By: John Miner | Updated: 2017-09-15 | Comments (4) | Related: > PowerShell
Problem
Most companies are faced with the ever-growing big data problem. It is estimated that there will be 40 zettabytes of new data generated between 2012 to 2020. See the Computerworld article for details. Most of this data will be generated by sensors and machines. However, only a small portion of the data is available for users.
Every operating system contains files in two different formats, Binary files and Text files. Binary files contain a sequence of bytes only understood by special programs. One example of a binary file is family photo saved to your laptop in a jpeg format. Another example of a binary file is the executable program named “notepad++.exe". Text files contain a sequence of ASCII characters which can be easily understood by humans. A log file is considered a text file with a specific format defined by the program that generated it. I used notepad++ application to open, edit and save text files which contain the code snippets used in this article.
How can IT professionals help business lines gather and process data from various sources?
Solution
Microsoft has installed PowerShell on every up-to-date operating system. Given a little time and practice, you will be an expert at processing text files with PowerShell.
Business Problem
There are many financial companies that invest in the stock market via mutual funds. Our fictitious company named Big Jon Investments is such a company. They currently invest in the S&P 500 mutual fund, but are thinking of investing in individual funds starting in 2017. The investments department will need historical data to make informed choices when picking stocks.
Our boss has asked us to pull summarized daily trading data for the 505 stocks that make up the list of S&P 500 companies. Last year’s historical data will be the start of a new data mart. The preferred format of the data is comma delimited.
How can we accomplish this task using PowerShell?
As a designer, we will need to combine a bunch of cmdlets to create a solution to solve our business problem.
I chose to break this solution into two parts for easy learning.
- Part 1 - Working with directories and files
- Part 2 - Processing text files (this tip)
Today, we will focus on part two of this topic.
Manipulating Content
There are several cmdlets that can be used to read from, append to, clear all, and write to files. Each of these cmdlets contains the word Content. The table below gives a brief description of each cmdlet. The next four examples demonstrate a sample use of each cmdlet.
| Example | Cmdlet | Description |
|---|---|---|
| 1 | Get-Content | Read in a typical Transact SQL script. |
| 2 | Set-Content | Write out a typical Transact SQL script. |
| 3 | Add-Content | Add a comment to end of the script. |
| 4 | Clear-Content | Wipe out the contents of the file. |
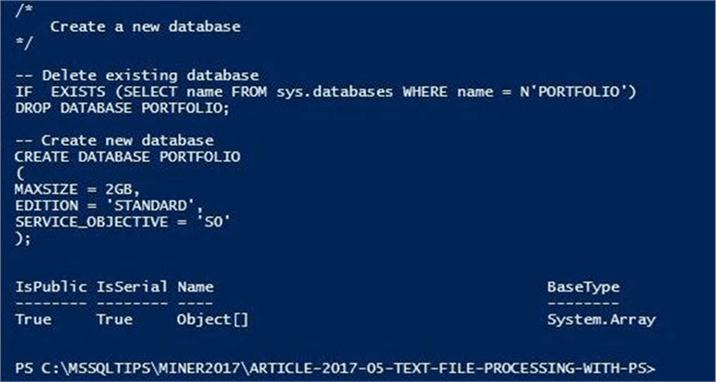
The PowerShell code below reads in the T-SQL script that can create an Azure database named PORTFOLIO. If we look at the base type of the $content variable, we can see it is an array of objects.
# # 1 - Read text file # # Path to file $path = "c:\stocks\" $srcfile = $path + "create-database-1.sql" # Read input $content = Get-Content $srcfile # Show the contents Clear-Host $content Write-Host " " # Confirm it is a string array $content.GetType()
The output below shows the content of the text file and the resulting type of the PowerShell variable.
The script below writes out the contents of the first file to a second file.
# # 2 - Write text file # # Path to file $path = "c:\stocks\" $dstfile = $path + "create-database-2.sql" # Write output $content | Set-Content -Path $dstfile
It is important to understand which operating system you are writing the file for. Windows expects both a carriage return and line feed at the end of each line. Unix only expects a line feed. Therefore, the newline character is dependent upon operating system. The script below adds one extra line to the second script.
# # 3 - Append to text file # # Carriage return & line feed $crlf = [char]13 + [char]10 # New content 2 add $addition = $crlf + "-- Comment at bottom of file" # Append content 2 bottom Add-Content -Path $dstfile -Value $addition
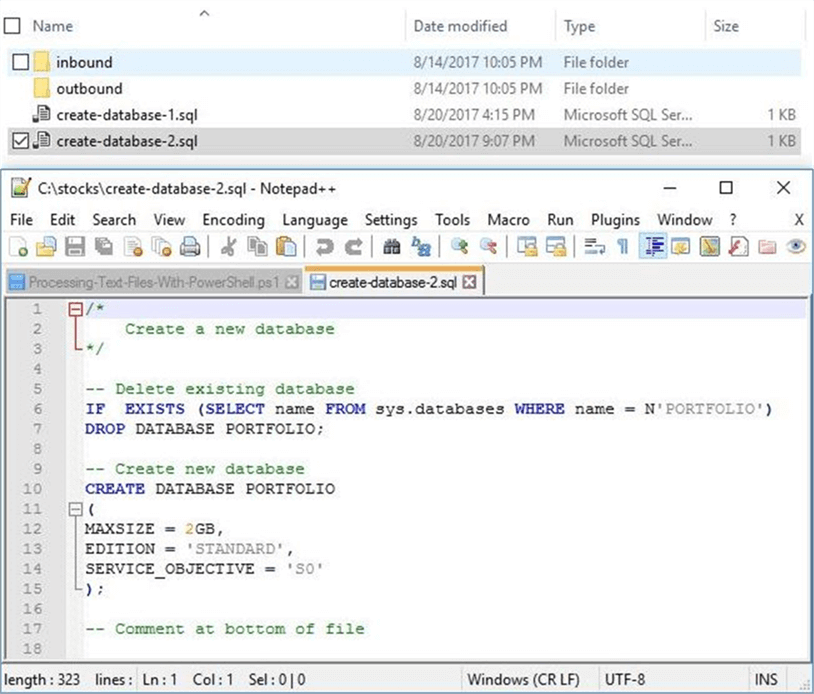
The output below was taken from Windows explorer and shows both versions of the “create-database-n.sql” files. Upon inspection of the second version of the file using the notepad++ application, we can see the new comment at the bottom of the file.
The script below removes all content from the second file.
# # 4 - Clear text file # # Zero byte resulting file Clear-Content -Path $dstfile
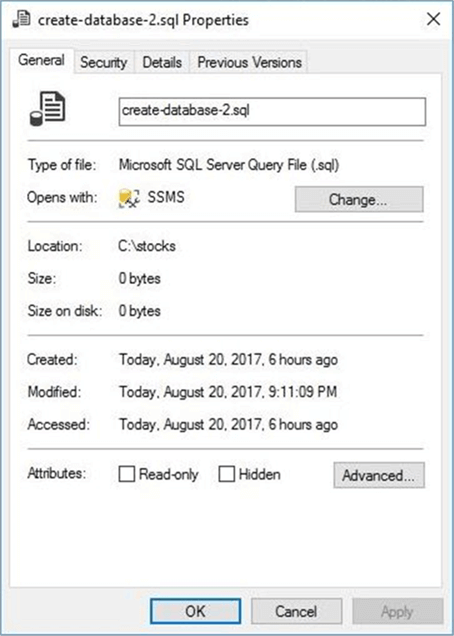
The windows explorer image below shows that the “create-database-2.sql” file is occupying zero bytes of space on the file system.
There are times when you need to cast the array of objects returned from the Get-Content cmdlet to a string data type. For instance, the Exec-NonQuery-SqlDb custom cmdlet I defined in an earlier tip might use the file as input. What you might not expect, is the string to have all newline characters removed. To preserve newlines, use the -Delimited parameter with the \n pattern that represents newline. This switch will preserve the newlines when you cast the result into a string.
The code below demonstrates one execution that loses newlines and another execution that saves newlines.
# # 5 - Use delimiter parameter # # Path to file $path = "c:\stocks\" $srcfile = $path + "create-database-1.sql" # Grab the script $content = Get-Content $srcfile # Cast to string [string]$result = $content # Lost my crlf? $result # Grab the script $content = Get-Content -Delimiter "`n" $srcfile # Cast to string [string]$result = $content # Saved my crlf? $result
The output below shows the T-SQL script with the newline characters removed.

To recap, PowerShell includes four cmdlets that help you work with content (files). Make sure you pay attention to both -Delimiter and -Encoding when reading and writing files. Please note, the Set-Content places a write and read lock on the file. Therefore, writing big files might cause issues with a process trying to read the file at the same time. I will introduce the Out-File command in the next section. Please see this stack overflow entry for details on the differences.
Advanced Functions
Adding the CmdletBinding clause to an interpreted function makes it act like a compiled function. What does that mean? Many of the standard parameters like -Verbose are automatically available for use in your function.
I always say an example is like a thousand words. Comments in a T-SQL script are great for the designer to understand the code. However, the algebraic parser in SQL Server just ignores them. Let us write a function that will remove comments from a given script.
The code below implements a custom function named Remove-TSQL-Comments. Each advanced function has three sections that may or may not be used. In the BEGIN section, we can initialize the variables we are going to use. The PROCESS section is called for each line of input passed via the pipeline. We are going to concatenate input without comments to a variable named $out. All other input will be ignored. In the END section, we return this variable as our result. Make sure you add the ValueFromPipeline parameter, otherwise the function will error out when data is piped to it.
#
# Name: Remove-TSQL-Comments
# Purpose: Remove comments from t-sql script.
#
function Remove-TSQL-Comments {
[CmdletBinding()]
Param (
[Parameter(ValueFromPipeline=$true)][String[]]$PipeValue
)
Begin
{
# Optional message
Write-Verbose "Starting - Remove-TSQL-Comments()"
# Define variables
[int]$cnt = 0;
[int]$state = 0;
[int[]]$pos = @();
[string[]]$out = @();
}
Process
{
# Grab a line from the pipe
[string]$line = $_
# Find positions of comments
$pos += $line.IndexOf('/*')
$pos += $line.IndexOf('*/')
$pos += $line.IndexOf('--')
# Start comment
if ($pos[0] -ne -1)
{
$state = 1;
Write-Verbose "start - long comment"
Write-Verbose $cnt;
Write-Verbose ""
}
# End comment
elseif ($pos[1] -ne -1)
{
$state = 0;
Write-Verbose "end - long comment"
Write-Verbose $cnt;
Write-Verbose ""
}
# Short comment
elseif ($pos[2] -ne -1)
{
Write-Verbose "short comment"
Write-Verbose $cnt
Write-Verbose ""
}
# Middle comment
elseif ($state -eq 1)
{
Write-Verbose "middle - long comment"
Write-Verbose $cnt
Write-Verbose ""
}
# Just programming
else
{
$out += $line
};
# line counter
$cnt++;
# clear the array
$pos = @();
}
End
{
# Optional message
Write-Verbose "Ending - Remove-TSQL-Comments()"
# Return the object
$out
}
}
Now that we have our advanced function defined, we need to test it out. The code below does just that.
# # 6 - Remove comments from script # # Define variables [string]$path = "c:\stocks\" [string]$srcfile = $path + "create-database-1.sql" [string]$dstfile = $path + "create-database-wo-comments.sql" [string]$result = "" # Read input file & remove comments $result = Get-Content -Delimiter "`n" $srcfile | Remove-TSQL-Comments -Verbose # Write output file $result | Out-File $dstfile
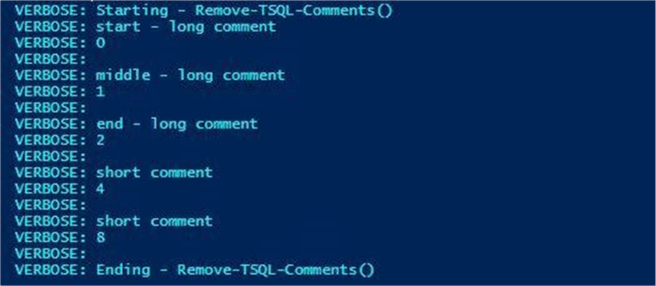
The verbose command allows us to see optional messages. Shown below is the output from executing snippet number six. We can see the line numbers that are considered comments.
If we open the resulting output in notepad++, we can see that the comments are removed from the file.
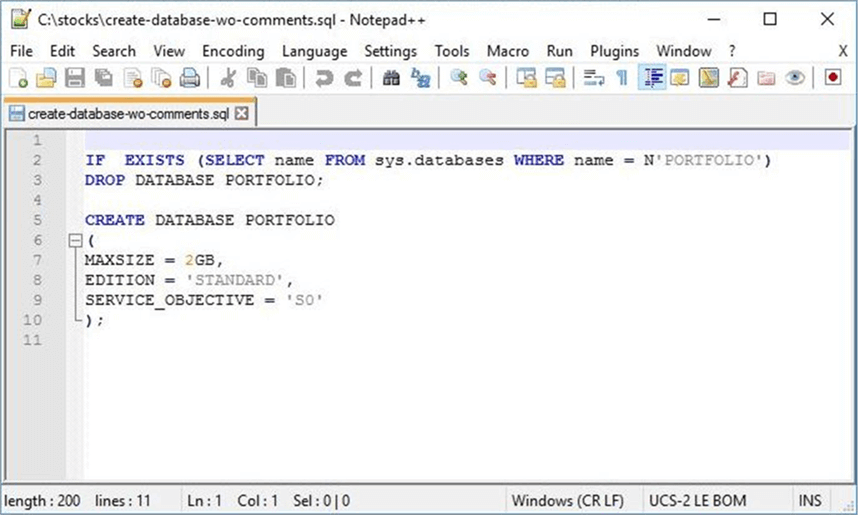
Did you realize there are three possible bugs in the above program?
I left them in the code to prove a point. The choice of input during testing is key. The code above removes any line that contains the following sequences “/*”, “--“, or “*/”. I am assuming that the first two sequences start at the beginning of the line and no real code is on that line. The last sequence assumes that no code comes after ending the comment. However, these assumptions can be broken by the lackadaisical programmer. I am going to leave the process of fixing the function up to you.
In a nutshell, advanced functions allow you to take advantage of features such as Write-Verbose. Adding these informative message helps you debug the program now and gives you information in the future during a production issue.
Reading web pages
There are many sites such as Wikipedia that have a wealth of information. For instance, there is a web page that contains details on the S&P 500 companies. How can we read that data from the internet?
Many of these web sites use old fashion html tables to display the data. The function below named Get-WebRequest-Table will read data from a web page and return the information from table n as a PowerShell object. Many times, I find a function that someone created and make it my own. I always give them credit when it is due. See Lee Holmes blog for the code base for this function.
The Invoke-WebRequest cmdlet is key to this function. It downloads the data from the web site into a HTML document object model (DOM). The rest of the code works on creating a hash table from the html data. The final result is returned as a PowerShell custom object.
#
# Name: Get-WebRequest-Table
# Purpose: Grab data from internet.
#
function Get-WebRequest-Table {
[CmdletBinding()]
param(
[Parameter(Mandatory = $true)]
[String] $Url,
[Parameter(Mandatory = $true)]
[int] $TableNumber
)
# Make are web request
$request = Invoke-WebRequest $url
# Extract the tables
$tables = @($request.ParsedHtml.getElementsByTagName("TABLE"))
# Pick which table #?
$table = $tables[$TableNumber]
# Header data
$titles = @()
# Row data
$rows = @($table.Rows)
# Go through all rows in the table
foreach($row in $rows)
{
# Get the cells
$cells = @($row.Cells)
# Found table header, remember titles
if($cells[0].tagName -eq "TH")
{
$titles = @($cells | % { ("" + $_.InnerText).Trim() })
continue
}
# No table header, make up names "P1", "P2", ...
if(-not $titles)
{
$titles = @(1..($cells.Count + 2) | % { "P$_" })
}
# Ordered hash table output
$output = [Ordered] @{}
# Process each cell
for($counter = 0; $counter -lt $cells.Count; $counter++)
{
# Grab a title
$title = $titles[$counter]
# Just in-case we have an empty cell
if(-not $title) { continue }
# Title to value mapping
$output[$title] = ("" + $cells[$counter].InnerText).Trim()
}
# Finally cast hash table to an object
[PSCustomObject] $output
}
}
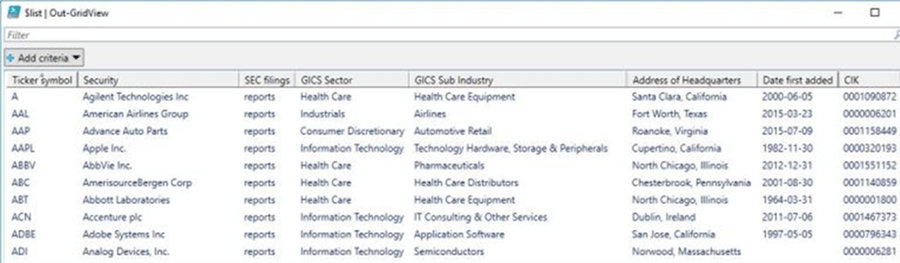
The PowerShell script below tests our new function. It reads the S&P 500 company list from the internet and saves it as an object. The contents of the object are displayed in the console window. The Export-Csv cmdlet is used to save the data as a tab delimited file. To wrap up the example, the company data is displayed in a grid view. I really like the grid view since you can sort and filter the rows of data.
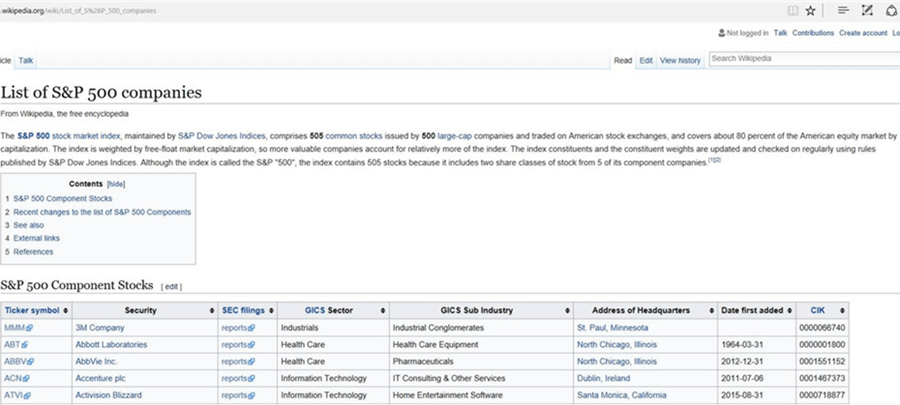
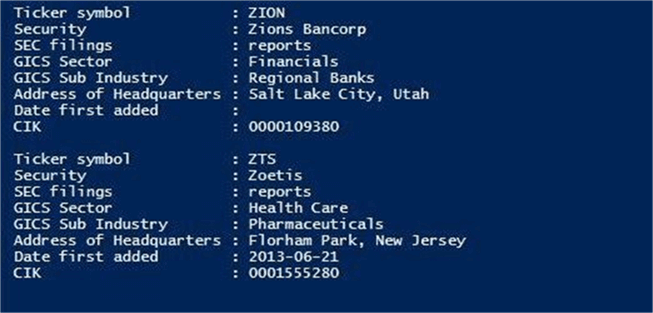
# # 7 - Save S&P 500 html table to tab delimited file # # Pull data from Wikipedia $site = 'https://en.wikipedia.org/wiki/List_of_S%26P_500_companies' $list = Get-WebRequest-Table -Url $site -TableNumber 0 # Show the data $list # Save as tab delimited file $list | Export-Csv -NoTypeInformation -Path "c:\stocks\S&P-500.txt" -Delimiter `t # peak at data in grid $list | Out-GridView
The Wikipedia web page that contains the information that we want.
The resulting data stored as an array of records.
The Out-GridView cmdlet is very handy in investigating your data set. It allows you to sort and filter the data to gain insight.
If we open the text file with the notepad++ application, we can see that it is formatted as a tab delimited file.
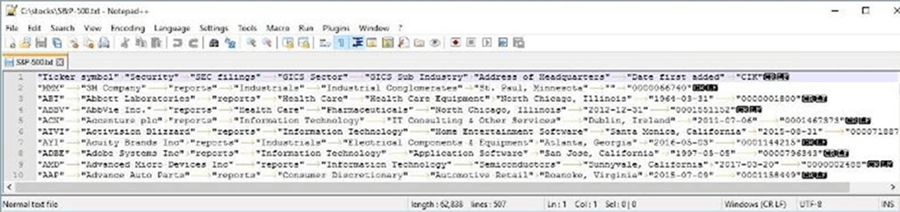
I think a brief summary of this section is in order. The Invoke-WebRequest cmdlet can be used to read in data from a web page. The custom advanced function named Get-WebRequest-Table adds additional functionally to the previous command. It finds a selected table by numerical order in the html data stream and returns a custom PowerShell object.
Delimited files
There are many flavors of delimited text files. Comma separated values are recognized automatically by Microsoft Excel. Tab delimited files are also common to see in the industry. Then there are the custom delimited files that use characters like “|”, “~” or etc. The good thing is that the Import-Csv cmdlet will read all those files in accurately given the correct delimiter. The compliment of this function is the Export-Csv cmdlet which writes out the data to a text file in the correct format.
The PowerShell script below reads in the tab delimited file that contains the S&P 500 company data. The column headers are not named with single words and include white space. Such field names in SQL Server would be a pain since we would have to quote them. Therefore, I am going to use the Select-Object cmdlet to rename each column and assign the correct data type. The resulting data is written to a comma separated value (CSV) file.
#
# 8 - Reformat list & save as csv file
#
# Read in data
$input = Import-Csv -Path "c:\stocks\S&P-500.txt" -Delimiter `t
# Reformat data
$output = $input |
Select-Object @{Name="Symbol";Expression={[string]$_."Ticker symbol"}},
@{Name="Security";Expression={[string]$_."Security"}},
@{Name="Sector";Expression={[string]$_."GICS Sector"}},
@{Name="Industry";Expression={[string]$_."GICS Sub Industry"}},
@{Name="Address";Expression={[string]$_."Address of Headquarters"}},
@{Name="Date";Expression={[datetime]$_."Date first added"}};
# Show the data
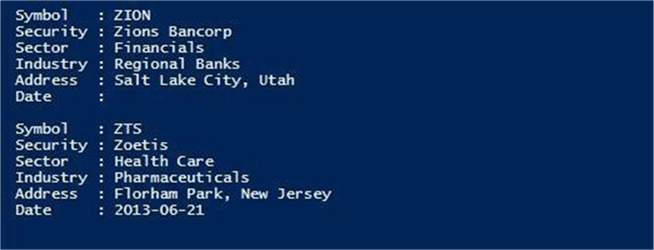
$output
# Save as csv file
$output | Export-Csv -NoTypeInformation -Path "c:\stocks\S&P-500.csv" -Delimiter ','
A screen shot of the console window in PowerShell ISE application. The $output variable is displayed to the console window. The last two companies are seen below with the columns renamed.
The image below shows the S&P 500 companies in two different file formats. We can see that the Export-Csv cmdlet incorrectly quoted the date field in the output. This is an important fact to note.
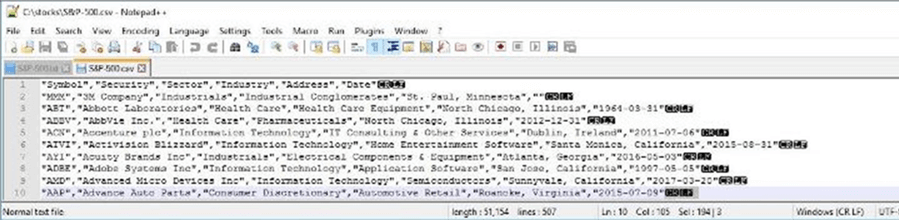
To wrap up this section, working with delimited files can easily be done in PowerShell. The Import-Csv cmdlet reads files in and the Export-Csv cmdlet writes files out.
Financial data
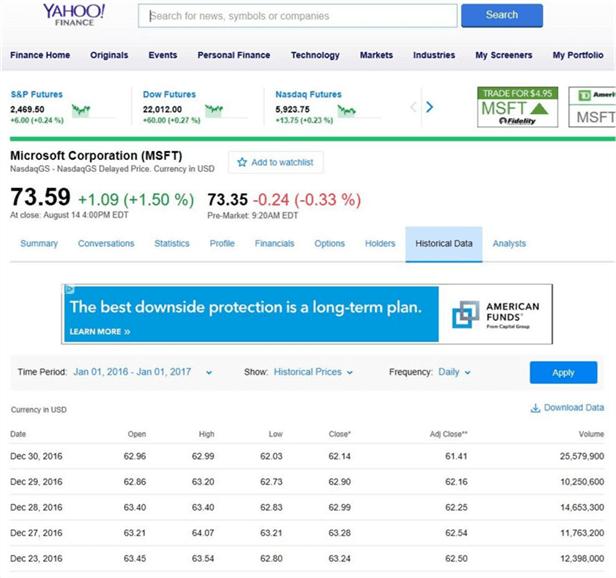
The historical data section of the Yahoo Financials site allows you to download stock data for a given symbol. Make sure you enter the correct S&P 500 symbol and the correct date range. Next, click the apply button followed by the download data button. Choose a location to save the table.csv file.
Here is a sample call to web page for the Microsoft stock ticker symbol for the 2016 calendar year.
The image below shows the downloaded information saved as a CSV file. Of course, I gave the file a more appropriate name. I added highlighting to the first row to make the column headers stand out.
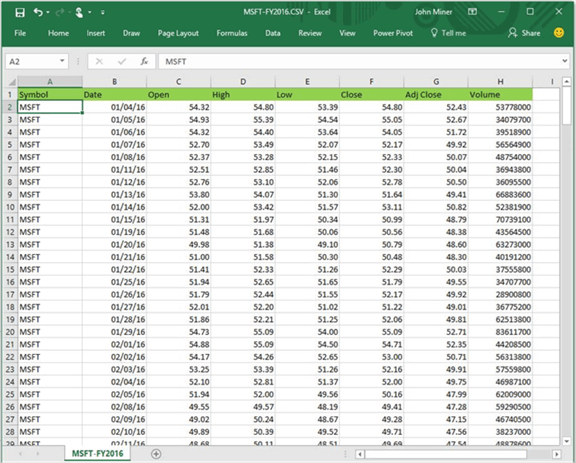
Now that we know where the data is, we just need to write an automated program to download it.
Business solution
Designing and implementing a business solution is an iterative process. We might start with a high-level algorithm like below and refine it along the way.
#
# Algorithm #1
#
Read Stock List CSV file
For Each Stock
Begin
Make Web Call
Extract Data
Save Data to a CSV file
End
How can we dynamically call this URL from PowerShell to obtain 2016 historical data?
The Yahoo Financials URL has three parameters that we need to change. First, the stock symbol is part of the URL path. Second, the begin and end periods are formatted as Unix time and are passed as query string parameters. This means we need to calculate the number of elapsed seconds from January 01, 1970 for each of the given dates. The PowerShell code below tries to grab the Microsoft daily stock data for the 2016 calendar year.
Guess what happens?
# # 9 – First try at a solution # # Period 1 $TimeSpan1 = [DateTime]'2016-01-02' - [DateTime]'1970-01-01'; $TimeSpan1.TotalSeconds # Period 2 $TimeSpan2 = [DateTime]'2017-01-01' - [DateTime]'1970-01-01'; $TimeSpan2.TotalSeconds # My company $symbol = 'msft' # Dynamic Url $site = 'http://finance.yahoo.com/quote/' + $symbol + '/history?period1=' + $TimeSpan1.TotalSeconds + '&period2=' + $TimeSpan2.TotalSeconds + '&interval=1d&filter=history&frequency=1d' # Grab table $list = Get-WebRequest-Table -Url $site -TableNumber 0
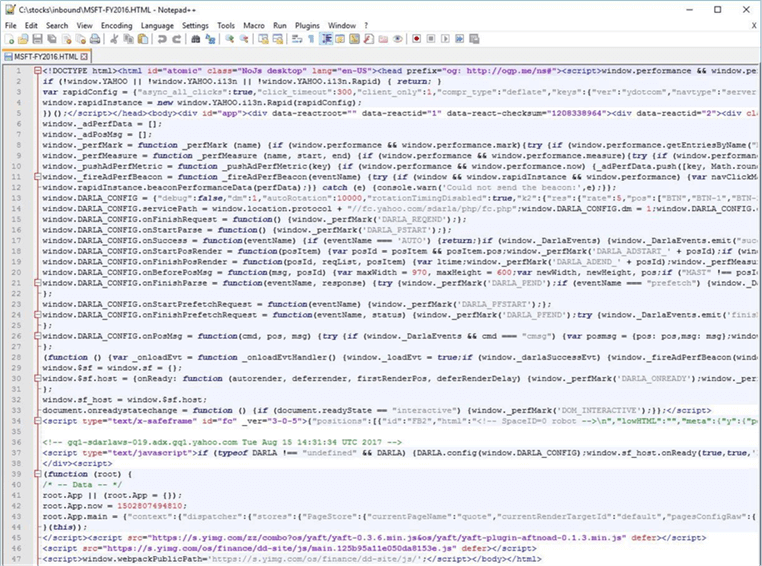
The call to the Get-WebRequest-Table cmdlet never completes processing. Something unexpected is going on. Let us manually save the web page to our hard drive under the c:\stocks\inbound directory. I am going to open the file with my notepad++ application and examine the contents. This format was totally unexpected. Instead of html we have dynamic java script. The actual data that we want to capture is on line 43 and this data is stored as a JSON document.
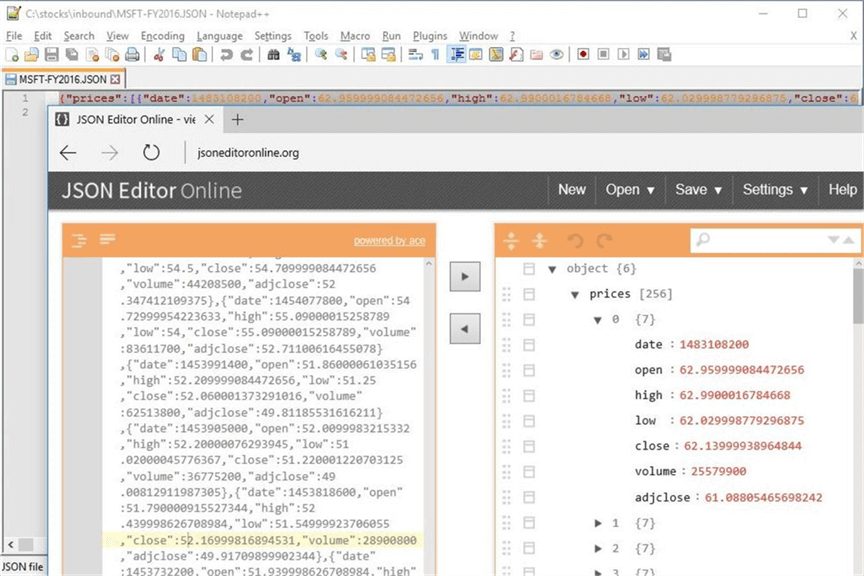
I took the original html document and saved it with a new extension. There is a free web site called jsoneditoronline.org that can be used to view the JSON document. We now have the data in a format just like our manual download. However, the date is in Unix time. This will need to be converted to MM/DD/YYYY format. See the image below for details using the MSFT historical data.
Now that we know the format of the web page, we can adjust our algorithm and come up with the final design. I labeled the code with comments that match each of the ALPHA characters in the algorithm below.
#
# Algorithm #2
#
A - Read Stock List CSV file
For Each Stock
Begin
C - Make Web Call
D - Save page as HTML file
E - Find JSON document
F - Trim document for just Prices
G - Save document as JSON file
H - Convert JSON to PS Object
I - Save PS Object to CSV file
End
The PowerShell script below down loads all S&P 500 companies and saves historical stock data for calendar 2016 as comma separated value files. While PowerShell has many built in cmdlets, sometimes you must use the .NET framework for certain tasks. In section C of the code, I am using the System.Net.WebClient class to create an object the will read and save the web page as a file. In section I of the code, I am using the System.IO.StreamWriter to ensure that numeric and date fields are not quoted in the final output file.
As a homework assignment, I charge you with the task to convert Section I into a re-usable advance function named Convert-ToCsv2.
#
# 10 - Getting historical data
#
<# Section A #>
# Set working directory
Set-Location "c:\stocks"
# Read csv file
$list = Import-Csv -Path "S&P-500.csv" -Delimiter ',' -Encoding ascii | Sort-Object -Property symbol
# Period 1
$TimeSpan1 = [DateTime]'2016-01-02' - [DateTime]'1970-01-01';
# Period 2
$TimeSpan2 = [DateTime]'2017-01-01' - [DateTime]'1970-01-01';
# File Counter
[int]$cnt = 0
# For each stock
foreach ($stock in $list)
{
<# Section B #>
# Create variables used by process
$symbol = $stock.symbol
$site = 'http://finance.yahoo.com/quote/' + $symbol + '/history?period1=' + $TimeSpan1.TotalSeconds + '&period2=' + $TimeSpan2.TotalSeconds + '&interval=1d&filter=history&frequency=1d'
$html = 'c:\stocks\inbound\' + $symbol + '-FY2016.HTML'
$json = 'c:\stocks\inbound\' + $symbol + '-FY2016.JSON'
$csv = 'c:\stocks\outbound\' + $symbol + '-FY2016.CSV'
<# Section C #>
# Read in web page
$response = (New-Object System.Net.WebClient).DownloadString($site)
<# Section D #>
# Write web page as file
$response | Out-File -FilePath $html
<# Section E #>
# Find outer document (json)
$content = Get-Content $html
foreach ($line1 in $content)
{
if ($line1 -match 'root.App.main')
{
$main = $line1
}
}
<# Section F #>
# Remove java script tags
$main = $main.Substring(16, $main.Length-17)
# Find inner document (json)
$start = $main.indexof('"HistoricalPriceStore"')
$end = $main.indexof('"NavServiceStore"')
$len = $end-$start-24
$prices = $main.Substring($start+23, $len)
<# Section G #>
# Write json document
$prices | Out-File $json
# Convert to PowerShell object
$data = $prices | ConvertFrom-Json
<# Section H #>
# Reformat data & remove dividends
$output = $data.prices |
Select-Object @{Name="symbol";Expression={[string]$symbol}},
@{Name="date";Expression={([datetime]"1/1/1970").AddSeconds($_."date").ToString("MM/dd/yyyy")}},
@{Name="open";Expression={[float]$_."open"}},
@{Name="high";Expression={[float]$_."high"}},
@{Name="low";Expression={[float]$_."low"}},
@{Name="close";Expression={[float]$_."close"}},
@{Name="adjclose";Expression={[float]$_."adjclose"}},
@{Name="volume";Expression={[long]$_."volume"}} |
Where-Object {-not [string]::IsNullOrEmpty($_.volume) -and ($_.volume -ne 0) }
<# Section I #>
# Open file
$stream = [System.IO.StreamWriter]::new( $csv )
# Write header
$line2 = '"symbol","date","open","high","low","close","adjclose","volume"'
$stream.WriteLine($line2)
# For each line, format data
$output | ForEach-Object {
$line2 = [char]34 + $_.symbol + [char]34 + "," + [char]34 + $_.date + [char]34 + "," +
$_.open + "," + $_.high + "," + $_.low + "," + $_.close + "," + $_.adjclose + "," + $_.volume
$stream.WriteLine($line2)
}
# Close file
$stream.close()
<# Section J #>
# Status line
$cnt = $cnt + 1
Write-Host ""
Write-Host $cnt
Write-Host $csv
}
I chose to open the Microsoft stock file out of the 505 files that exist in the outbound directory. The image below shows the first 12 lines of the CSV file opened with the notepad++ application.
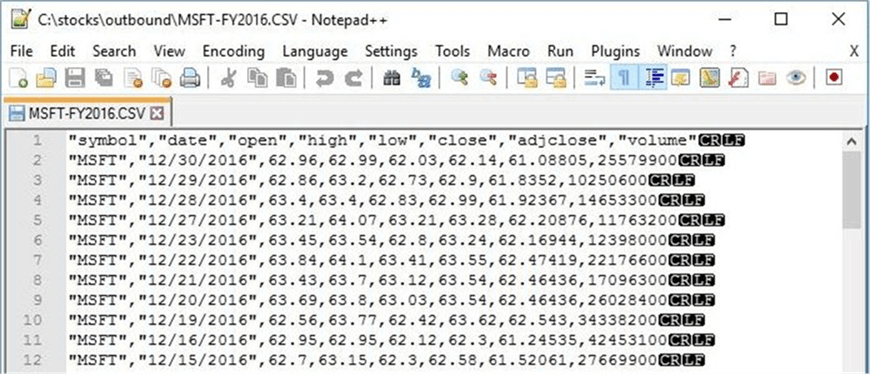
Summary
The enclosed file provides the whole solution to the Big Jon’s Investments business problem. This includes creating the directory structure, down loading the S&P 500 list and down loading 2016 historical stock data for each company. Our boss will be happy that we now have the data for the investments department.
Today, we learned about the four *-Content cmdlets that work with files on a line by line basis. Also, the two *-Csv cmdlets allow the script designer to work with various delimited files. The use of all these cmdlets is pretty straight forward.
Working with web content can be quite tricky. The Get-WebRequest-Table cmdlet works just fine with plain HTML; However, the java script code on the Yahoo Financials page resulted in an infinite loop with our custom defined function. The best part of PowerShell is that the .NET library functions can easy be called. The WebClient class helped us deal with the web page entirely composed of java script code. The StreamWriter class allowed us to write our final output in a format that way we wanted. In short, the ability to use the .NET library was invaluable.
Now that we have our historical stock data, we need to load it into either an Azure SQL database or an Azure SQL data warehouse for analysis. That is a topic for another time.
Next Steps
- Download the PowerShell code.
- Reading and writing fixed length files.
- Reading and writing binary files.
- Reading and writing HTML files.
- Reading and writing XML files.
- Reading and writing JSON files.






About the author
 John Miner is a Data Architect at Insight Digital Innovation helping corporations solve their business needs with various data platform solutions.
John Miner is a Data Architect at Insight Digital Innovation helping corporations solve their business needs with various data platform solutions.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2017-09-15
