By: Ben Snaidero | Updated: 2017-12-06 | Comments (6) | Related: > Performance Tuning
Problem
Performing unnecessary processing during query execution can sometimes prove to be one of the bigger culprits when it comes to the overall performance of your SQL Server database instance. Far too many times I've seen queries that do "SELECT *" when they really only need one or two columns from the result set. Sometimes there is a column list defined in the query but within the code only a few of the columns are actually used. This tip will use a fairly extreme example to show how querying only the columns you actually require can have a positive impact on SQL Server performance.
Solution
If you would like to follow along yourself or do further testing, the schema used for the demonstration below is from the AdventureWorks2014 database which can be downloaded from the following link. AdventureWorks2014 download. The second set of test queries in the demonstration use an enlarged version of the SalesOrderDetail table which can be created by using the script found here. Once you have the schema created you can also add a fairly wide Notes column to both the Employee and SalesOrderDetailEnlarged tables and populate them both with some data. Below is the TSQL to add these two columns and populate them.
ALTER TABLE HumanResources.Employee ADD Notes VARCHAR(max);
UPDATE HumanResources.Employee SET Notes=REPLICATE('x',30000);
ALTER TABLE [Sales].[SalesOrderDetailEnlarged] ADD Notes VARCHAR(max);
UPDATE [Sales].[SalesOrderDetailEnlarged] SET Notes=REPLICATE('x',30000);
SQL Server Performance Test Case 1
Now that we have our schema created let’s look at our first example. As mentioned in the problem statement we are going to run two different versions of this query. One that returns all the columns from the table and one that leaves out this new large column we have just added. For the first test we are going to look at a relatively small table and see the effect that returning this large column data has on the query performance. Here are the queries for this test.
select * from HumanResources.Employee order by HireDate desc GO select [BusinessEntityID],[NationalIDNumber],[LoginID],[OrganizationNode],[OrganizationLevel] ,[JobTitle],[BirthDate],[MaritalStatus],[Gender],[HireDate],[SalariedFlag],[VacationHours] ,[SickLeaveHours],[CurrentFlag],[rowguid],[ModifiedDate] from HumanResources.Employee order by HireDate desc GO
When running these queries in order to gather some statistics you will need to select the "Include Client Statistics" and "Include Actual Execution Plan" buttons on the toolbar in SQL Server Management Studio. Once that is done we can take a look at the results. Below is a subset of the client statistics and as you can see the query that omitted the large column from the result set ran 20ms faster. Most of this can probably be attributed to the fact that it returned 2332268 fewer bytes.
| No Large Column | All Columns | |
|---|---|---|
| Query Profile Statistics | ||
| Rows returned by SELECT statements | 292 | 292 |
| Network Statistics | ||
| Number of server roundtrips | 4 | 4 |
| TDS packets sent from client | 4 | 4 |
| TDS packets received from server | 26 | 595 |
| Bytes sent from client | 956 | 478 |
| Bytes received from server | 92,195 | 2,424,463 |
| Time Statistics | ||
| Client processing time | 45 | 66 |
| Total execution time | 58 | 78 |
| Wait time on server replies | 11 | 12 |
If we dig a little further and look at the explain plan for the above queries we can confirm that it is definitely the row size that is different between the two result sets. Looking at the first query with all the columns we see that the "Estimated Row Size" is 4854 bytes.
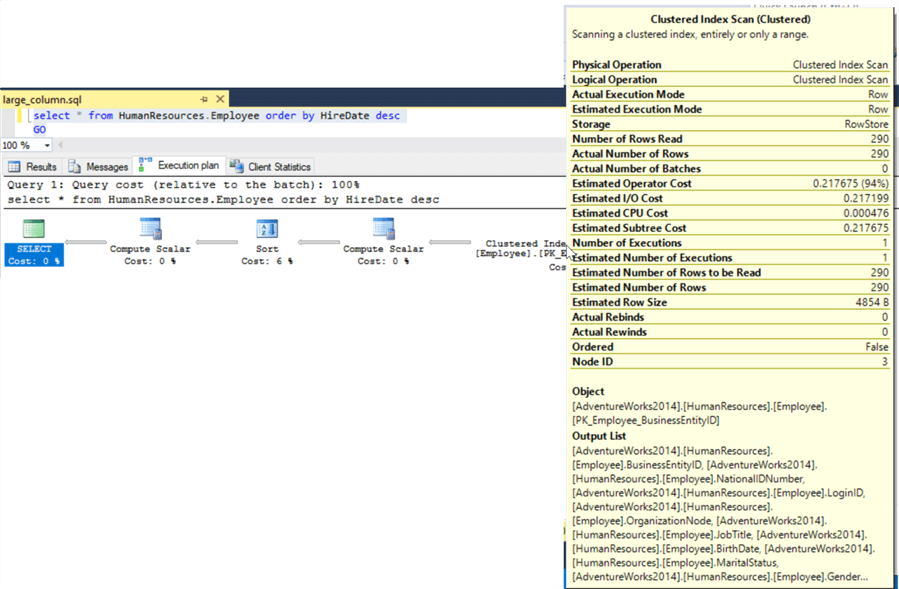
Looking at the second query without the large Notes columns we see that the "Estimated Row Size" is only 828 bytes.
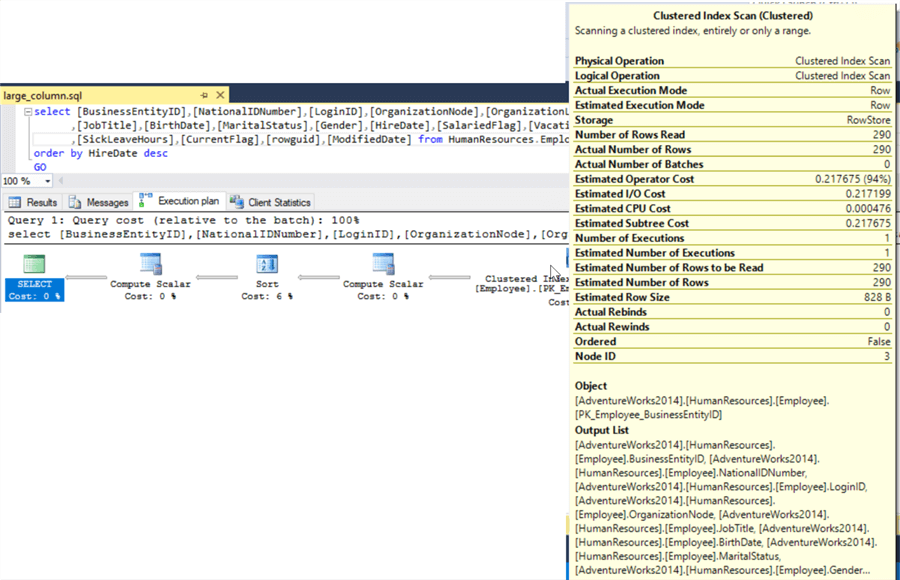
EEven for a small table like this we see a performance benefit in just returning the data that we need. Let's now take a look at a large table.
SQL Server Performance Test Case 2
For this example we will use the SalesOrderDetailEnlarged table we created with the script linked above with the following two queries. Just as with the first test case in the second query we will leave our large Notes column out of the result set.
select * from [Sales].[SalesOrderDetailEnlarged] order by [ModifiedDate] desc GO select [SalesOrderID],[SalesOrderDetailID],[CarrierTrackingNumber],[OrderQty],[ProductID] ,[SpecialOfferID],[UnitPrice],[UnitPriceDiscount],[LineTotal],[rowguid],[ModifiedDate] FROM [Sales].[SalesOrderDetailEnlarged] order by [ModifiedDate] desc GO
As we did in the first test case let’s first take a look at the client statistics for these queries. As you can see when querying the table with the extra data from the large Notes column we have a duration of almost 20 minutes compared to only about 20 seconds when this column is left out of the result set.
| No Large Column | All Columns | |
|---|---|---|
| Query Profile Statistics | ||
| Rows returned by SELECT statements | 4,852,682 | 4,852,682 |
| Network Statistics | ||
| Number of server roundtrips | 4 | 4 |
| TDS packets sent from client | 4 | 4 |
| TDS packets received from server | 95,209 | 9,619,945 |
| Bytes sent from client | 848 | 490 |
| Bytes received from server | 389,963,000 | 39,403,270,000 |
| Time Statistics | ||
| Client processing time | 17,768 | 120,0682 |
| Total execution time | 21,281 | 120,7548 |
| Wait time on server replies | 3,513 | 6,866 |
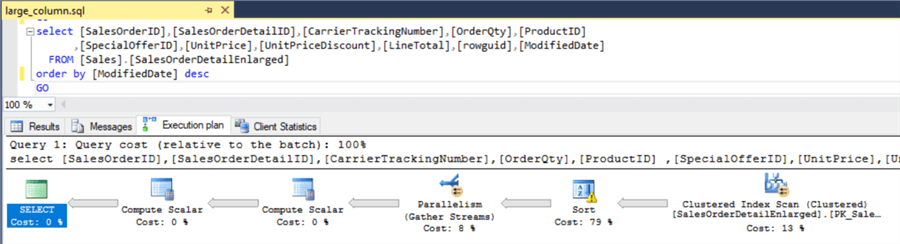
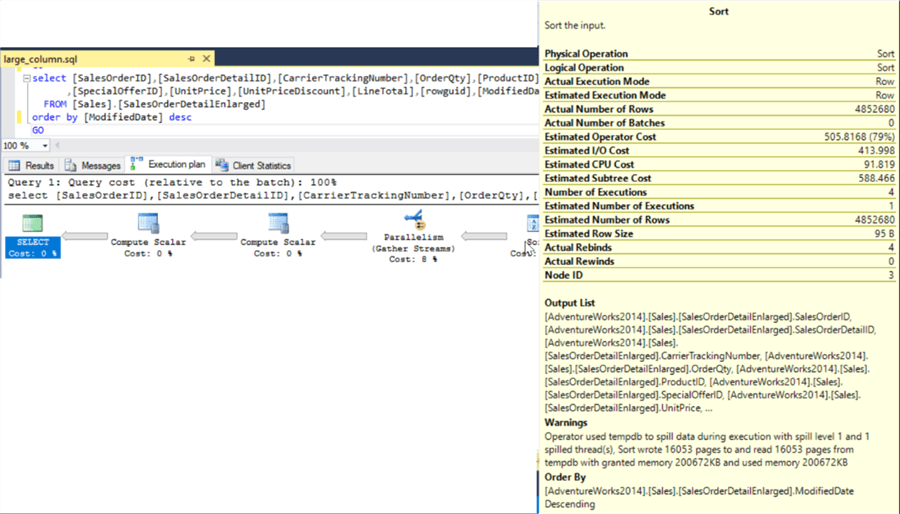
Again digging deeper and looking at the explain plan let’s see if it was just returning the extra data that caused the longer run time or if there were other factors. The explain plan for each query is below and as it turns out there was another factor that contributed to the long execution time. If you look at the sort task in the both explain plans we see that the sort actually spilled to disk due to the large amount of data. This along with the larger "Estimated Row Size", 4121 bytes for this query, would have a negative impact on the query performance and explains why we had much poorer performance compared with the second query.
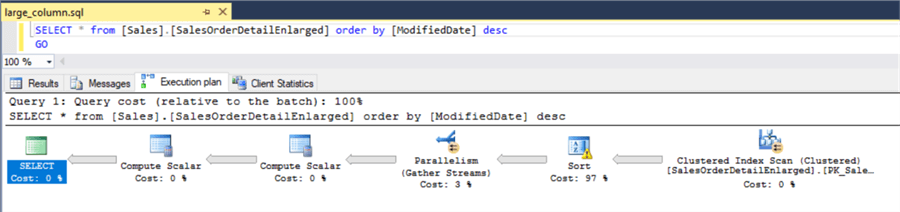
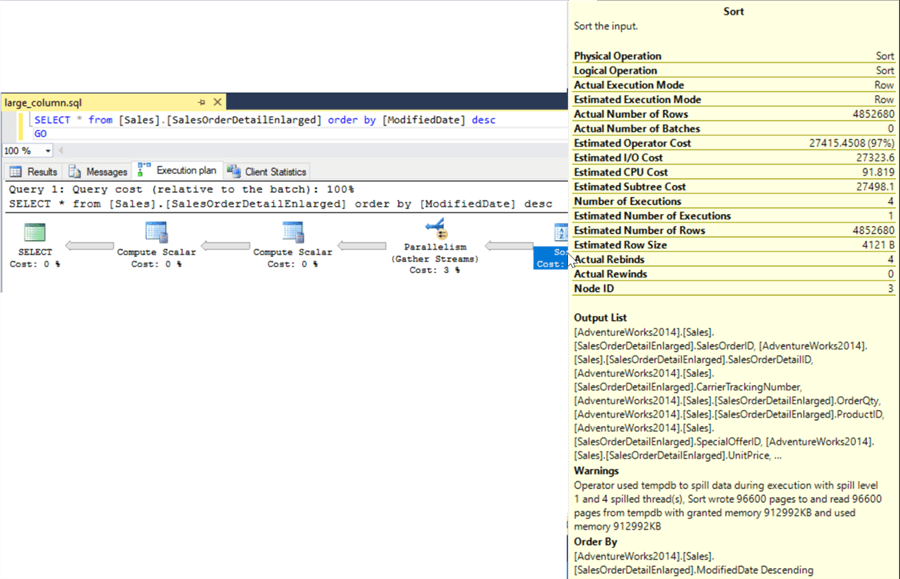
Looking at the second query although we still see the sort spilling to disk it had to write much fewer pages to the tempdb, 16053 compared with 96600 for the query with all columns. Also for this query the "Estimated Row Size" is only 95 bytes, much less data needed to be returned to the calling application.
Summary
The two simple examples above show how you must be diligent is ensuring that only the required data is queried and returned to the application. Querying unnecessary data not only leads to poor performance for the person initiating the call, but can also effect other processes with all the extra processing/CPU, network traffic and database IO that is needed to execute the query.
Next Steps
- Read other tips on performance tuning.
- Read more on monitoring queries in SQL Server.






About the author
 Ben Snaidero has been a SQL Server and Oracle DBA for over 10 years and focuses on performance tuning.
Ben Snaidero has been a SQL Server and Oracle DBA for over 10 years and focuses on performance tuning.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2017-12-06
