By: Jeffrey Yao | Updated: 2017-04-21 | Comments (1) | Related: > Backup
Problem
There are times when a SQL Server DBA needs to backup (both schema and data) one or more tables out of a large database, so the table can be restored/recreated in another environment. What kind of methods can I use to backup a SQL Server table?
Solution
We know there is no native table backup command in SQL Server, only the backup database command. There can be many reasons why this is the case such as a table may be dependent on other tables via foreign key relationships, meaning a table’s schema integrity will be compromised if we only backup one table without its related tables.
But there are many times, a table is standalone or we do not care about anything other than the data and the table structure. In such scenarios, there is one common way to script out the table with the data. This can be done via SQL Server Management Studio (SSMS), i.e. right-click the chosen Database > Tasks > Generate Scripts.
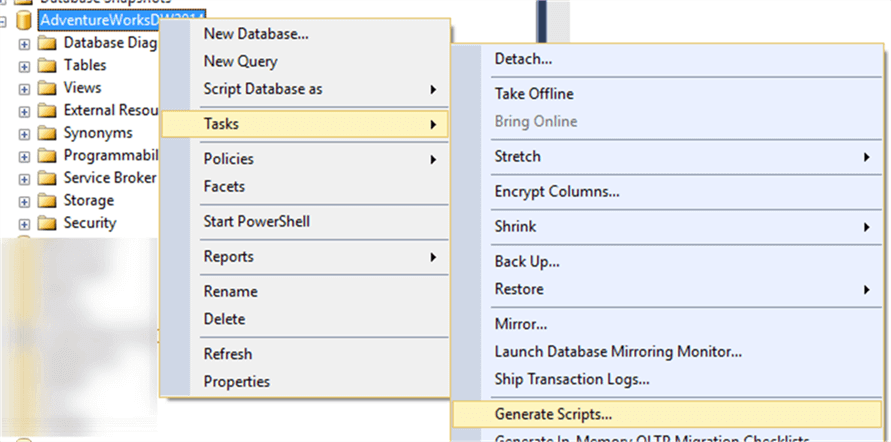
Follow the wizard and choose the Advanced scripting option, and in a new window, find the “Type of Data to Script” option and change the value to “schema and data” as shown below.
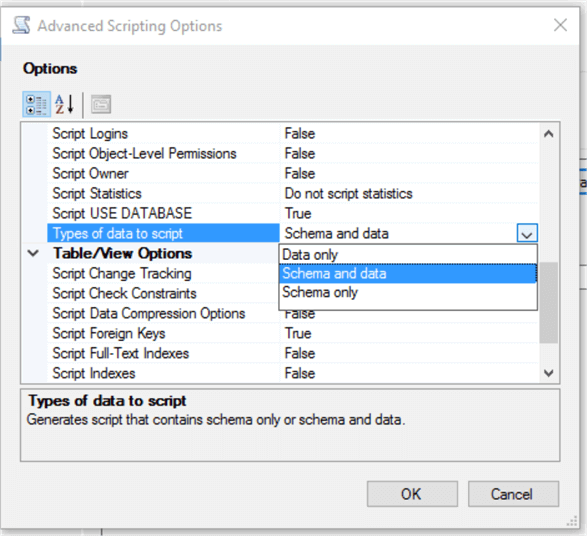
This will ensure the generated T-SQL script contains both the schema and data.
There are some other ways such as querying the table and generating dynamic INSERT T-SQL statements, or using BCP utility to export data, please see the Next Steps section for more options.
In this tip, we will explore three other ways, each with its own pros and cons. Let's get started.
Test Data Preparation
We will first create a test environment within a database [TestDB] and then add a few tables populated with a few records. Here is the code:
use Master; go -- create a [TestDB] database create database TestDB go alter database TestDB set recovery simple; go -- create a few tables use TestDB if object_id('dbo.tblFK', 'U') is not null drop table dbo.tblFK; create table dbo.tblFK (id int primary key, a varchar(100)); if object_id('dbo.tblPowerShell', 'U') is not null drop table dbo.tblPowerShell; create table dbo.tblPowerShell (id int identity primary key , a varchar(100), b decimal(10,2), d datetime, x xml , f int references dbo.tblFK (id)); if object_id('dbo.tblDBCC', 'U') is not null drop table dbo.tblDBCC; create table dbo.tblDBCC (id int, a varchar(100), b decimal(10,2), d datetime, x xml, g uniqueidentifier); go if object_id('dbo.tblR', 'U') is not null drop table dbo.tblR; create table dbo.tblR (id int, a varchar(100), b decimal(10,2), d datetime, x xml); go -- populate tables insert into dbo.tblFK (id, a) values (1, 'hello'), (2, 'world') insert into dbo.tblPowerShell (a, b, d, x,f) values ('good', 11.11, GETDATE(), '<name>jeff</name>',1) , ('morning', 22.22, GETDATE(), '<name>yao</name>',1) insert into dbo.tblDBCC (id, a, b, d, x, g) values (1, 'abc', 1.01, getdate(), '<product>tomato</product>', newid()) , (2, 'def', 2.02, getdate(), '<product>potato</product>', newid())
PowerShell + SMO Way
We can rely on SMO and PowerShell to script out a table and its data, it is actually pretty simple and straightforward.
The key point here is that there is a SMO Scripter class, and it has a method Scripter.EnumScriptWithList as demonstrated below:
#requires -version 3.0 # version=13.0.0.0, means sql server 2016 version of the assembly add-type -AssemblyName "microsoft.sqlserver.smo, version=13.0.0.0, culture=neutral, PublicKeyToken=89845dcd8080cc91"; #populate the following four variables [string]$sql_instance = 'localhost\sql2016'; # default sql instance, change to your own instance name [string]$target_db = "TestDB"; #database name where the to-be-scripted tables reside [string[]]$tbl_list = 'dbo.tblPowerShell', 'dbo.tblDBCC'; # list of tables to be scripted out, must be in two-part naming convention [string] $script_path = "c:\test\script.sql"; # file path for the script $svr = new-object -TypeName "microsoft.sqlserver.management.smo.server" -ArgumentList $sql_instance; $scripter = new-object microsoft.sqlserver.management.smo.Scripter $svr; $scripter.Options.ScriptData = $true; $scripter.Options.Indexes = $true; # script out index as well $db = $svr.databases[$target_db] if (test-path -Path $script_path) { del $script_path; } $tbls = $db.Tables | ? {($_.schema +'.' +$_.name) -in $tbl_list} $scripter.EnumScriptWithList($tbls) | out-file -FilePath $script_path -append;
In this script, we need to populate the first four variables, which are self-evident in meaning. In this case, the generated file is at c:\test\script.sql, and if I open it, it looks like the following:
SET ANSI_NULLS ON SET QUOTED_IDENTIFIER ON CREATE TABLE [dbo].[tblDBCC]( [id] [int] NULL, [a] [varchar](100) COLLATE Latin1_General_CI_AS NULL, [b] [decimal](10, 2) NULL, [d] [datetime] NULL, [x] [xml] NULL, [g] [uniqueidentifier] NULL ) ON [PRIMARY] TEXTIMAGE_ON [PRIMARY] SET ANSI_NULLS ON SET QUOTED_IDENTIFIER ON CREATE TABLE [dbo].[tblPowerShell]( [id] [int] IDENTITY(1,1) NOT NULL, [a] [varchar](100) COLLATE Latin1_General_CI_AS NULL, [b] [decimal](10, 2) NULL, [d] [datetime] NULL, [x] [xml] NULL, [f] [int] NULL, PRIMARY KEY CLUSTERED ( [id] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] ) ON [PRIMARY] TEXTIMAGE_ON [PRIMARY] INSERT [dbo].[tblDBCC] ([id], [a], [b], [d], [x], [g]) VALUES (1, N'abc', CAST(1.01 AS Decimal(10, 2)), CAST(N'2017-04-04 14:44:18.217' AS DateTime), N'<product>tomato</product>', N'1d6e824d-62f8-4895-b99c-780519a62bb8') INSERT [dbo].[tblDBCC] ([id], [a], [b], [d], [x], [g]) VALUES (2, N'def', CAST(2.02 AS Decimal(10, 2)), CAST(N'2017-04-04 14:44:18.217' AS DateTime), N'<product>potato</product>', N'30658329-2800-4488-b3d3-d48503717369') SET IDENTITY_INSERT [dbo].[tblPowerShell] ON INSERT [dbo].[tblPowerShell] ([id], [a], [b], [d], [x], [f]) VALUES (1, N'good', CAST(11.11 AS Decimal(10, 2)), CAST(N'2017-04-04 14:44:55.890' AS DateTime), N'<name>jeff</name>', 1) INSERT [dbo].[tblPowerShell] ([id], [a], [b], [d], [x], [f]) VALUES (2, N'morning', CAST(22.22 AS Decimal(10, 2)), CAST(N'2017-04-04 14:44:55.890' AS DateTime), N'<name>yao</name>', 1) SET IDENTITY_INSERT [dbo].[tblPowerShell] OFF CREATE NONCLUSTERED INDEX [idx_tblPowerShell] ON [dbo].[tblPowerShell] ( [f] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
DBCC CloneDatabase + PowerShell Way
Since SQL Server 2014 SP2, SQL Server has a new DBCC CloneDatabase command. It can copy almost all SQL Server objects, including tables, but without table data. The cloned database will be created as a read-only database.
This method has four major logical steps:
- Clone database via DBCC CloneDatabase, and then convert it to read-write status.
- Drop (or disable) all foreign keys so you can only populate a child table without its parent table.
- Use SMO Scripter object to script out data of the tables you need. Note - we do not script out schema in this case, just data, and run against the clone database.
- Drop all database objects (view, UDF, stored procedure, triggers, etc.) you do not want to keep (optional).
- Backup the cloned database and then (optionally) drop the cloned database.
Here is the code, we will only backup two tables here as defined in $tbl_list variable
#requires -Version 4.0 add-type -AssemblyName "microsoft.sqlserver.smo, version=13.0.0.0, culture=neutral, PublicKeyToken=89845dcd8080cc91"; #populate the following four variables [string]$sql_instance = 'localhost\sql2016'; # default sql instance, change to your own instance name [string]$target_db = "TestDB"; #database name where the to-be-scripted tables reside [string[]]$tbl_list = 'dbo.tblPowerShell', 'dbo.tblDBCC'; # list of tables to be scripted out, must be in two-part naming convention [string]$bkup_file = 'c:\test\TempCloneDB.bak'; $svr = new-object -TypeName "microsoft.sqlserver.management.smo.server" -ArgumentList $sql_instance; $scripter = new-object microsoft.sqlserver.management.smo.Scripter $svr; $scripter.Options.ScriptData = $true; $scripter.Options.ScriptSchema = $false; # script out index as well $db = $svr.databases[$target_db] $tbls = $db.Tables | ? {($_.schema +'.' +$_.name) -in $tbl_list} #clone db $svr.databases['master'].ExecuteNonQuery("dbcc clonedatabase($target_db, 'TempCloneDB');"); $svr.databases['master'].ExecuteNonQuery("alter database TempCloneDB set read_write, recovery simple;"); # need to drop or diable the FK to play safe $fs = @(); $svr.Databases['TempCloneDB'].tables.ForEach( { $_.foreignKeys.foreach( {$fs += $_;}) } ); $fs.foreach({$_.drop();}); #if you want to drop other objects, like views, triggers, UDFs, other tables, you can do here # the example here is to drop OTHER tables $objs = @(); $svr.Databases['TempCloneDB'].tables.ForEach({ if (($_.schema+'.'+$_.name) -notin $tbl_list) {$objs += $_;} }); $objs.foreach( {$_.drop()}); # execute the insert script $svr.Databases['TempCloneDB'].ExecuteNonQuery($($scripter.EnumScriptWithList($tbls))) #backup the database $svr.Databases['master'].ExecuteNonQuery("backup database TempCloneDB to disk='$bkup_file' with init, compression;"); #drop the cloned database $svr.databases.Refresh(); $svr.databases['TempCloneDB'].Drop();
In the code, I hard code the name (i.e. TempCloneDB) of the cloned database, but you can change it to what you like or change it to dynamic string, such as source database name + ‘_Cloned’, in my script case, it will be TestDB_Cloned.
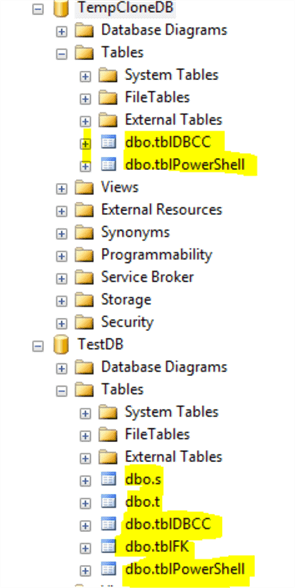
If I do not drop the TempCloneDB, we can see there are exactly two tables (as defined in $tbl_list), while in the source db TestDB, wwe have all the tables.
R + T-SQL way
This is runnable only on SQL Server 2016 as we need to use R embedded inside T-SQL. However, the source table can be on any other SQL Server versions as long as the source SQL instances is accessible to the host SQL Server 2016 instance where the backup script can run.
RR can basically handle a few data types, logical (i.e. bit in SQL Server), numeric, character (or string), date and integer. As such, this limits the usage of this method when we try to back up a table, i.e. the table cannot have other data types, such as uniqueidentifier, otherwise, we will see an error “Unhandled SQL data type!!!”.
Here is the code, for simplicity purpose, both the source table and the backup script are on the same SQL Server 2016 instance. Please change the highlighted values to the proper values of your environment.
-- for backup use master -- change UID and pwd to your choice --- currently, we have to rely on sql login instead of trusted connection to -- connect to the source table exec sp_execute_external_script @language=N'R' , @script = N'library(RevoScaleR) sqlConnStr <- "Driver=SQL Server;Server=localhost\\sql2016;Database=TestDB; UID=xyz; pwd=xyz" sqlTable <- RxSqlServerData(connectionString = sqlConnStr, table = "dbo.tblR", rowsPerRead = 50 ) rxImport(inData = sqlTable, outFile = "c:/test/mytable.xdf", overwrite = T, xdfCompressionLevel = 3)' with RESULT SETS NONE
We can restore the table to another table in another SQL Server instance. For example, the following code restores from the c:\test\mytable.xdf to a new table [localhost\sql2014].[TestDB].[dbo].[tblR2]
exec sp_execute_external_script @language=N'R' , @script = N'library(RevoScaleR) sqlConnStr <- "Driver=SQL Server;Server=localhost\\sql2014;Database=TestDB; UID=xyz; pwd=xyz" newTable <- RxSqlServerData(connectionString = sqlConnStr, table = "dbo.tblR2") rxDataStep(inData="c:/test/myTable.xdf", outFile = newTable, append = "rows", overwrite = T )' with RESULT SETS NONE
After the restore, we can see the following on the [localhost\sql2014] instance, and it is exactly the same as the source table [locahost\sql2016].[TestDB].[dbo].[tblR]
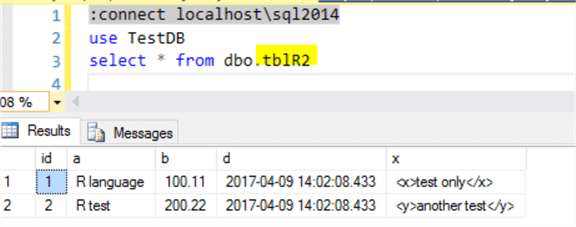
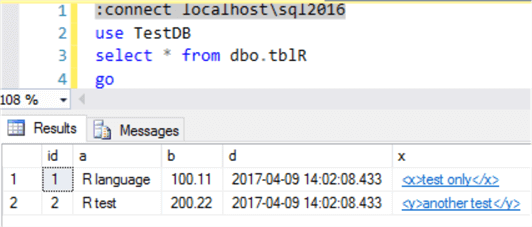
However, there is a catch here, the new table [dbo.tblR2] has different data types for columns from the original table [dbo.tblR] as shown below (even though the values are the same in string format), for example column [d] datetime is changed to [d] nvarchar(510), same is column [x], whose data type is changed from xml to nvarchar(510).
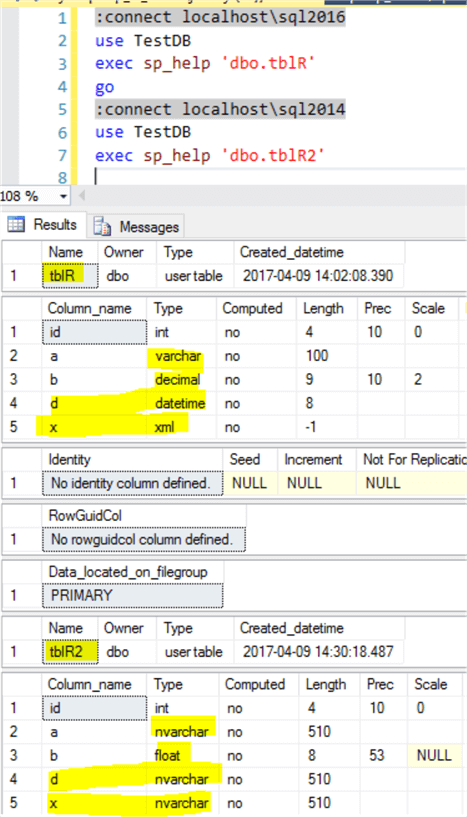
So in a strict sense, this backup via R is not necessarily the real backup from a schema integrity perspective, however, if the table has columns with only numeric and nvarchar data types, this backup can be considered as a valid backup.
Summary
In this tip, we discussed three options to perform table level backups, i.e. with the backups, we can restore the table schema and data.
Each method has its own pros and cons, and in the following table, we list the major pros / cons of each option:
| Method | Pros | Cons |
|---|---|---|
|
SMO + PowerShell |
Applicable to all scenarios |
When a table has tens of thousands of rows, the generated script can be huge |
|
DBCC CloneDatabase + PowerShell |
Generate a database backup file, it is convenient if we need to backup a few big tables as the backup file can be compressed. |
If we want only the tables we need, it would be a pain to clean up all other objects. Also the cloned database may contain multiple files, which we may not like. |
|
R + T-SQL |
Everything in T-SQL, and the backup file can be compressed so it is good for a backup of big tables. |
The backup script should be run from a SQL Server 2016 instance and some data types cannot be used in the backup, such as the uniqueidentifier data type. |
So each method may be preferred under some specific scenario, but to me SMO + PowerShell is the mostly adaptive way and is a truly backup of the table schema and data.
Next Steps
In the scripts for this tip, I just elaborate on the key points without focusing on the error handling, but if you want, you can enhance the error handling and also parameterize the function by creating a PowerShell advanced function to do the same work.
You may also read the following articles:
- Table level recovery for selected SQL Server tables
- How can I take backup of particular tables in SQL Server 2008 using T-SQL Scrip
- Backup a table in SQL Server – How to






About the author
 Jeffrey Yao is a senior SQL Server consultant, striving to automate DBA work as much as possible to have more time for family, life and more automation.
Jeffrey Yao is a senior SQL Server consultant, striving to automate DBA work as much as possible to have more time for family, life and more automation.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2017-04-21
