WHERE name = 'CRD_CROSS_DBMS') DROP DATABASE SCOPED CREDENTIAL CRD_CROSS_DBMS ; GO -- Create db credential CREATE DATABASE SCOPED CREDENTIAL CRD_CROSS_DBMS WITH IDENTITY = 'USR_CROSS_DBMS', SECRET = '4WhOjG4bgIW8w7d0'; GO
At this point, if you followed all the directions correctly, you should have a empty database named [ONE-SHEET]. Next, we need to work on creating external data sources for each related database.
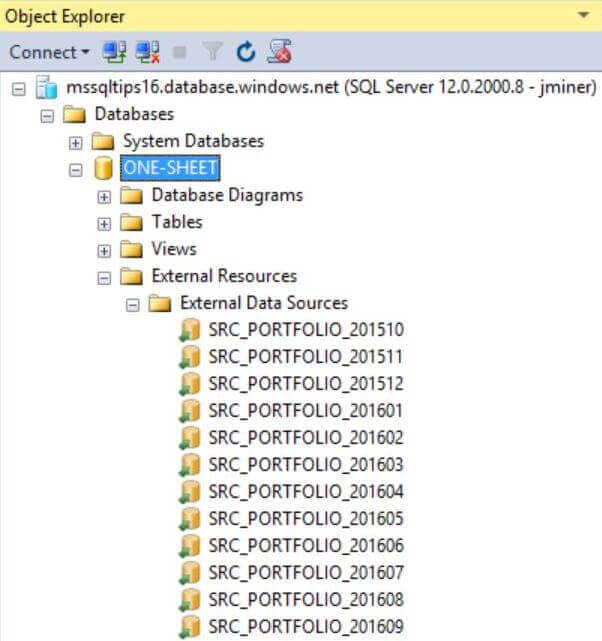
The transact SQL code below creates an external data source for each of the twelve months. Dynamic Transact SQL will be used instead of having twelve blocks of code. We will be making sure the code is restartable by removing any existing objects before creating new ones. If you have not used the sp_executesql command before, it is really great for database management scripts that need to perform work on a dynamic number of objects.
For more information on the CREATE EXTERNAL DATA SOURCE statement, please see the following MSDN article.
--
-- Step 6A - Create 12 external data sources
--
-- Variables
DECLARE @VAR_NAME1 SYSNAME;
DECLARE @VAR_NAME2 SYSNAME;
DECLARE @VAR_DATE DATETIME;
DECLARE @VAR_STMT NVARCHAR(1024);
-- Starting value
SET @VAR_DATE = '10-01-2015';
-- For each month
WHILE (@VAR_DATE < '10-01-2016')
BEGIN
-- Set object names
SET @VAR_NAME1 = 'SRC_PORTFOLIO_' + FORMAT(@VAR_DATE, 'yyyyMM');
SET @VAR_NAME2 = 'PORTFOLIO-' + FORMAT(@VAR_DATE, 'yyyyMM');
-- Drop external data src
SET @VAR_STMT = '' +
'IF EXISTS ' +
'( ' +
' SELECT * FROM sys.external_data_sources WHERE NAME = ' +
CHAR(39) + @VAR_NAME1 + CHAR(39) +
') ' +
'DROP EXTERNAL DATA SOURCE [' + @VAR_NAME1 + '];';
exec sp_executesql @VAR_STMT;
-- Create external data src
SET @VAR_STMT = '' +
'CREATE EXTERNAL DATA SOURCE [' + @VAR_NAME1 + '] ' +
'WITH ' +
'( ' +
' TYPE = RDBMS, ' +
' LOCATION = ''mssqltips16.database.windows.net'', ' +
' DATABASE_NAME = ' + CHAR(39) + @VAR_NAME2 + CHAR(39) + ', ' +
' CREDENTIAL = CRD_CROSS_DBMS' +
'); ';
EXEC sp_executesql @VAR_STMT;
-- Increment the date
SET @VAR_DATE = DATEADD(M, 1, @VAR_DATE);
END
If you followed all the directions correctly, you should have twelve external data sources. See the image below for details. Next, we need to work on creating external tables for each of the data sources.
We will use Dynamic Transact SQL to create external tables for each of the months below. Unfortunately, there is no way to define a primary key using the [ST_SYMBOL] and [ST_DATE] fields. If we were using the on premise version of SQL Server, we could automatically leverage Partitioned Views to increase query performance for certain patterns.
For more information on the CREATE EXTERNAL TABLE statement, please see the following MSDN article.
The image below shows how primary key constraints are not supported with external tables.
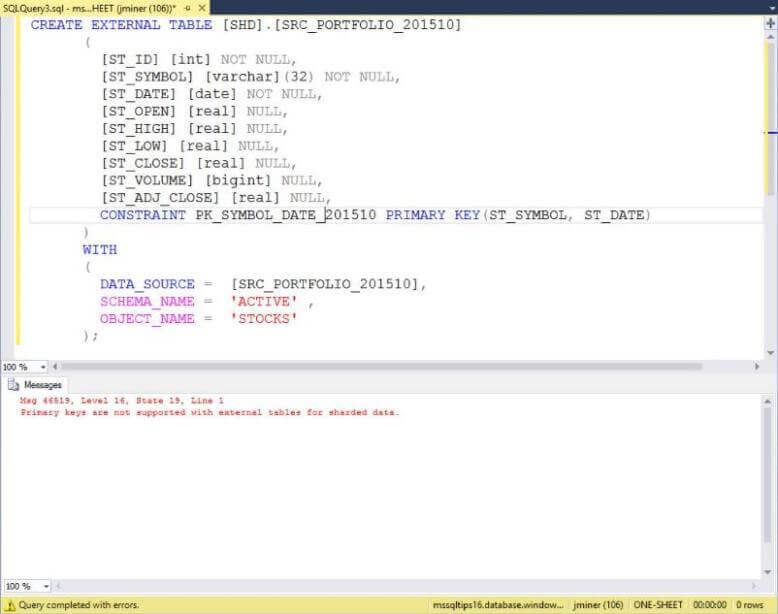
The transact SQL code below creates an external table for each of the twelve months.
--
-- Step 6B - Create 12 external tables
--
-- Variables
DECLARE @VAR_NAME1 SYSNAME;
DECLARE @VAR_NAME2 SYSNAME;
DECLARE @VAR_DATE DATETIME;
DECLARE @VAR_STMT NVARCHAR(1024);
-- Starting value
SET @VAR_DATE = '10-01-2015';
-- For each month
WHILE (@VAR_DATE < '10-01-2016')
BEGIN
-- Set object names
SET @VAR_NAME1 = 'STOCKS_' + FORMAT(@VAR_DATE, 'yyyyMM');
SET @VAR_NAME2 = 'SRC_PORTFOLIO_' + FORMAT(@VAR_DATE, 'yyyyMM') + '';
-- Drop external table
SET @VAR_STMT = '' +
'IF EXISTS ' +
'( ' +
' SELECT * FROM sys.external_tables WHERE NAME = ' +
CHAR(39) + @VAR_NAME1 + CHAR(39) +
') ' +
' DROP EXTERNAL TABLE [SHD].[' + @VAR_NAME1 + '];';
exec sp_executesql @VAR_STMT;
-- Create external table
SET @VAR_STMT = ' ' +
'CREATE EXTERNAL TABLE [SHD].[' + @VAR_NAME1 + '] ' +
'( ' +
' [ST_ID] [int] NOT NULL, ' +
' [ST_SYMBOL] [varchar](32) NOT NULL, ' +
' [ST_DATE] [date] NOT NULL, ' +
' [ST_OPEN] [real] NULL, ' +
' [ST_HIGH] [real] NULL, ' +
' [ST_LOW] [real] NULL, ' +
' [ST_CLOSE] [real] NULL, ' +
' [ST_VOLUME] [bigint] NULL, ' +
' [ST_ADJ_CLOSE] [real] NULL ' +
') ' +
'WITH ' +
'( ' +
' DATA_SOURCE = ' + @VAR_NAME2 + ', ' +
' SCHEMA_NAME = ' + CHAR(39) + 'ACTIVE' + CHAR(39) + ', ' +
' OBJECT_NAME = ' + CHAR(39) + 'STOCKS' + CHAR(39) +
'); ';
EXEC sp_executesql @VAR_STMT;
-- Increment the data
SET @VAR_DATE = DATEADD(M, 1, @VAR_DATE)
END
If you followed all the directions correctly, you should have twelve external tables. See the image below for details. Next, we need to create a view that combines all the tables together.
The transact SQL code below creates a view named [STOCKS] which is the UNION ALL of the twelve external tables.
-- -- Create view on all external tables -- -- Drop existing view DROP VIEW IF EXISTS [DBO].[STOCKS] GO -- Create new view CREATE VIEW [DBO].[STOCKS] AS SELECT * FROM [SHD].[STOCKS_201510] UNION ALL SELECT * FROM [SHD].[STOCKS_201511] UNION ALL SELECT * FROM [SHD].[STOCKS_201512] UNION ALL SELECT * FROM [SHD].[STOCKS_201601] UNION ALL SELECT * FROM [SHD].[STOCKS_201602] UNION ALL SELECT * FROM [SHD].[STOCKS_201603] UNION ALL SELECT * FROM [SHD].[STOCKS_201604] UNION ALL SELECT * FROM [SHD].[STOCKS_201605] UNION ALL SELECT * FROM [SHD].[STOCKS_201606] UNION ALL SELECT * FROM [SHD].[STOCKS_201607] UNION ALL SELECT * FROM [SHD].[STOCKS_201608] UNION ALL SELECT * FROM [SHD].[STOCKS_201609] GO
There can be a lot of Transact SQL coding to setup the Azure SQL database for elastic queries. In our example, we want to combine all the monthly data into one view. However, once the external table is defined, a database developer can start writing queries using both the local and external tables.
Executing Elastic Queries
Getting back to our business problem, you have been asked to pull summary data for each month for the GSPC mutual fund. The query below returns the high trading value, low trading value, average close value and the number of trading days for a given month. This query will supply the business owners with their required data.
--
-- Show summary statistics
--
SELECT
year(st_date) as st_year,
month(st_date) as st_month,
max(st_high) as st_high,
min(st_low) as st_low,
avg(st_close) as st_avg_close,
count(*) as st_days
FROM
[DBO].[STOCKS]
GROUP BY
year(st_date),
month(st_date)
ORDER BY
year(st_date),
month(st_date)
GO
The image below shows the results of the above query.
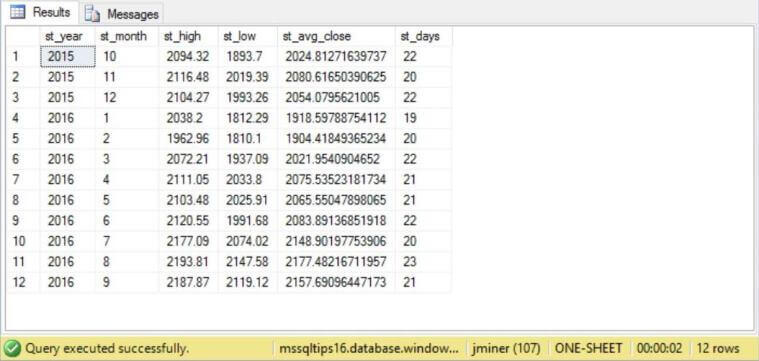
We can see that elastics query can SELECT data from multiple Azure SQL Databases
and return the results. However, on premise queries can actually INSERT, DELETE
and UPDATE data in related databases using the three part notation: database name,
schema name and table name.
Can external tables support such DML actions?
The answer to this question is not at this time! The image below shows a
simple INSERT statement that fails.
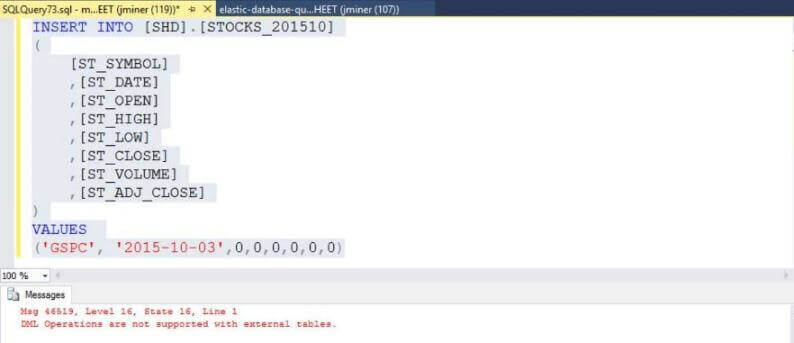
Summary
Big Jon's Investments wanted to modify the proof of concept project in which
stock portfolio data was stored in a table in Azure on a daily basis. Each database
was changed to hold one month's worth of data. A parent database was created to
reference all the child databases by using external tables. A view was created to
UNION ALL the data into one object. Last but not least, an elastic database query
was used to return summary data on all of the trading days grouped by month.
Some of the current limitations of external tables is the inability to define constraints
and/or apply data manipulation statements. However, this new feature closes a gap
that previously existed. The database developer can now reference both local and
remote tables when creating Azure SQL database queries.
If you want to learn more, check out Azure
Documentation on this subject.
Next Steps
- Right now, we are pulling just summary data for the GSPC mutual fund. In
real life, the stock price is always changing from when the market opens at
9:30 am and closes at 4:00 pm. This pattern lends itself to a current day database
that having a large number of inserts and other day's databases that might be
queried on an ad-hoc basis. Such a pattern shows an imbalance of resource usage
across a set of sharded (horizontally partitioned) databases.
How can we implement elastic database pools for such databases?
- There are many other techniques that can be used to perform horizontal partitioning.
One technique is database sharding. Microsoft has released the Azure SQL database
elastic scale library for .NET which is a sharding solution.
How can we take advantage of the library for our own business problems?
- There are many situations in which you need to change the schema for a set
of database shards. Is there a way to perform this action without connecting
to each database to make the necessary DDL changes?
How can we take advantage of elastic database jobs for our own business problems?






About the author
 John Miner is a Data Architect at Insight Digital Innovation helping corporations solve their business needs with various data platform solutions.
John Miner is a Data Architect at Insight Digital Innovation helping corporations solve their business needs with various data platform solutions.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2016-11-28
