By: Koen Verbeeck | Updated: 2017-10-23 | Comments | Related: > Analysis Services Performance
Problem
With the release of SQL Server 2017, a couple of new enhancements have been introduced for Analysis Services Tabular. One of those improvements is the ability to specify an encoding hint for certain columns. In this tip, we’ll introduce the concept of encoding hints and explain how we can improve processing performance of large tables by avoiding the re-encoding of a column.
Solution
In Analysis Services (SSAS) Tabular, columns are encoded before the compression phase of the processing. This process converts all data to integers (even strings and other data types) since they offer the best performance. There are two types of encoding:
- Value encoding - Here the value of the cell itself is used. It’s possible a mathematical operation is included. For example, if a column contains the values 10,000 and 10,001, SSAS can subtract 10,000 from the values and keep the results 0 and 1, which can be stored using fewer bits. Whenever the data is needed, SSAS only needs to add 10,000 again to retrieve the original values. Typically columns used in aggregations benefit from value encoding.
- Hash encoding - With this type of encoding, the values are transformed into meaningless integers. This transformation step is then kept in a dictionary, so SSAS can translate the integers back to the original value. Hash encoding is used for string columns and for every column where value encoding is less efficient (for example if the column is very sparsely distributed). Typically columns used as group-by columns or foreign keys benefit from hash encoding.
In most cases, value encoding is more efficient because the values itself can be used (perhaps with the mathematical operation) in measures, leading to better query performance. In the previous example, SSAS just needs to add 10,000 to all values and sum them in order to calculate a SUM formula. With hash encoding, you can use the dictionary values for COUNT formulas, but for other aggregations the original values need to be calculated.
During the processing of a table, SSAS will inspect a column using sample values and decide if value or hash encoding will be used for a column. It is possible when a column is partially processed, it becomes clear the column would benefit from the other encoding method. This means SSAS has to start over and switch between encoding methods, which is an expensive operation for large tables. In the SSAS 2017 release, we can specify an optional hint for a column where you specify an encoding method.
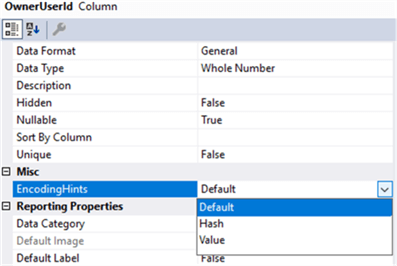
By setting an encoding hint, you might improve processing performance if re-encoding happens with the default settings.
Verifying the Encoding Method
First of all, we need to be able to check the current encoding method for a column. Using a very simple Tabular model built on top of the Posts table of the StackOverflow database, we can retrieve the encodings using the following data management view:
SELECT COLUMN_ID, DATATYPE, COLUMN_ENCODING FROM $SYSTEM.DISCOVER_STORAGE_TABLE_COLUMNS WHERE COLUMN_TYPE = 'BASIC_DATA' AND MEASURE_GROUP_NAME = 'Posts_CCI'
I executed this statement in a DAX query window:
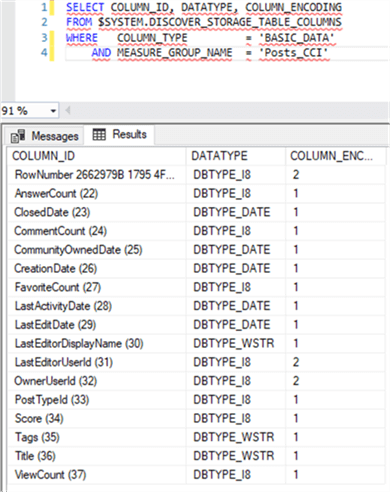
A value of 1 indicates hash encoding while 2 indicates value encoding. As you can see, only three columns have value encoding: the internal row number, LastEditorUserId and OwnerUserID. The first one makes sense since the values itself can easily be used. The other two columns probably have a dense distribution, while the other integer columns do not.
Detecting a Re-encoding Event
When SSAS needs to switch encoding for a column, the event “55 – switching dictionary” is launched, under the class Progress Report End. We can capture this with SQL Server Profiler or with Extended Events. The last option is explained in the tip Extracting a DAX Query Plan With Analysis Services 2016 Extended Events. With the following XMLA statement we can create an XEvents trace:
<Create xmlns= "http://schemas.microsoft.com/analysisservices/2003/engine">
<ObjectDefinition>
<Trace>
<ID>Test</ID>
<Name>Test</Name>
<XEvent xmlns="http://schemas.microsoft.com/analysisservices/2011/engine/300/300">
<event_session name="Test" dispatchLatency="1" maxEventSize="4" maxMemory="4" memoryPartition="none" eventRetentionMode="AllowSingleEventLoss" trackCausality="true" xmlns="http://schemas.microsoft.com/analysisservices/2003/engine">
<event package="AS" name="QueryBegin" />
<event package="AS" name="QueryEnd" />
<event package="AS" name="CommandBegin" />
<event package="AS" name="CommandEnd" />
<event package="AS" name="ProgressReportBegin" />
<event package="AS" name="ProgressReportEnd" />
<target package="package0" name="event_stream" />
</event_session>
</XEvent>
</Trace>
</ObjectDefinition>
However, even when fully processing the entire Posts table of the StackOverflow database (about 33 million rows), no re-encoding happened. So let’s force this by making the OwnerUserID a bit more sparsely populated:
UPDATE [StackOverflow].[dbo].[Posts_CCI] SET [OwnerUserId] = 2147483647 WHERE [OwnerUserId] = 7278893;
The ID 7278893 has only two rows in the table. By changing the ID to 2,147,483,647 (the maximum value for an integer), we make this column unsuitable for value encoding. But since there are only two rows with this large value, it’s likely it will not be detected during sampling. This means SSAS will go for value encoding first, but when encountering this value it will need to switch to hash encoding.
To start the processing of the table, we can use the following JSON statement (which needs to be executed in an XMLA query window):
{
"refresh": {
"type": "full",
"objects": [
{
"database": "StackOverflow",
"table": "Posts_CCI"
}
]
}
}
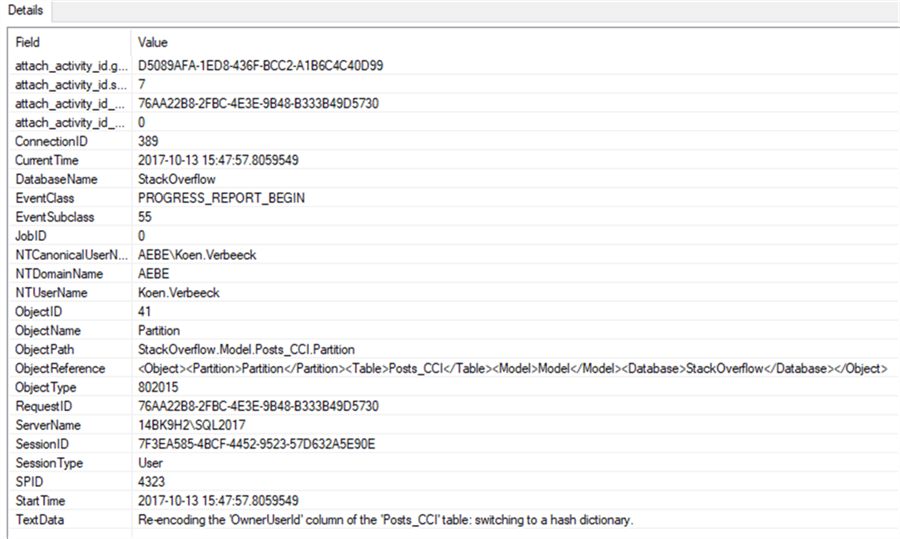
During processing, we can see the re-encoding event in XEvents. Here’s the Progress Report Begin event, announcing the switch to hash encoding:
The Progress Report End event:
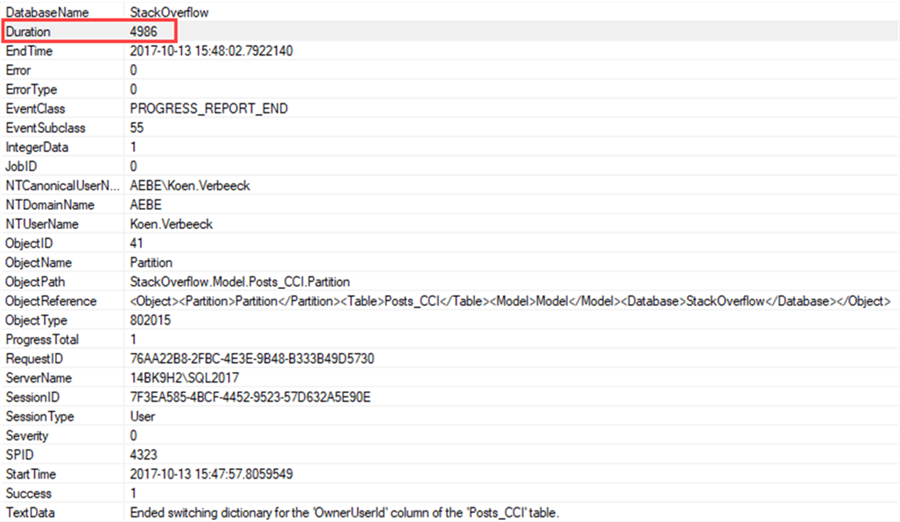
The duration of this event was almost 5 seconds. By specifying a correct encoding upfront, we might avoid this extra overhead during processing. The current encoding method can be verified using the DMV:
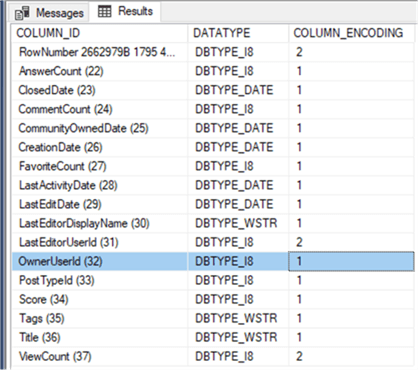
The OnwerUserId column now uses hash encoding indeed.
Specifying Encoding Hints
Let’s set the OwnerUserID column to hash encoding.
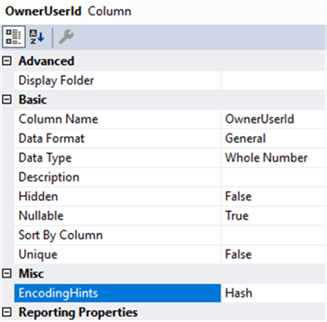
The LastEditorUserID and PostTypeID columns are foreign keys as well, so let’s set it to hash encoding too. ViewCount, Score, FavoriteCount, CommentCount and AnswerCount are measures, so they are set to Value encoding.
After redeploying and reprocessing the model, we can check the encoding of the columns:
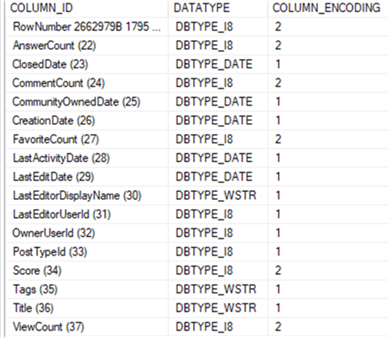
All of the hints had their desired effect: measures have value encoding, foreign keys have hash encoding. Because OwnerUserID now uses hash encoding from the start, which avoids the re-encoding event.
Next Steps
- You can find an overview of all new Analysis Server 2017 features in the official documentation.
- If you are interested in knowing more about encoding and the internals of processing a Tabular model, you can check out the Performance Tuning of Tabular Models in SQL Server 2012 Analysis Services whitepaper. It’s about the first version of SSAS Tabular, but a lot of the internals are still the same. There’s a whole section about the encoding methods.
- You can find more Analysis Services tips in this overview.






About the author
 Koen Verbeeck is a seasoned business intelligence consultant at AE. He has over a decade of experience with the Microsoft Data Platform in numerous industries. He holds several certifications and is a prolific writer contributing content about SSIS, ADF, SSAS, SSRS, MDS, Power BI, Snowflake and Azure services. He has spoken at PASS, SQLBits, dataMinds Connect and delivers webinars on MSSQLTips.com. Koen has been awarded the Microsoft MVP data platform award for many years.
Koen Verbeeck is a seasoned business intelligence consultant at AE. He has over a decade of experience with the Microsoft Data Platform in numerous industries. He holds several certifications and is a prolific writer contributing content about SSIS, ADF, SSAS, SSRS, MDS, Power BI, Snowflake and Azure services. He has spoken at PASS, SQLBits, dataMinds Connect and delivers webinars on MSSQLTips.com. Koen has been awarded the Microsoft MVP data platform award for many years.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2017-10-23
