By: Siddharth Mehta | Updated: 2017-05-10 | Comments (3) | Related: > Analysis Services Performance
Problem
Partitioning data is a standard SQL Server administration practice. Partitions enable independent administration of different slices of data. When a SQL Server Analysis Services (SSAS) tabular data model is developed and processed, data is read from the source system and loaded into the tabular data model configured in In-Memory processing mode. Every time the model is processed, the entire data set may not require re-processing. Only certain slices of data containing changes may require re-processing which can be achieved by partitioning data into logical slices. In this tip we would look at how to partition tables in Tabular SSAS.
Solution
SQL Server Data Tools (SSDT) as well as SQL Server Management Studio (SSMS) can be used to develop as well as administer partitions in Tabular SSAS.
Let’s try to understand the concept of partitioning data in Tabular SSAS by means of an example. Consider a scenario where data is sourced from a data warehouse and loaded into the tabular data model. To demonstrate this scenario, we have used the Adventure Works Data Warehouse available from Microsoft and created a tabular data model. You can read more about importing data into tabular SSAS from here.
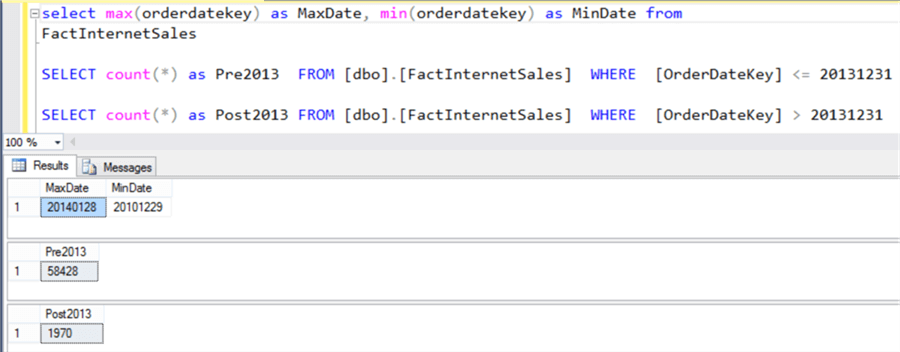
Consider the table Internet Sales which contains approximately 60,000 rows. In a data warehouse, almost every table would have a business key and most would have a surrogate key. In the case of this table, OrderDateKey is the field which holds the date of the sale. Let’s say our intention is to create a partition of the data in the latest year, and another partition for the data that is older. Mostly older data does not change and we do not wish to process the older data every time.
If you query the Internet Sales table as shown below, you would find that the data is available for the year 2010 to 2014. So if we create a partition containing all the records post 2013, it would have 1970 rows and the other partition for the rest of data would have 58428 rows. Creating this partition would help us independently process the new partition which would take less time and resources as it has to process only 1970 rows compared to 60,000 rows it would have to process without partitioning.
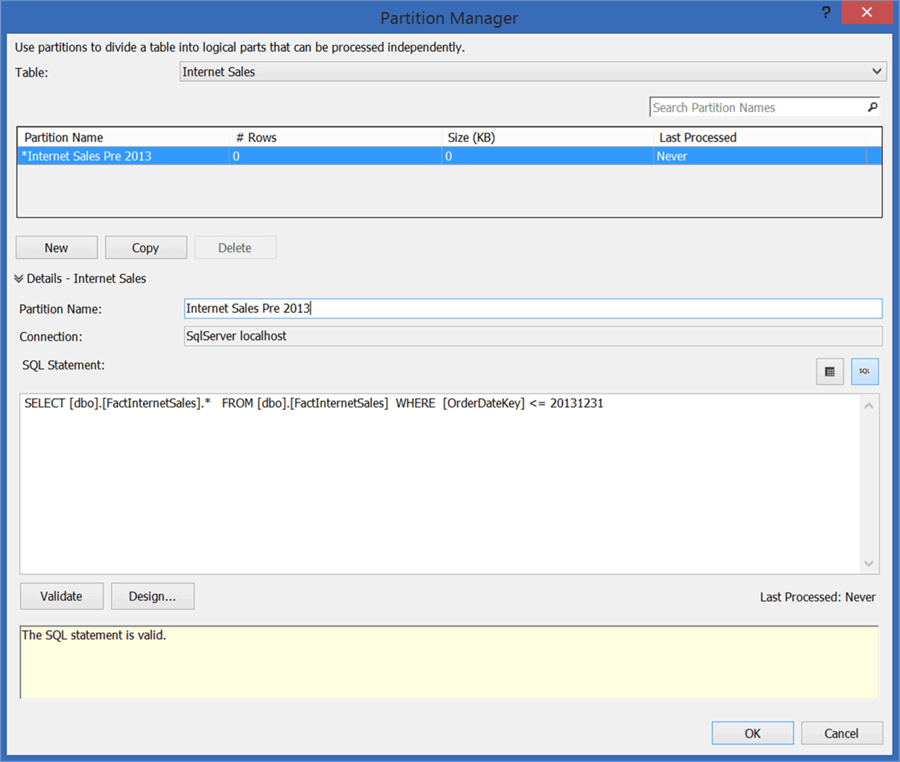
Assuming that you have already imported tables from the Adventure Works Data Warehouse and created a tabular model, select the Partitions menu item from the Table menu. You should be able to find a pop-screen as shown below. Click on the “New” button to create a new partition. Provide a relevant partition name and the logic for the partition slice.
Here we have created a partition named “Internet Sales Pre 2013” where we are selecting all the records which have OrderDateKey value less than or equal to 31-Dec-2013. In the same manner create another partition to contain data post the year 2013. You can also validate the SQL statement by clicking on the Validate button.
After creating the partition, deploy the data model on your Tabular SSAS Server instance. Open SSMS and navigate to the Internet Sales table. Right-click the same and select the Partitions menu item. You should be able to find the partitions that we created and deployed from SSDT. If you observe the “Partition Name” and “# Rows” field, you should be able to relate it to the query results from SSMS when we investigated the data from the data warehouse.
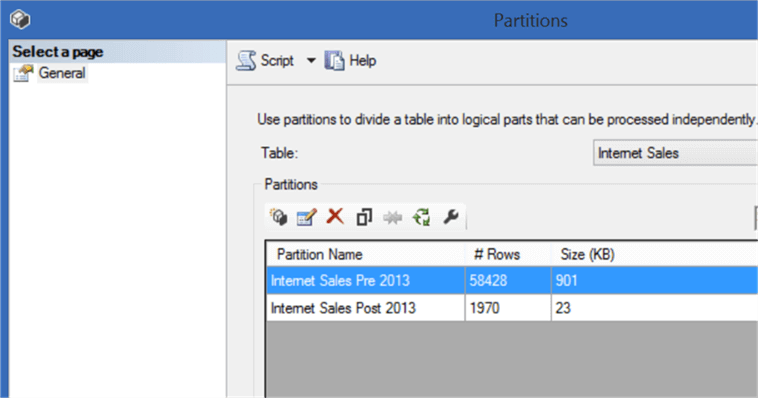
You can process, edit, merge and delete each partitions independently from SSMS. Also you can create new partitions from here in the same manner as we did in SSDT. In this way you can manage processing of data in an efficient manner by designing, developing and deploying partitions in Tabular SSAS.
Next Steps
- Consider investigating the data properly before developing partitions.
- Try out the different options from SSMS to administer partitions in Tabular SSAS.






About the author
 Siddharth Mehta is an Associate Manager with Accenture in the Avanade Division focusing on Business Intelligence.
Siddharth Mehta is an Associate Manager with Accenture in the Avanade Division focusing on Business Intelligence.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2017-05-10
