By: Rajendra Gupta | Updated: 2017-06-13 | Comments (1) | Related: > SQL Server 2017
Problem
SQL Server vNext represents a major step towards making SQL Server a platform that gives you choices for development languages, data types, on-premises and in the cloud, and across operating systems by bringing the power of SQL Server to Linux, Linux-based Docker containers, and Windows. In this tip, we will explore the SQL Server 2017 Graph Database.
Solution
Introduction to SQL Server 2017
Microsoft announced the first Community Technology Preview (CTP 1.0) of SQL Server vNext on 16th November 2016, it runs on Windows, Linux (Red Hat, SUSE and Ubuntu) and also runs on Docker and MacOS too. SQL Server vNext also includes the features added in SQL Server 2016 SP1. Currently SQL Server vNext is in preview stage, it can be downloaded as a free evaluation version (180 days validity) from the Microsoft website.
In April 2017, Microsoft released Community Technology Preview (CTP) 2.0 of SQL Server vNext. Microsoft Officially announced that this Community Technology Preview (CTP) 2.0 of SQL Server vNext will be called SQL Server 2017.
We now have a production-quality preview of SQL Server 2017 and it is available on both Windows and Linux. So with 2016 still under implementation and being explored we have SQL Server 2017 in line now.
SQL Server 2017 preview can be downloaded from this link.
Introduction to SQL Server 2017 - Graph Database
A graph in SQL Server 2017 is a collection of node and edge tables. A node represents an entity—for example, a person or an organization and an edge represents a relationship between the two nodes it connects. Node or edge tables can be created under any schema in a database, but they all belong to one logical graph.
Graph databases are useful when the application has complex many-to-many relationships and we need to analyze the complex relationships.
Some of the important features of a graph databases are:
- Edges or relationships are first class entities in a Graph Database and can have attributes or properties associated with them.
- A single edge can flexibly connect multiple nodes in a Graph Database.
- We can express pattern matching and multi-hop navigation queries easily.
- We can express transitive closure and polymorphic queries easily.
Architecture of SQL Server 2017 Graph Database looks like the following:

Let's understand the Graph database properties using this example:

Suppose we have the following social graph. Raj knows two people Akshita and Kashish. Akshita further knows Rahul and Aayush while Kashish knows Kapil. In the same way, the social tree grows further.
Each of the elements on the diagram above has a name. The circles are referred to as Nodes. The lines connecting them are relationships or Edges. So basically Nodes are the entity which can be anything like person, organization, movie, things, etc. These entities are connected to each other with a relationship that is called Edges. So the basic flows goes something like Node > Relationship > Node.
As the graph grows further, if we want to get the details like the people who know Kapil, through a relation database query it is possible, but the query will become complex. In SQL Server 2017, with the Graph Database it becomes easier to represent and get the query results.
Node Table
A node table represents an entity in a graph schema. Whenever we create a node table, along with the user defined columns, an implicit $node_id column is created, which uniquely identifies a given node in the database. The values in the $node_id column are automatically generated and are a combination of object_id of that node table and an internally generated bigint value. However, when the $node_id column is selected, a computed value in the form of a JSON string is displayed. Also, $node_id is a pseudo column, that maps to an internal name with hex string in it. When we select $node_id from the table, the column name will appear as $node_id_\hex_string.
It is recommended that users create a unique constraint or index on the $node_id column at the time of creation of node table, but if one is not created, a default unique, non-clustered index is automatically created.
Syntax for creating the Node table:
CREATE TABLE
[ database_name . [ schema_name ] . | schema_name . ] table_name
( { } [ ,...n ] )
AS [NODE]
[ ; ]
For example, if we want to create the Person table with the columns as ID, Name and City the following code would be used:
Create database GraphDB
Go
Use GraphDB
go
CREATE TABLE Person (
ID INTEGER PRIMARY KEY,
name VARCHAR(100),
City VARCHAR(100)
) AS NODE;
Inserting into a Node table is the same as that of a regular table.
Now insert the sample data into the table
Insert into Person values (1,'Raj','Guragon') Insert into Person values (2,'Kashish','Jaipur')
Now if we view the data in the table, we can see the $node_id column is added into the node table.

As I mentioned earlier, if we don't specify an index on the node table, SQL Server will create one as shown below:

Edge Table
As mentioned earlier, an edge table represents a relationship in a graph. Edges are always directed and connect two nodes. An edge table enables users to model many-to-many relationships in the graph. An edge table may or may not have any user defined attributes in it.
Syntax for creating Edge tables
CREATE TABLE
[ database_name . [ schema_name ] . | schema_name . ] table_name
( { } [ ,...n ] )
AS [Edge]
[ ; ]
Edge table without user defined attributes
Suppose we want to create Edge table named friendof without any user defined attributes, so the syntax would be:
CREATE TABLE friendOf AS EDGE;
Edge table with user defined attributes
Suppose we want to create Edge table named likes with any user defined attributes, so the syntax would be:
CREATE TABLE likes (rating INTEGER) AS EDGE;
We now have to insert the data into the Edge table with the data from the Nodes. Suppose we want to insert data into the friendof edge table so we will provide information regarding two nodes to be connected.
While inserting into an edge table, we have to provide values for $from_id and $to_id columns.
In the below example, the Edge is created between person having ID 1 with Person ID 2 and relationship i.e.Edge is called friendof.
INSERT INTO friendof VALUES ((SELECT $NODE_ID FROM person WHERE ID = 1), (SELECT $NODE_ID FROM person WHERE ID = 2))
Now if select the content of friendof Edge table, it shows 3 columns

$edge_id: The first column in the Edge table represents $edge_id that uniquely identifies a given edge in the database. The value of the edge_id column is generated with the combination of object_id of the edge table and an internally generated bigint value. However, when we select the $edge_id column, it is displayed as the JSON string that is computed from the column value. As we can see the column name for edge_id is $edge_id_F7687B1E413C4B7795A64249CDB214F1. $edge_id is a pseudo-column, that maps to an internal name with a hex string in it. So the column name appears as $edge_id_\hex_string.
So if we use the pseudo-column name in the query instead of using the name with hex strings in it, we can directly query using the $edge_id as shown below:

$from_id: This column stores the $node_id of the node, from where the edge originates. Similar to $edge_id this is also a pseduo-column and can be used as $from_id however the column name includes hex strings in it.
$to_id: This Stores the $node_id of the node, at which the edge terminates. Behavior of this column in also as per $edge_id and $from_id column.
As stated earlier for the $node_id column, it is recommended to create a unique index or constraint on the $edge_id column at the time of creation of the edge table, but if one is not created, a default unique, non-clustered index is automatically created on this column.

We should also create the indexes on the $from_id and $to_id columns if we have high usage OLTP environment.
Below is the architecture of how the node and edge tables store data as well as how the data links to each other.

Important Tables and Metadata for Graph Databases
SYS.TABLES: New columns have been added to the sys.tables to identify whether a table is a node or edge.
| Column Name | Data Type | Description |
|---|---|---|
| is_node | bit | 1 = this is a node table |
| is_edge | bit | 1 = this is an edge table |

SYS.COLUMNS: New columns have been added to the sys.tables to indicate the type of the column in node and edge tables.
| Column Name | Data Type | Description |
|---|---|---|
| graph_type | int | Internal column with a set of values. The values are between 1-8 for graph columns and NULL for others. |
| graph_type_desc | nvarchar(60) | internal column with a set of values |

Below are the valid values for graph_type:
| Value | Description |
|---|---|
| 1 | GRAPH_ID |
| 2 | GRAPH_ID_COMPUTED |
| 3 | GRAPH_FROM_ID |
| 4 | GRAPH_FROM_OBJ_ID |
| 5 | GRAPH_FROM_ID_COMPUTED |
| 6 | GRAPH_TO_ID |
| 7 | GRAPH_TO_OBJ_ID |
| 8 | GRAPH_TO_ID_COMPUTED |
Functions for Graph and Edge Tables
There are a few functions provided to help users extract information from the generated columns. Below are the functions:
OBJECT_ID_FROM_NODE_ID: This function extracts the object_id from a node_id. We need to pass node_id to this function and it will return the object_id. We can also get the object name from the object_id.
select OBJECT_ID_FROM_NODE_ID('{"type":"node","schema":"dbo","table":"Person","id":0}')
select object_name(1221579390)


GRAPH_ID_FROM_NODE_ID: This function extracts the graph_id from a node_id. We need to pass node_id to this function and it will return the object_id.
select GRAPH_ID_FROM_NODE_ID('{"type":"node","schema":"dbo","table":"Person","id":1}')

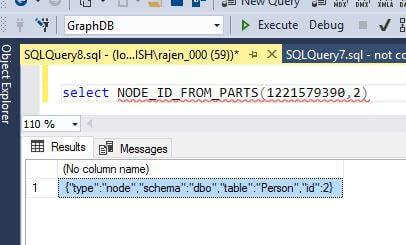
NODE_ID_FROM_PARTS: This function constructs a node_id from an object_id and a graph_id.
select NODE_ID_FROM_PARTS(1221579390,2)
OBJECT_ID_FROM_EDGE_ID: This function extracts an object_id from an edge_id.
select OBJECT_ID_FROM_EDGE_ID('{"type":"edge","schema":"dbo","table":"friendOf","id":1}')
select OBJECT_NAME(1525580473)

GRAPH_ID_FROM_EDGE_ID: This function extracts a graph_id from edge_id.
select GRAPH_ID_FROM_EDGE_ID('{"type":"edge","schema":"dbo","table":"friendOf","id":1}')

EDGE_ID_FROM_PARTS: This function constructs ab edge_id from object_id and identity.
select EDGE_ID_FROM_PARTS(1525580473,1)

Next Steps
- In this tip we have provided an overview of Graph databases and the associated functions and tables.
- In the next tip we will see how to get the information from the Graph tables and how it is different from relational T-SQL.
- We will explore more about SQL Server 2017 in future tips.
- Explore SQL Server 2017 preview.






About the author
 Rajendra Gupta is a Consultant DBA with 14+ years of extensive experience in database administration including large critical OLAP, OLTP, Reporting and SharePoint databases.
Rajendra Gupta is a Consultant DBA with 14+ years of extensive experience in database administration including large critical OLAP, OLTP, Reporting and SharePoint databases.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2017-06-13
