By: Siddharth Mehta | Updated: 2017-08-07 | Comments (4) | Related: > SQL Server 2017
Problem
SQL Server 2017 Machine Learning Services is set to bring machine learning capabilities to SQL Server with the integration of R and Python in SQL Server. A lot of statistics is involved in exploring the data before concluding the right machine learning model for the intended analysis. Once the model is finalized it needs to be implemented and used for prediction. SQL Server also introduces a lot of machine learning functions to create machine learning models which can be used for predictive analysis. In this tip we will learn how to create a machine learning model in SQL Server 2017.
Solution
T-SQL and R can be used to develop machine learning models for predictive analysis. In this tip we will use R and T-SQL in SQL Server 2017 to develop and store a machine learning model and then we will use these to predict outcomes for sample test values. We will assume that SQL Server 2017, In-Database Machine Learning Services, and R are already installed and integrated.
There are various machine learning algorithms that can be used with machine learning models. The simplest is a linear regression model, which is used to learn the relationship between different variables / attributes. Using the learned relationship, the model can predict outcomes for any given value. We will be using this for the purpose of demonstration.
The first step is to create a table where we can store the model. For this we need at least two fields – model name and model definition. Execute the below T-SQL script to create a table named ml_models that will store the model. When a machine learning model is created, the serialized model is a varbinary data type. So we have use the same data type for the machine learning model.
CREATE TABLE ml_models (
model_name varchar(30) not null default('default model') primary key,
model varbinary(max) not null);
Now that we have the structure to host the model, the next step is to create the machine learning model. Linear regression is used to learn the relationship between one or multiple variables / attributes. Relationships can be of two types – deterministic and statistical. Deterministic relationships are easier to learn and perfect, like the relationship between Celsius and Fahrenheit. The formula of converting Celsius to Fahrenheit is F = C * 9/5 + 32. Every value in Celsius will have the same relationship with Fahrenheit.
Let’s assume that we do not know this relationship and we want to use the linear regression model to interpret this relationship. The relation between Celsius and Fahrenheit is linear, as the value of both variables would increase and decrease proportionally. This can be studied very easily using a scatterplot. We will assume we have done due diligence to derive that the two variables have a linear relationship.
Execute the below T-SQL Script to create a stored procedure that creates and outputs a linear model. Read the comments in the code to understand each line of code in the R Script. In this script we are creating 10 values of Celsius from 1 to 10, and creating corresponding values for Fahrenheit. We are using this as the test data for the model. We are creating a linear regression model using the rxLinMod function, and returning the output after serializing it, so that we can store it in a SQL Server table.
CREATE PROC linear_model
AS
BEGIN
EXEC sp_execute_external_script
@language = N'R'
, @script = N'
Celsius <- 1:10 # Create a vector with value 1 to 10
Fahrenheit <- ((Celsius * 9) / 5) + 32 # Create another vector with Fahrenheit formula
DF <- data.frame(Celsius, Fahrenheit) # Create a data frame with two columns of Celsius and Fahrenheit
linearmodel <- rxLinMod(formula = Fahrenheit ~ Celsius, data = DF); # Create a linear model using rxLinMod function and data frame
trained_model <- data.frame(payload = as.raw(serialize(linearmodel, connection=NULL))); # Return serialized model as a data frame'
, @output_data_1_name = N'trained_model'
WITH RESULT SETS ((model varbinary(max)));
END
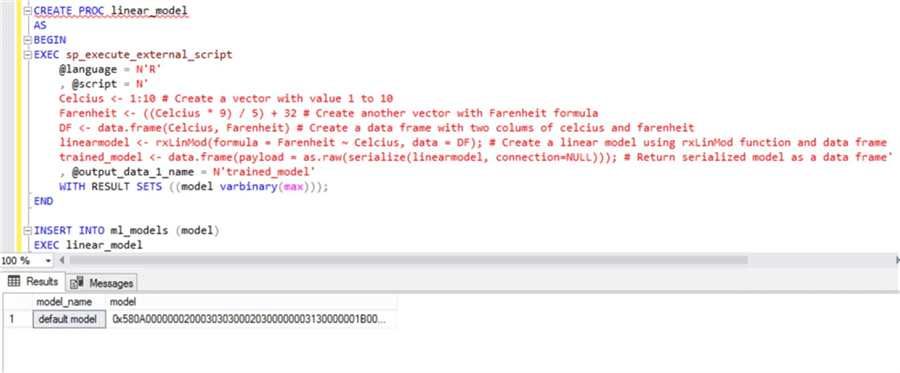
Insert this serialized model in the ml_models table that we created in the first step using the below script. After the model is successfully added to the table, it should look like below.
INSERT INTO ml_models (model) EXEC linear_model
Now that we have a trained model, we can test this model to verify whether it has interpreted the relationship and whether it can accurately or near-accurately predict the outcome of any given test value. Execute the below script to test.
DECLARE @CFmodel varbinary(max) = (SELECT model FROM [dbo].[ml_models] WHERE model_name = 'default model');
EXEC sp_execute_external_script
@language = N'R'
, @script = N'
current_model <- unserialize(as.raw(CFmodel)); # Unserialize model
Celcius <- c(11.5, 50) # Create a Celsius vector with two values - 11.5 and 50
testDF <- data.frame(Celcius) # Create a data frame using Celsius vector
predicted.temp <- rxPredict(current_model, testDF); # Execute the model for prediction using rxPredict function
OutputDataSet <- cbind(testDF$Celcius, predicted.temp); # Bind the input and prediction output and return the same
'
, @params = N'@CFmodel varbinary(max)'
, @CFmodel = @CFmodel
WITH RESULT SETS ((Celcius FLOAT, Predicted_Farenheit FLOAT))
In this script we first extract the model, passing this to the R script and unserializing. After that we are creating two test values in Celsius and using this to test the prediction output of the model using the rxPredict function. We are binding the input and output values and displaying these in the final output. If you carefully analyze the output, the model interpreted the relationship between these two variables and accurately predicted the value in Fahrenheit for a given value in Celsius. This relationship was interpreted by the model using the data we fed it for training while creating the model.

One point to note is that this example is just meant to demonstrate how we can develop, store, and read machine learning models and how we can use these for prediction. The data science and mathematics involved in assessing the properties of data, the process of pre-analyzing the data set, the complexity in relationship between variables, the analysis of model properties to improvise the model in an iterative process is exponentially more than what is presented in this tip and is beyond the scope of this tip.
One thing that is applicable across all machine learning algorithms of any complexity is the way models are created, stored, read, and written in SQL Server and the way they are used for prediction. This is exactly what we learned in this tip using T-SQL and R.
Next Steps
- Consider learning more about machine learning algorithms and try to apply them on your data of interest in SQL Server for predictive analysis.






About the author
 Siddharth Mehta is an Associate Manager with Accenture in the Avanade Division focusing on Business Intelligence.
Siddharth Mehta is an Associate Manager with Accenture in the Avanade Division focusing on Business Intelligence.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2017-08-07
