By: Rick Dobson | Updated: 2017-11-06 | Comments (7) | Related: > SQL Server 2017
Problem
Our company needs HTML table contents from different web pages around the internet to support our analytical initiatives and for basic data tracking requirements. Please provide a sample programmatic solution to download HTML table contents into SQL Server tables that is cheap, easy to implement, and runs quickly.
Solution
Scraping web pages is a powerful tool for harvesting data from the internet for SQL Server tables. MSSQLTips.com previously introduced a Python-based approach for extracting data from the internet to SQL Server. The prior solution focused on harvesting data from h1 and anchor HTML tags within web pages. That prior tip also demonstrated how to consolidate data from different web pages into a SQL Server table.
The introductory solution on scraping web pages with Python for SQL Server did not consider HTML tables as sources for populating SQL Server tables. However, HTML tables are widely used at web sites because of their flexibility for containing and arranging data. HTML table tags contain a set of row tags each of which contains a set of cell tags. Each cell within a row set can contain text, links, images, and other tagged content. You need to account for this kind of diversity when devising data extraction strategies for HTML tables. Also, a single web page can easily have multiple HTML tables. Therefore, before starting to extract and download data from an HTML table within a web page at a web site, you may need to select a specific table from a web page at a site.
This tip demonstrates how to extract all NASDAQ stock ticker symbols and some related company data from the NASDAQ web site. A ticker is an alphanumeric string representing a stock. NASDAQ is a stock trading exchange for thousands of companies from throughout the world. Many of these companies are technology-related so they are potentially of interest to SQL Server professionals.
The NASDAQ web site also makes available stock tickers for other major exchanges, such as NYSE and AMEX exchanges. These additional resources enable you to readily extend the approach demonstrated here for stocks traded on other non-NASDAQ exchanges. Also, the same general approach to downloading ticker data from HTML tables on the internet is broadly applicable to web sites containing data for different types of domains, such as from congressional members to jail inmates. Just before the Next Steps section, this tip itemizes some general guidelines for downloading data from any kind of web page to SQL Server.
Getting started with web scraping with Python for SQL Server
There are three preparatory steps for scraping web pages via Python with HTML tables for SQL Server tables.
- Install Python; this tip shows screen shots for step-by-step guidelines on how to install Python for all users on a server.
- Configure SQL Server for securely running Python scripts and importing data into SQL Server; this tip dives deeply into this topic.
- Install and load the BeautifulSoup external library for Python; this library dramatically improves your ability to extract data easily from web pages.
The Python software and associated external libraries are available for download from the internet without charge. This makes the approach cheap - actually, FREE!
There are two key libraries to reference when web scraping with Python 3.6. The Requests library is a built-in Python library that lets your code specify a URL and receive a response from the site. If your code connects to the url successfully, Python will get a response from the web site just like a browser does when you point a browser at a URL. The text from your Python request to the URL is coded as HTML text. You can inspect the returned HTML text and compare it to a browser display of url content to get a feel for how data is encoded in the HTML.
Also, Python is both an exceptionally robust language and an easy language in which to program. These considerations are among the reasons that Python is growing rapidly in popularity among developers. This is, in turn, among the considerations why Microsoft opted to allow 2016 and 2017 versions of SQL Server to launch Python programs, but this tip shows you how to launch Python programs from any version of SQL Server that can run the xp_cmdshell extended stored procedure, which is at least as far back as SQL Server 2000.
Furthermore, it is relevant to point out that you can readily capture Python program output for storage in SQL Server tables. This tip demonstrates a reliable approach for capturing in SQL Server Python program output. In my experience, this technique for capturing Python output runs quickly and with any version of SQL Server supporting the xp_cmdshell extended stored procedure.
Visually inspecting HTML table sources for web scraping
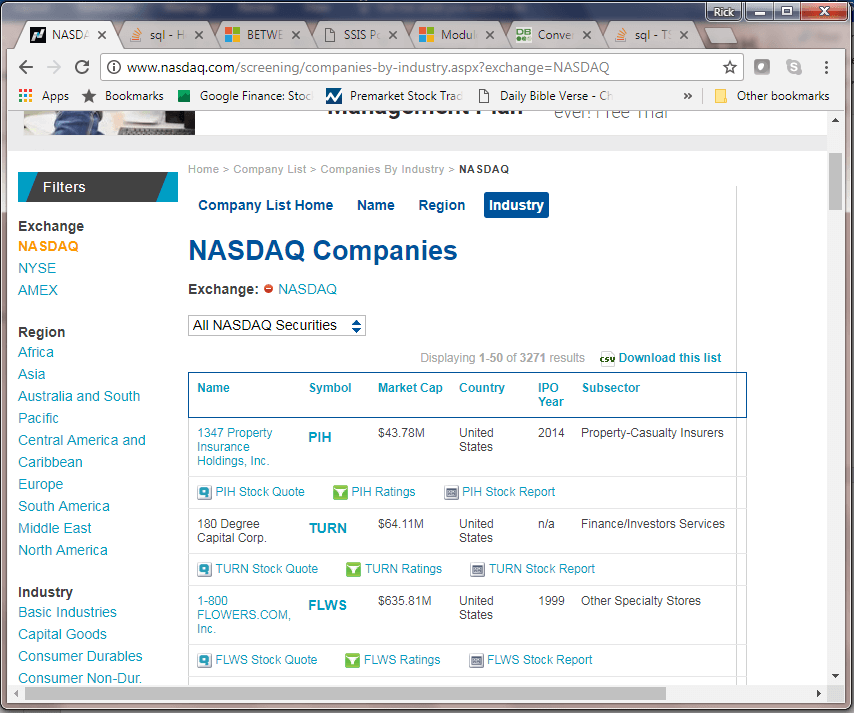
As indicated in the Solution section, this tip reveals how to download selected content from an HTML table at the NASDAQ web site. The heading and first several rows of the HTML table appear in the following screen shot.
- Notice that the browser references the companies-by-industry.aspx page from the www.nasdaq.com web site; the address box in the browser also includes a parameter value of NASDAQ, which is passed via the exchange parameter to the web site. The parameter value specifies a request for data just for companies listed on the NASDAQ exchange.
- The table in the browser window displays a column header row followed by pairs of rows for each stock ticker value.
- Just above the header row is a brief message (Displaying 1-50 of 3271 results)
which indicates
- the browser displays data for the first 50 ticker values along with associated company data
- there were 3271 ticker values in total within the source HTML table for companies listed on the NASDAQ exchange web site as of the date the screen shot was taken; this number can go up and down over time according to stock performance and NASDAQ rules for including tickers in the web page
- Data on three companies are displayed in the browser window from the top
of the HTML table.
- The ticker values are: PIH, TURN, and FLWS; ticker values appear in the Symbol column of the HTML table.
- The corresponding company names for the three ticker values are: 1347 Property Insurance Holdings, Inc., 180 Degree Capital Corp., and 1-800 FLOWERS.COM, Inc.; company names appear in the HTML table's first column.
- Other column values appearing in the HTML table include: Market Cap, Country, IPO year, and Subsector, which is sometimes referred to as industry in stock financial reports.
- Below each row with a stock ticker and a company name is a second row with
links for getting more information about stock quotes and community ratings
as well as a link for a report on the stock for a company.
- The links for these three topics are denoted by both short descriptive text, such as PIH Stock Quote; an image appears just before each link.
- Clicking the short descriptive text opens a linked page. Users can click a browser's back icon to return from the new linked page to the HTML table with ticker symbols and related company-by-industry data.
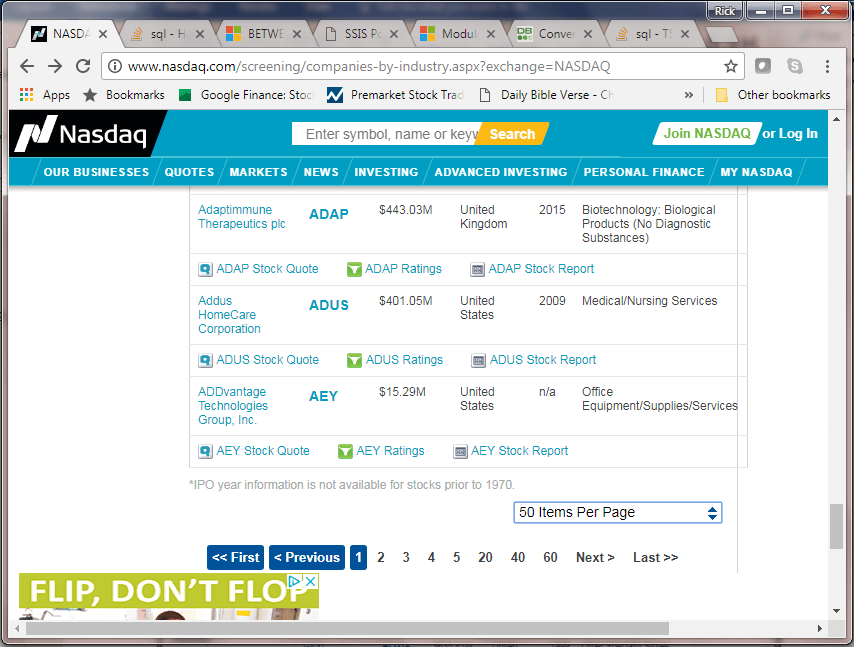
The next screen shot shows an image towards the bottom of the page from the preceding screen shot.
- The layout of the rows at the bottom of the page is the same as top of the page.
- Text below the pair of rows for the fiftieth ticker indicates that n/a is used for IPO Year when the year is prior to 1970.
- Below the text message is a drop-down box.
- A user browsing the page can change the default number of stocks from 50 per page to a different number, such as 100, 150, or 200 stocks per page.
- Making a selection can change the browser address box
- From: http://www.nasdaq.com/screening/companies-by-industry.aspx?exchange=NASDAQ
- To: http://www.nasdaq.com/screening/companies-by-industry.aspx?exchange=NASDAQ&pagesize=100
- You can also manually adjust the pagesize parameter in the browser's address box to a very large number. For example, a number of 4000 is currently large enough to ensure the browser displays all NASDAQ stock ticker values in a single window. If you want to show all ticker symbols no matter what the number of actively listed ticker symbols, there is no penalty for using a number larger than the maximum number of stock tickers. Showing company data for all ticker values in a single browser window simplifies programmatic data extraction because you can download data from just one page instead of a succession of different pages.
Programmatically inspecting an HTML table for web scraping
The following screen shot shows a simple Python script for getting all the row values from the HTML reviewed in the preceding section.
- The script starts with a reference to the BeautifulSoup external library. Although BeautifulSoup is not required by this simple script, it is generally nice to have when processing HTML pages. The reference to the BeautifulSoup external library will be required in a subsequent script.
- Next, the script references the internal Requests Python library.
- The Requests library has a get method which allows you to specify a url and return the HTML contents of the url as text that can be output by a Python print command.
Notice that the argument for the get method includes a pagesize parameter with a value of 4000. This value is more than large enough for the extraction of all NASDAQ ticker values and associated company data from the NASDAQ exchange web site.

The HTML page returned by the get method has several different table tags. The following screen shot from Notepad++ shows an excerpt from the top of the table tag for the table examined by browser views in the preceding section. The excerpt was copied from the IDLE output application that installs automatically with Python installations. Results were copied to Notepad++ because they were easier to examine in this application than IDLE.
- The table tag has a setting to specify an id value for the table, namely, id="CompanylistResults". The web page has multiple pairs of opening and closing table tags, but only one of these pairs has an id value of CompanylistResults.
- The initial HTML block within the CompanylistResults table tag is a thead
tag pair.
- Between the opening and closing thead tags is a single row with opening and closing tr tags.
- Within the tr block in the thead block are seven th tag pairs for each of seven columns within HTML table.
- The column names are successively:
- Name for Company name
- Symbol for ticker value
- Market Cap for the total market capitalization of the company
- ADR TSO for ADR total shares outstanding; this value applies only to selected non-US based stocks, such as those from China
- Country for where a stock is listed; non-US companies can have their ADR shares traded in US exchanges as well as in an exchange in their native country
- IPO Year designates the year when a company stock was initially offered for sale on the exchange
- Subsector is a category designating an industry in which the company for a stock primarily does business
- With the exception of the ADR TSO column values, all HTML table columns are meant for display in the browser. While the ADR TSO column is not meant for display in a browser, its value does get returned by the get method of the Python Requests library.
- This initial excerpt from the CompanylistResults table concludes with this commented line of text: <!-- begin data rows -->

The next excerpt from the CompanylistResults table block shows the first two rows of marked up data for the first ticker - the one with a value of PIH.
- This screen shot commences where the preceding one ends; the first commented line of text is <!-- begin data rows -->
- There are two pair of tr tags in this block
- One pair of tr tags is for the first seven columns of data presented by the HTML table; these first seven columns correspond to the th tag pairs in the thead section of the HTML table
- A second pair of tr tags is for a set of three quick links for getting
more information about a stock including
- Recent stock quote data
- Community ratings from site visitors (if there are any) for the stock
- Selected facts about the stock, including a brief description of the company, stock metrics, and financial metrics
Every stock in the HTML table, just like the stock for the PIH ticker, has two rows in the HTML table.

Programmatically listing the table rows for an HTML table
The following script is Python code for listing the rows and cells of the CompanylistResults HTML table at our source url. The code is from a file named all nasdaq companies with beautifulsoup.py. The two parameters at the end of the url for the get function argument designate the specific type of tickers (NASDAQ) and the maximum number of tickers (4000) that the script processes. For example, if there were only 3272 NASDAQ tickers when the ticker values were extracted, then information about stocks would only be extracted for 3272 stocks although the pagesize parameter is set to 4000.
Comment lines start with a # sign. This Python code sample starts similarly to the one for inspecting the page. Namely, it extracts all text values from the page and saves them in a Python variable (data). However, instead of immediately printing the page contents after this, the code transfers the text values to the BeautifulSoup library for parsing with the its html parser; the BeautifulSoup library also has a xml parser.
The next line of code extracts and saves the HTML for the table with an id value of CompanylistResults. This table contains all NASDAQ tickers along with associated information, such as company name and market capitalization.
Within each row of the selected table, there are the cells for all column values according to the headings denoted in the thead block. Nested for loops pass through each cell value for each row in the table.
Two functions clean up the output from the Python code.
- The get_text function extracts just the text value from the HTML within a cell.
- Then, the strip function removes leading and trailing blanks from the text value within each cell. If there is no text in a cell (as is often the case for cells in the ADR TSO column), then the function returns a zero-length string value.
#import BeautifulSoup
from bs4 import BeautifulSoup
#import request
import requests
#specify a web page from which to harvest ticker symbols
#and submit the returned html to BeautifulSoup for parsing
r=requests.get('http://www.nasdaq.com/screening/companies-by-industry.aspx?exchange=NASDAQ&pagesize=4000')
data = r.text
soup = BeautifulSoup(data, "html.parser")
#select a specific table from the html page
#loop through rows of the table
#loop through the cells of a row
#results in 14 lines of text per symbol
table = soup.find( "table", {"id":"CompanylistResults"} )
for row in table.findAll("tr"):
for cell in row("td"):
print (cell.get_text().strip())
An excerpt from the preceding script's output appears in the following screen shot. The first seven lines of output for the first stock are highlighted.
- Each stock has its values represented by output in fourteen lines.
- The second line of each set of fourteen lines for a stock denotes the ticker value.
- If there are no outstanding ADR shares, the fourth line is an empty string value.
- The first three lines and fifth through the seventh lines are for
- 1 - company name
- 2 - ticker
- 3 - market cap
- 5 - country
- 6- ipo year
- 7 - industry
- The eighth line is for the text of the first of three links on the second row for a stock. The text for the eighth line has its leading and trailing blanks removed by the strip function. However, the strip function only applies to the first of three links in the second row for a stock.
- The second two links on the second row for a stock do not have their leading and trailing blanks removed. As a consequence, the text for each of the second two links on the second row occur on three lines each - two blank lines followed by a third line with leading blanks before the ticker.
- Therefore, each stock in the HTML table has its values represented by 14
lines of Python script output which consists of:
- 8 lines that have leading and trailing blanks removed
- 3 lines for the first of the two final links
- 3 lines for the second of the two final links

You can confirm the validity of the extracted row values by comparing those from the preceding screen shot with those from the first excerpt for the browser page of NASDAQ ticker symbols and related information in the Visually inspecting HTML table sources for web scraping section. Slight differences between the Python output image and the browser output image are possible when the two images were taken at different times. The stock market data are like data from a typical production database - it can change so long as transactions are occurring or other processing is occurring to update the data in a database.
Reading Python parsed table output to populate a SQL Server table
Now that all NASDAQ stock tickers and associated company data are extracted via a Python program, we can shift our focus to transferring the results to a SQL Server table. This transfer is for all NASDAQ stock tickers from the NASDAQ site as of the time the transfer is run. Also, the process for transferring Python program output to a SQL Server table are broadly applicable whenever you have a need for copying all or some contents from an HTML table to a SQL Server table.
When transferring the output from a Python program to a SQL Server table, one robust technique is to run the Python program from a command window and then capture the results returned by the program to the command window. Several prior MSSQLTips.com tips demonstrated how to do this including this introductory tip to transferring Python program output to SQL Server and this prior tip on collecting end-of-day stock price data with Python for input to a SQL Server table.
To help clarify this specific transfer of results from an HTML table, the processing is discussed in three distinct steps.
- The first step takes the unprocessed output from a Windows batch file that runs the Python program showing table cells values and adds a sequence number to facilitate subsequent steps. Each row receives a number from 1 for the first row through to the count of the number of rows for the last row returned by the Python program.
- As shown in the preceding section, each ticker is returned as part of a
set of 14 lines of output for a stock from the Python program. Some lines for
a stock are blank and other results are not of interest because they pertain
to a small sample of tickers (ADR TSO). When you download data from an HTML
table at a web site, you may very well not need all the original columns. Our
second processing step performs three functions.
- It selects a subset of the original HTML columns for inclusion in the SQL Server table.
- Next, it assigns a distinct ticker number value to all the lines pertaining to a stock.
- Then, lines are indexed by position in a consistent fashion across stocks so that company name and ticker as well as other stock identifiers appear in the same order for all stocks.
- The third step performs additional processing including pivoting the results so that the final display of the Python output in the SQL Server table shows each stock ticker and its associated stock identifiers on a single row instead of as a list of rows with one row per stock identifier value. The pivoted format is a much easier way to examine and validate the results because the SQL Server table displays values in the same orientation as the HTML table.
The Windows batch file to run the Python program has the name all nasdaq companies with beautifulsoup.bat. There are two commands in the file.
- The first command changes the directory to the C:\Program Files\Python36\ path. This is where the Python interpreter is installed.
- The second command invokes the Python interpreter (python.exe) to run the Python script that reads the CompanylistResults HTML table from the NASDAQ web site. This command returns all the output from the Python program to the Windows command window.
cd C:\Program Files\Python36python.exe "C:\python_programs\all nasdaq companies with beautifulsoup.py"
A T-SQL script segment for invoking the all nasdaq companies with beautifulsoup.bat file appears next. This code segment is available from either the first and second processing of web scraping results.sql or third processing of web scraping results.sql files for this tip.
- The script segment starts by configuring SQL Server to run the xp_cmdshell extended stored procedure. It is this extended stored procedure that permits SQL Server to launch Windows batch files from within SSMS.
- Next, a temporary table named #Result is created to store the lines of output from the all nasdaq companies with beautifulsoup.bat file.
- Then, the insert statement with a nested exec statement for the xp_cmdshell extended stored procedure populates the #Result table with the output from the Windows batch file.
- The next-to-last step in the script re-configures SQL Server to disable the xp_cmdshell extended stored procedure. This step is to protect against cybersecurity threats from potential attackers.
- The final line in the following script segment is to display the raw unprocessed output. This output is not strictly necessary, but its review can help you to understand the process for populating a SQL Server table from an HTML table in the context of our stock ticker example.
-- for use by Python dev team members
-- enable the xp_cmdshell stored procedure
EXEC sp_configure 'xp_cmdshell', 1
RECONFIGURE
--------------------------------------------------------------------------------------
-- create a fresh temp table (#Result) for storing unprocessed result set from
-- running xp_cmdshell for Windows batch that invokes
-- python script
if exists (
select * from tempdb.dbo.sysobjects o
where o.xtype in ('U')
and o.id = object_id(N'tempdb..#Result')
)
BEGIN
DROP TABLE #Result;
END
CREATE TABLE #Result
(
line varchar(500)
)
--------------------------------------------------------------------------------------
-- insert python script output into #Result temp table
insert #Result exec xp_cmdshell 'C:\python_programs\"all nasdaq companies with beautifulsoup.bat"'
--------------------------------------------------------------------------------------
-- disable the xp_cmdshell stored procedure
EXEC sp_configure 'xp_cmdshell', 0
RECONFIGURE
GO
-- unprocessed output from all nasdaq companies with beautifulsoup.bat
select * from #Result
The first thirty-two rows from the #Results table in the preceding select statement appears in the screen shot below.
- The first four rows are not output from the Python program. Instead, rows
2 and 4 are for the commands in the all nasdaq companies with beautifulsoup.bat
file.
- The second line changes the directory to c:\Program Files\Python36\; this is where the Python application is installed.
- The fourth line invokes the Python interpreter for the Python program (all nasdaq companies with beautifulsoup.py).
- The first and third lines are Windows lines that return as NULL values through the xp_cmdshell extended stored procedure.
- The next 14 lines are for the stock with a PIH ticker value from the CompanylistResults HTML table. These lines match those from the first fourteen lines in the screen shot in the preceding Programmatically listing the table rows for an HTML table section.
- The last set of 14 lines are for the stock with a TURN ticker value from the CompanylistResults HTML table. These lines match the second set of fourteen lines in the screen shot in the preceding Programmatically listing the table rows for an HTML table section.
Just as the first and third lines contain values that map to NULL values in SQL Server so does the very last line in the #Result table. These NULL values are for lines that do not need to be processed for converting HTML table values to SQL Server table values.

The first processing step of the output from the all nasdaq companies with beautifulsoup.bat file is to assign sequence numbers to the rows. The purpose of assigning sequence numbers is to preserve the original order of the rows as output by the Windows batch file and the Python program invoked by the Windows batch file. This is necessary for a couple of reasons.
- First, you need to handle separately the first four rows and last row from the output in the #Result table because these rows do not contain HTML table rows for mapping to the SQL Server instance of the table.
- Second, you need to be able to keep the rows of output in the order that they are originally generated from the Python program. Recall that each stock has a block of 14 rows in the Python program output. Furthermore, there is a set order for the occurrence of value types, such as ticker and company name, within a block of 14 rows. Assigning sequence numbers from a sequence object provides a basis for keeping track of the 14-row blocks for individual stocks and the order of different value types within a 14-row block.
The following T-SQL excerpt demonstrates how this step is accomplished with a sequence object and a new temporary table named #Result_with_to_delete_row_number.
- The initial block of code creates a fresh instance of a sequence object named CountBy1_to_delete_row_number.
- The next code segment creates a fresh copy of the #Result_with_to_delete_row_number table. This table holds the original #Result rows with a new set of sequence numbers in a column named source_row_number. The next value for function populates the sequence numbers in the source_row_number column.
- The code segment concludes with a select statement that displays the rows of the #Result_with_to_delete_row_number table ordered by source_row_number.
-- create a fresh sequence object
-- and start processing of output from
-- the all nasdaq companies with beautifulsoup.bat file
begin try
drop sequence dbo.CountBy1_to_delete_row_number
end try
begin catch
print 'CountBy1_to_delete_row_number'
end catch
create sequence CountBy1_to_delete_row_number
start with 1
increment by 1;
begin try
drop table #Result_with_to_delete_row_number
end try
begin catch
print '#Result_with_to_delete_row_number'
end catch
-- return first processed set from output
select
next value for CountBy1_to_delete_row_number AS source_row_number
,line
into #Result_with_to_delete_row_number
from #Result
select * from #Result_with_to_delete_row_number order by source_row_number
The next screen shot shows the first 32 rows from the #Result_with_to_delete_row_number table. The only reason for showing the screen shot is to enable you to confirm that the sequence numbers preserve the original order of the rows from the #Result table.

The second processing step leverages the source_row_number values created in the first processing step to perform the objectives of the second processing step. This second processing step is implemented as a T-SQL script that is later re-used as a sub-query in the third processing step. The code in the second processing step selects a subset of the columns in the original HTML table, and the code groups the cell values by a surrogate value (TICKER_NUMBER) for ticker value. Additionally, the second processing step removes the first four rows and the last row from the #Result_with_to_delete_row_number table.
Here's the script for the second processing step. This code segment is available from either the first and second processing of web scraping results.sql or third processing of web scraping results.sql files for this tip.
- The declare statement populates the @max_source_row_number local variable with the maximum source_row_number value from the #Result_with_to_delete_row_number table. This local variable points at the last row in the table.
- After the declare statement, the second processing step consists of a sub-query inside of an outer query with an order by clause; the sub-query formulation is for easy inclusion in the third processing step.
- The where clause inside the subquery has three criteria expressions
- The first two criteria expressions are to exclude rows that do not correspond
to HTML table rows; the expressions achieve this goal by excluding
- the row with the source_row_number equal to @max_source_row_number
- the rows with source_row_number values from 1 through 4
- The third criteria expression selects six column identifiers for each
stock
- the columns are denoted by an index for position starting at the value 0 for the first column and ending in the value 6 for the last included column
- the position index value (row_number_within_ticker) is computed based on a modulo function (%) with a divisor of 14; this function returns the values of 0 through 6 for the first seven column values for a stock's first HTML table row; content from a stock's second HTML table row is purposely excluded by not programming any code to extract second-row content
- the fourth column from the original HTML table, with a position index value of 3, is not included in the columns for the SQL Server table; this column is for the ADR TSO value from the original HTML table that pertains to a small subset of rows in the overall HTML table
- The first two criteria expressions are to exclude rows that do not correspond
to HTML table rows; the expressions achieve this goal by excluding
-- return second processed set from output -- return ticker_number, row_number_within_ticker, company identifiers -- ticker symbol has row_number_within_ticker of 2 within ticker_number declare @max_source_row_number int = (select max(source_row_number) from #Result_with_to_delete_row_number) select * from ( select (source_row_number-5) / 14 TICKER_NUMBER ,((source_row_number-5) % 14) row_number_within_ticker ,line ticker_value from #Result_with_to_delete_row_number where source_row_number != @max_source_row_number and source_row_number not between 1 and 4 and ((source_row_number-5) % 14) in (0, 1, 2, 4, 5, 6) ) ticker_identifiers order by TICKER_NUMBER, row_number_within_ticker
Here's a screen shot with results for the first two stocks from the second processing step. You can compare these values to those from the preceding screen shot to confirm how the code operates.
- The first six rows are for the stock with a PIH ticker, and these rows all have a TICKER_NUMBER value of 0.
- The second six rows are for the stock with a TURN ticker, and these rows all have a TICKER_NUMBER value of 1.
- The TICKER_NUMBER value is the result of dividing one integer data type
value by a second integer data type value
- The first integer value to be divided has this expression (source_row_number-5) in the preceding script
- The second integer value is the number 14
- SQL Server data types return an integer data type value when one integer is divided by another integer; the returned value is the quotient truncated to a whole integer number

The third processing step performs two operations in two separate queries.
- The first query leverages the sub-query in the second step, and it also replaces the position index values denoting columns with actual column names.
- The second query pivots the output from the first query so that the result set shows as a non-normalized table with a separate row for each ticker value. On each row is the ticker and its matching identifiers, such as company name and market capitalization.
- The code segments for the third processing step are available from the third processing of web scraping results.sql file for this tip. This file also includes the code for the first two processing steps as well.
The following T-SQL code segment is for the re-mapping position index values (row_number_within_ticker) to column name values (ticker_ids).
- After declaring and populating the @max_source_row_number local variable, the segment starts by dropping the #pivotsource table if it already exists. This table is populated with the into keyword in the following query.
- The query populates three columns in its result set.
- The first column value is a number to denote the stock.
- The second column value is a string representing the name for column identifiers; these identifier names include the ticker and other column names associated with the stock, such as company name and market cap. The names for column identifiers are assigned based on the row_number_within_ticker value from a case…end statement defining the ticker_ids column in the query's select list.
- The third column value is the identifier value associated with the column name in the second column.
- The select statement at the end of the code segment displays the #pivotsource result set ordered by ticker_number and ticker_ids (for ticker identifiers).
declare @max_source_row_number int = (select max(source_row_number) from #Result_with_to_delete_row_number) begin try drop table #pivotsource end try begin catch print '#pivotsource' end catch -- pre-processing for third processing replaces -- column index number from second step to index name -- with column names in the third processing result set output select tickers.TICKER_NUMBER , case when row_number_within_ticker = 0 then 'COMPANY NAME' when row_number_within_ticker = 1 then 'TICKER' when row_number_within_ticker = 2 then 'MARKET CAP' when row_number_within_ticker = 4 then 'COUNTRY' when row_number_within_ticker = 5 then 'IPO YEAR' when row_number_within_ticker = 6 then 'INDUSTRY' end ticker_ids ,ticker_value into #pivotsource from ( -- ticker values for ticker_number values select (source_row_number-5) / 14 TICKER_NUMBER ,line TICKER from #Result_with_to_delete_row_number where source_row_number != @max_source_row_number and source_row_number not between 1 and 4 and ((source_row_number-5) % 14) = 1 ) tickers left join ( select (source_row_number-5) / 14 TICKER_NUMBER ,((source_row_number-5) % 14) row_number_within_ticker ,line ticker_value from #Result_with_to_delete_row_number where source_row_number != @max_source_row_number and source_row_number not between 1 and 4 and ((source_row_number-5) % 14) in (0, 1, 2, 4, 5, 6) ) ticker_identifiers on tickers.TICKER_NUMBER = ticker_identifiers.TICKER_NUMBER order by tickers.TICKER_NUMBER, row_number_within_ticker SELECT * FROM [#pivotsource] order by ticker_number, ticker_ids
An excerpt from the #pivotsource result set for the first two stocks appear in the following screen shot. There are several changes to these 12 rows from the output in the preceding screen shot showing second-step processing results.
- The most obvious change is the replacement of row_number_within_ticker values with column names in the ticker_ids column.
- Also, the order of identifier values is different in this result set from the preceding result set. This is because of the order by clause in the last select statement in the preceding code segment. After the row_number_within_ticker values were replaced by column names denoting an identifier, it was no longer necessary to preserve the order of rows returned by the Python script.

The code for pivoting the values in the #pivotsource result set appears next.
- The PIVOT keyword enables SQL Server to re-position the values in a result set so that values appear in a cross-tab format as opposed to a list format.
- The select list specifies the order of column values for the cross-tab table.
- The TICKER_NUMBER column from the list is re-named TICKER INDEX for the cross-tab display of data.
- Other columns have the same name in the list and cross-tab display of data.
- The PIVOT clause of the select query uses a MAX function for TICKER_VALUE
values followed by a FOR clause.
- The MAX function allows you to pivot rows without aggregation. For this pivot operation, it is not appropriate to aggregate the ticker_ids values, which are individual column values on each row in the pivoted result set.
- The FOR clause including the IN keyword specifies the order of column values in the cross-tab display of data.
-- pivoted third processing step output for
-- easier viewing of results
SELECT [TICKER_NUMBER] [TICKER INDEX], [TICKER], [COMPANY NAME], [MARKET CAP], [COUNTRY], [IPO YEAR], [INDUSTRY]
FROM [dbo].[#pivotsource]
PIVOT
(
MAX(TICKER_VALUE)
FOR [TICKER_IDS] IN ([TICKER], [COMPANY NAME], [MARKET CAP], [COUNTRY], [IPO YEAR], [INDUSTRY])
) AS P
ORDER BY TICKER_NUMBER
The following screen shot shows the first three rows from the pivoted result set. Notice that the ticker values match the first three rows in the first screen shot within this tip from the NASDAQ web site. In other words, the SQL Server table has a similar form and the same values as the original source HTML table!

General guidelines for downloading content from web pages to SQL Server
- Visually inspect with a browser the web page from which you want to scrape content.
- Programmatically inspect the web page's HTML content.
- For example, find identifiers for a table tag from which you want to download content.
- Web developers can display content in different ways, such as with different tags or different text to identify distinct types of content for the same tags.
- Your code for reading a web page from which you want to download data must conform to the HTML tags and other conventions which an HTML developer used to create a web page.
- Write a Python script to extract data from the source web page. Then, verify the extracted data match both the source page content as well as your data harvesting requirements. If you are going to use BeautifulSoup to facilitate extracting content embedded in a web page, make sure that it is installed along with Python on your SQL Server computer.
- After you confirm a Python script is extracting on a raw data basis the values which you seek, you can run the Python script from within SSMS. One way to do this is by invoking a Windows batch file that launches the Python script. The cmdshell xp_extended stored procedure enables this capability.
- Capture the output from the Python script into a staging table in SQL Server.
- Perform any final processing of the values in the staging table and store the converted, captured values within a SQL Server table.
Next Steps
- Install Python on your computer if it is not already installed. See this tip for detailed instructions on how to install Python in a Windows environment so that all users on a computer can run Python script files.
- If you are concerned about maintaining a very high level of security on your SQL Server instance, review another tip on how to securely configure SQL Server when running Python scripts with the xp_cmdshell extended stored procedure.
- Then, install any special libraries, such as BeautifulSoup, that you need to reference along with the built-in Python libraries.
- Next, download the files for this tip into a c:\python_programs directory on your computer for running SQL Server.
- Then, run the Python script for information about NASDAQ tickers from the NASDAQ web site. Confirm that your output from Python matches that from your browser when you use the same source web page.
- Run the T-SQL script for downloading selected columns from the NASDAQ HTML table of companies by industry to a SQL Server table. Confirm that your result set from the T-SQL script matches corresponding values from the NASDAQ HTML page.
- Try modifying the T-SQL code so that you omit a column for its result set. You can achieve this as simply as omitting the column from those that are pivoted. Alternatively, you can make the change earlier in the script. However, when you make the change at an earlier step, you may want (need) to modify all subsequent steps in a corresponding fashion.






About the author
 Rick Dobson is an author and an individual trader. He is also a SQL Server professional with decades of T-SQL experience that includes authoring books, running a national seminar practice, working for businesses on finance and healthcare development projects, and serving as a regular contributor to MSSQLTips.com. He has been growing his Python skills for more than the past half decade -- especially for data visualization and ETL tasks with JSON and CSV files. His most recent professional passions include financial time series data and analyses, AI models, and statistics. He believes the proper application of these skills can help traders and investors to make more profitable decisions.
Rick Dobson is an author and an individual trader. He is also a SQL Server professional with decades of T-SQL experience that includes authoring books, running a national seminar practice, working for businesses on finance and healthcare development projects, and serving as a regular contributor to MSSQLTips.com. He has been growing his Python skills for more than the past half decade -- especially for data visualization and ETL tasks with JSON and CSV files. His most recent professional passions include financial time series data and analyses, AI models, and statistics. He believes the proper application of these skills can help traders and investors to make more profitable decisions.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2017-11-06

