By: Dallas Snider | Updated: 2016-11-29 | Comments | Related: More > Big Data
Problem
I already have data imported from a SQL Server table to a file on the Hadoop Distributed File System. How can I use Sqoop to append new records in SQL Server to the existing HDFS file?
Solution
Apache's Sqoop is designed to bulk-load data from relational databases to the Hadoop Distributed File System (HDFS). For this tip we will examine a Sqoop Linux command that will append data to an existing table on the HDFS. We will start from the beginning with a simple Sqoop import to create a new HDFS file, followed by an import to append new records. This tip is written using SQL Server 2016 and a Cloudera virtual machine with a Linux operating system.
Let's first perform the simple table import. We will create our example table named tblSales in a SQL Server database named MSSQLTips using the T-SQL below. After creating the table we will insert 20 rows into the table.
create table dbo.tblSales ( pkSales integer identity(1,1) not null primary key, salesDate date not null, salesAmount money ) insert into tblSales values ((getdate()-40), 1.01) insert into tblSales values ((getdate()-39), 2.02) insert into tblSales values ((getdate()-38), 3.03) insert into tblSales values ((getdate()-37), 4.04) insert into tblSales values ((getdate()-36), 5.05) insert into tblSales values ((getdate()-35), 6.06) insert into tblSales values ((getdate()-34), 7.07) insert into tblSales values ((getdate()-33), 8.08) insert into tblSales values ((getdate()-32), 9.09) insert into tblSales values ((getdate()-31), 10.10) insert into tblSales values ((getdate()-30), 11.11) insert into tblSales values ((getdate()-29), 12.12) insert into tblSales values ((getdate()-28), 13.13) insert into tblSales values ((getdate()-27), 14.14) insert into tblSales values ((getdate()-26), 15.15) insert into tblSales values ((getdate()-25), 16.16) insert into tblSales values ((getdate()-24), 17.17) insert into tblSales values ((getdate()-23), 18.18) insert into tblSales values ((getdate()-22), 19.19) insert into tblSales values ((getdate()-21), 20.20) select * from dbo.tblSales
The results from the SELECT statement above are shown here.
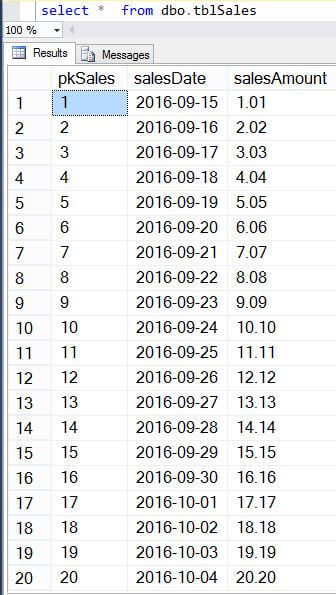
Next, we will perform a simple table import using the Sqoop command shown below.
sqoop import --connect 'jdbc:sqlserver://aaa.bbb.ccc.ddd:pppp;databasename=MSSQLTips' --username 'sqoopLogin' -P --table tblSales
The above command is contained in a script file named sqoopCommandInitial.sh. Details about how to perform this import can be found in the previous tip Use Sqoop to Load Data from a SQL Server Table to a Hadoop Distributed File System.
The output from the above command is shown below.[hdfs@localhost:/mssqltips]$ ./sqoopCommandInitial.sh 16/10/25 19:57:56 INFO sqoop.Sqoop: Running Sqoop version: 1.4.5-cdh5.2.0 Enter password: 16/10/25 19:57:59 INFO manager.SqlManager: Using default fetchSize of 1000 16/10/25 19:57:59 INFO tool.CodeGenTool: Beginning code generation 16/10/25 19:57:59 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM [tblSales] AS t WHERE 1=0 16/10/25 19:58:00 INFO orm.CompilationManager: HADOOP_MAPRED_HOME is /usr/lib/hadoop-0.20-mapreduce Note: /tmp/sqoop-training/compile/4ef4118552482903c5f4464c7a098c69/tblSales.java uses or overrides a deprecated API. Note: Recompile with -Xlint:deprecation for details. 16/10/25 19:58:04 INFO orm.CompilationManager: Writing jar file: /tmp/sqoop-training/compile/4ef4118552482903c5f4464c7a098c69/tblSales.jar 16/10/25 19:58:04 INFO mapreduce.ImportJobBase: Beginning import of tblSales 16/10/25 19:58:08 WARN mapred.JobClient: Use GenericOptionsParser for parsing the arguments. Applications should implement Tool for the same. 16/10/25 19:58:12 INFO db.DBInputFormat: Using read commited transaction isolation 16/10/25 19:58:12 INFO db.DataDrivenDBInputFormat: BoundingValsQuery: SELECT MIN([pkSales]), MAX([pkSales]) FROM [tblSales] 16/10/25 19:58:12 INFO mapred.JobClient: Running job: job_201609280401_0015 16/10/25 19:58:13 INFO mapred.JobClient: map 0% reduce 0% 16/10/25 19:58:36 INFO mapred.JobClient: map 50% reduce 0% 16/10/25 19:58:52 INFO mapred.JobClient: map 75% reduce 0% 16/10/25 19:58:53 INFO mapred.JobClient: map 100% reduce 0% 16/10/25 19:58:55 INFO mapred.JobClient: Job complete: job_201609280401_0015 16/10/25 19:58:55 INFO mapred.JobClient: Counters: 23 16/10/25 19:58:55 INFO mapred.JobClient: File System Counters 16/10/25 19:58:55 INFO mapred.JobClient: FILE: Number of bytes read=0 16/10/25 19:58:55 INFO mapred.JobClient: FILE: Number of bytes written=1188424 16/10/25 19:58:55 INFO mapred.JobClient: FILE: Number of read operations=0 16/10/25 19:58:55 INFO mapred.JobClient: FILE: Number of large read operations=0 16/10/25 19:58:55 INFO mapred.JobClient: FILE: Number of write operations=0 16/10/25 19:58:55 INFO mapred.JobClient: HDFS: Number of bytes read=438 16/10/25 19:58:55 INFO mapred.JobClient: HDFS: Number of bytes written=422 16/10/25 19:58:55 INFO mapred.JobClient: HDFS: Number of read operations=4 16/10/25 19:58:55 INFO mapred.JobClient: HDFS: Number of large read operations=0 16/10/25 19:58:55 INFO mapred.JobClient: HDFS: Number of write operations=4 16/10/25 19:58:55 INFO mapred.JobClient: Job Counters 16/10/25 19:58:55 INFO mapred.JobClient: Launched map tasks=4 16/10/25 19:58:55 INFO mapred.JobClient: Total time spent by all maps in occupied slots (ms)=67805 16/10/25 19:58:55 INFO mapred.JobClient: Total time spent by all reduces in occupied slots (ms)=0 16/10/25 19:58:55 INFO mapred.JobClient: Total time spent by all maps waiting after reserving slots (ms)=0 16/10/25 19:58:55 INFO mapred.JobClient: Total time spent by all reduces waiting after reserving slots (ms)=0 16/10/25 19:58:55 INFO mapred.JobClient: Map-Reduce Framework 16/10/25 19:58:55 INFO mapred.JobClient: Map input records=20 16/10/25 19:58:55 INFO mapred.JobClient: Map output records=20 16/10/25 19:58:55 INFO mapred.JobClient: Input split bytes=438 16/10/25 19:58:55 INFO mapred.JobClient: Spilled Records=0 16/10/25 19:58:55 INFO mapred.JobClient: CPU time spent (ms)=6570 16/10/25 19:58:55 INFO mapred.JobClient: Physical memory (bytes) snapshot=474869760 16/10/25 19:58:55 INFO mapred.JobClient: Virtual memory (bytes) snapshot=2949660672 16/10/25 19:58:55 INFO mapred.JobClient: Total committed heap usage (bytes)=127401984 16/10/25 19:58:55 INFO mapreduce.ImportJobBase: Transferred 422 bytes in 49.1076 seconds (8.5934 bytes/sec) 16/10/25 19:58:55 INFO mapreduce.ImportJobBase: Retrieved 20 records. [hdfs@localhost:/mssqltips]$
After running the Sqoop command, let's verify that the 20 rows were imported correctly into the HDFS. As we can see on the last line above, Sqoop states that 20 records were retrieved. We can execute the following command to get a row count of the new HDFS file.
[hdfs@localhost:/mssqltips]$ hdfs dfs -cat tblSales/part* |wc -l 20 [hdfs@localhost:/mssqltips]$
The following command will display all of the data that was loaded.
[hdfs@localhost:/mssqltips]$ hdfs dfs -cat tblSales/part* 1,2016-09-15,1.0100 2,2016-09-16,2.0200 3,2016-09-17,3.0300 4,2016-09-18,4.0400 5,2016-09-19,5.0500 6,2016-09-20,6.0600 7,2016-09-21,7.0700 8,2016-09-22,8.0800 9,2016-09-23,9.0900 10,2016-09-24,10.1000 11,2016-09-25,11.1100 12,2016-09-26,12.1200 13,2016-09-27,13.1300 14,2016-09-28,14.1400 15,2016-09-29,15.1500 16,2016-09-30,16.1600 17,2016-10-01,17.1700 18,2016-10-02,18.1800 19,2016-10-03,19.1900 20,2016-10-04,20.2000 [hdfs@localhost:/mssqltips]$
Now that our initial set of data was loaded correctly, let's append newer SQL Server data to the existing HDFS file. The T-SQL code below will insert 20 more records into our SQL Server table.
insert into dbo.tblSales values ((getdate()-20), 21.21) insert into dbo.tblSales values ((getdate()-19), 22.22) insert into dbo.tblSales values ((getdate()-18), 23.23) insert into dbo.tblSales values ((getdate()-17), 24.24) insert into dbo.tblSales values ((getdate()-16), 25.25) insert into dbo.tblSales values ((getdate()-15), 26.26) insert into dbo.tblSales values ((getdate()-14), 27.27) insert into dbo.tblSales values ((getdate()-13), 28.28) insert into dbo.tblSales values ((getdate()-12), 29.29) insert into dbo.tblSales values ((getdate()-11), 30.30) insert into dbo.tblSales values ((getdate()-10), 31.31) insert into dbo.tblSales values ((getdate()-9), 32.32) insert into dbo.tblSales values ((getdate()-8), 33.33) insert into dbo.tblSales values ((getdate()-7), 34.34) insert into dbo.tblSales values ((getdate()-6), 35.35) insert into dbo.tblSales values ((getdate()-5), 36.36) insert into dbo.tblSales values ((getdate()-4), 37.37) insert into dbo.tblSales values ((getdate()-3), 38.38) insert into dbo.tblSales values ((getdate()-2), 39.39) insert into dbo.tblSales values ((getdate()-1), 40.40)
Now we are ready to execute the Sqoop import to append the new data to the existing HDFS file. The Sqoop command we will examine is listed below and we will break down each argument in the following bullet points. Please note that the command is supposed to be on one complete line or with the backslash (the Linux command line continuation character) at the end of each line except the last. The command is stored in a file named sqoopCommandAppend.sh for ease for reuse.
[hdfs@localhost:/mssqltips]$ cat ./sqoopCommandAppend.sh sqoop import --connect 'jdbc:sqlserver://aaa.bbb.ccc.ddd:pppp;databasename=MSSQLTips' --username 'sqoopLogin' -P --table tblSales --append --check-column pkSales --incremental append --last-value 20 [hdfs@localhost:/mssqltips]$
- sqoop import - The executable is named sqoop and we are instructing it to import the data from a table or view from a database to HDFS.
- --connect - With the --connect argument, we are passing in the jdbc connect string for SQL Server. In this case, we use the IP address, port number, and database name.
- --username - In this example, the user name is a SQL Server login, not a Windows login. Our database is set up to authenticate in mixed mode. We have a server login named sqoopLogin, and we have a database user name sqoopUser which is a member of the db_datareader role and has a default schema of dbo.
- -P - This will prompt the command line user for the password. If Sqoop is rarely executed, this might be a good option. There are multiple other ways to automatically pass the password to the command, but we are trying to keep it simple for this tip.
- --table - This is where we pass in the name of the SQL Server table.
- --append - This parameter tells Sqoop to append the data to the existing file.
The next three arguments are used by Sqoop to perform an incremental import. We are telling Sqoop to check a specific column and import rows with a column value greater than what is specified.
- --check-column pkSales - This argument provides the column to check. For our example, it is pkSales.
- --incremental append - The append argument to the --incremental parameter tells Sqoop to expect an increasing row ID value. Another argument to the --incremental parameter is lastmodified, where Sqoop is expecting a date value to be passed to it.
- --last-value 20 - This is the max value for the row ID column in the existing HDFS file when used with the append argument above. It can also be considered as the max value in the SQL Server table after the last import. For this tip, the last value is 20. When using the lastmodified argument, then the most recent date in the HDFS file should be used.
Next we will execute the script. The output is shown below.
[hdfs@localhost:/mssqltips]$ ./sqoopCommandAppend.sh 16/10/26 15:25:21 INFO sqoop.Sqoop: Running Sqoop version: 1.4.5-cdh5.2.0 Enter password: 16/10/26 15:25:58 INFO manager.SqlManager: Using default fetchSize of 1000 16/10/26 15:25:58 INFO tool.CodeGenTool: Beginning code generation 16/10/26 15:25:59 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM [tblSales] AS t WHERE 1=0 16/10/26 15:26:00 INFO orm.CompilationManager: HADOOP_MAPRED_HOME is /usr/lib/hadoop-0.20-mapreduce Note: /tmp/sqoop-training/compile/96c0d58b6ab9358d62dd1ed1d5b9170e/tblSales.java uses or overrides a deprecated API. Note: Recompile with -Xlint:deprecation for details. 16/10/26 15:26:04 INFO orm.CompilationManager: Writing jar file: /tmp/sqoop-training/compile/96c0d58b6ab9358d62dd1ed1d5b9170e/tblSales.jar 16/10/26 15:26:11 INFO tool.ImportTool: Maximal id query for free form incremental import: SELECT MAX([pkSales]) FROM tblSales 16/10/26 15:26:11 INFO tool.ImportTool: Incremental import based on column [pkSales] 16/10/26 15:26:11 INFO tool.ImportTool: Lower bound value: 20 16/10/26 15:26:11 INFO tool.ImportTool: Upper bound value: 40 16/10/26 15:26:11 INFO mapreduce.ImportJobBase: Beginning import of tblSales 16/10/26 15:26:13 WARN mapred.JobClient: Use GenericOptionsParser for parsing the arguments. Applications should implement Tool for the same. 16/10/26 15:26:21 INFO db.DBInputFormat: Using read commited transaction isolation 16/10/26 15:26:21 INFO db.DataDrivenDBInputFormat: BoundingValsQuery: SELECT MIN([pkSales]), MAX([pkSales]) FROM [tblSales] WHERE ( [pkSales] > 20 AND [pkSales] <= 40 ) 16/10/26 15:26:22 INFO mapred.JobClient: Running job: job_201609280401_0016 16/10/26 15:26:23 INFO mapred.JobClient: map 0% reduce 0% 16/10/26 15:26:58 INFO mapred.JobClient: map 50% reduce 0% 16/10/26 15:27:12 INFO mapred.JobClient: map 100% reduce 0% 16/10/26 15:27:16 INFO mapred.JobClient: Job complete: job_201609280401_0016 16/10/26 15:27:16 INFO mapred.JobClient: Counters: 23 16/10/26 15:27:16 INFO mapred.JobClient: File System Counters 16/10/26 15:27:16 INFO mapred.JobClient: FILE: Number of bytes read=0 16/10/26 15:27:16 INFO mapred.JobClient: FILE: Number of bytes written=1196724 16/10/26 15:27:16 INFO mapred.JobClient: FILE: Number of read operations=0 16/10/26 15:27:16 INFO mapred.JobClient: FILE: Number of large read operations=0 16/10/26 15:27:16 INFO mapred.JobClient: FILE: Number of write operations=0 16/10/26 15:27:16 INFO mapred.JobClient: HDFS: Number of bytes read=441 16/10/26 15:27:16 INFO mapred.JobClient: HDFS: Number of bytes written=440 16/10/26 15:27:16 INFO mapred.JobClient: HDFS: Number of read operations=4 16/10/26 15:27:16 INFO mapred.JobClient: HDFS: Number of large read operations=0 16/10/26 15:27:16 INFO mapred.JobClient: HDFS: Number of write operations=4 16/10/26 15:27:16 INFO mapred.JobClient: Job Counters 16/10/26 15:27:16 INFO mapred.JobClient: Launched map tasks=4 16/10/26 15:27:16 INFO mapred.JobClient: Total time spent by all maps in occupied slots (ms)=86239 16/10/26 15:27:16 INFO mapred.JobClient: Total time spent by all reduces in occupied slots (ms)=0 16/10/26 15:27:16 INFO mapred.JobClient: Total time spent by all maps waiting after reserving slots (ms)=0 16/10/26 15:27:16 INFO mapred.JobClient: Total time spent by all reduces waiting after reserving slots (ms)=0 16/10/26 15:27:16 INFO mapred.JobClient: Map-Reduce Framework 16/10/26 15:27:16 INFO mapred.JobClient: Map input records=20 16/10/26 15:27:16 INFO mapred.JobClient: Map output records=20 16/10/26 15:27:16 INFO mapred.JobClient: Input split bytes=441 16/10/26 15:27:16 INFO mapred.JobClient: Spilled Records=0 16/10/26 15:27:16 INFO mapred.JobClient: CPU time spent (ms)=10930 16/10/26 15:27:16 INFO mapred.JobClient: Physical memory (bytes) snapshot=435695616 16/10/26 15:27:16 INFO mapred.JobClient: Virtual memory (bytes) snapshot=2949709824 16/10/26 15:27:16 INFO mapred.JobClient: Total committed heap usage (bytes)=127401984 16/10/26 15:27:16 INFO mapreduce.ImportJobBase: Transferred 440 bytes in 64.5586 seconds (6.8155 bytes/sec) 16/10/26 15:27:16 INFO mapreduce.ImportJobBase: Retrieved 20 records. 16/10/26 15:27:16 INFO util.AppendUtils: Appending to directory tblSales 16/10/26 15:27:16 INFO util.AppendUtils: Using found partition 4 16/10/26 15:27:16 INFO tool.ImportTool: Incremental import complete! To run another incremental import of all data following this import, supply the following arguments: 16/10/26 15:27:16 INFO tool.ImportTool: --incremental append 16/10/26 15:27:16 INFO tool.ImportTool: --check-column pkSales 16/10/26 15:27:16 INFO tool.ImportTool: --last-value 40 16/10/26 15:27:16 INFO tool.ImportTool: (Consider saving this with 'sqoop job --create') [hdfs@localhost:/mssqltips]$
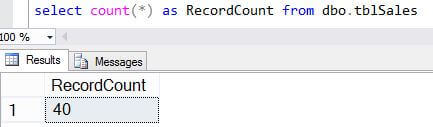
In the next to last line above, Sqoop states the last value is now 40 which is what we were expecting since our primary key column in our SQL Server table has a maximum value of 40. Finally, we will examine the contents of our HDFS file using the following commands. Notice that we have 40 rows of data which is correct based on the current state of our SQL Server table.
[hdfs@localhost:/mssqltips]$ hdfs dfs -cat tblSales/part* |wc -l 40 [hdfs@localhost:/mssqltips]$ hdfs dfs -cat tblSales/part* 1,2016-09-15,1.0100 2,2016-09-16,2.0200 3,2016-09-17,3.0300 4,2016-09-18,4.0400 5,2016-09-19,5.0500 6,2016-09-20,6.0600 7,2016-09-21,7.0700 8,2016-09-22,8.0800 9,2016-09-23,9.0900 10,2016-09-24,10.1000 11,2016-09-25,11.1100 12,2016-09-26,12.1200 13,2016-09-27,13.1300 14,2016-09-28,14.1400 15,2016-09-29,15.1500 16,2016-09-30,16.1600 17,2016-10-01,17.1700 18,2016-10-02,18.1800 19,2016-10-03,19.1900 20,2016-10-04,20.2000 21,2016-10-05,21.2100 22,2016-10-06,22.2200 23,2016-10-07,23.2300 24,2016-10-08,24.2400 25,2016-10-09,25.2500 26,2016-10-10,26.2600 27,2016-10-11,27.2700 28,2016-10-12,28.2800 29,2016-10-13,29.2900 30,2016-10-14,30.3000 31,2016-10-15,31.3100 32,2016-10-16,32.3200 33,2016-10-17,33.3300 34,2016-10-18,34.3400 35,2016-10-19,35.3500 36,2016-10-20,36.3600 37,2016-10-21,37.3700 38,2016-10-22,38.3800 39,2016-10-23,39.3900 40,2016-10-24,40.4000 [hdfs@localhost:/mssqltips]$
Next Steps
Please be careful when using Sqoop to append an existing HDFS file because you can easily import duplicate data. Also, you should experiment with different tables and append options. Finally, please check out these other tips and tutorials on T-SQL on MSSQLTips.com.
- SQL Server Big Data Tips
- Export from Hadoop File System to a SQL Server Database Table
- Load SQL Server T-SQL Query Results to Hadoop Using Sqoop
- Sqoop Runtime Exception: Cannot Load SQL Server Driver
- Use Sqoop to Load Data from a SQL Server Table to a Hadoop Distributed File System
- Using Sqoop WHERE Argument to Filter Data from a SQL Server
- Our complete tutorial list






About the author
 Dr. Dallas Snider is an Assistant Professor in the Computer Science Department at the University of West Florida and has 18+ years of SQL experience.
Dr. Dallas Snider is an Assistant Professor in the Computer Science Department at the University of West Florida and has 18+ years of SQL experience.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2016-11-29
