By: Koen Verbeeck | Updated: 2017-11-13 | Comments | Related: > Analysis Services Performance
Problem
I have a large Tabular model in Analysis Services Tabular 2017. Especially the fact table, it is very large, with a row count in the millions. Processing the table takes quite some time. How can I reduce the processing time?
Solution
With the release of SQL Server Analysis Services 2016, Tabular models have the ability to process multiple partitions in parallel. Partitions have been present in Tabular models since their release in SQL Server 2012, but they served a more administrative purpose. In SSAS 2012 and 2014, you can’t process multiple partitions of the same table in parallel. There is some overlap with how partitions work in Analysis Services Multidimensional, but also some differences. An overview:
- You can use partitions for incremental loading. If you have a partition for the most recent data, you can only process this partition to add more data to your table. This will also save considerable processing time, but it won’t help you if you do a Process Full on the entire table.
- Unlike in SSAS Multidimensional, partitions do not improve query performance in Tabular.
- SSAS Multidimensional can process partitions in parallel and has been key in improving processing performance for several versions.
By default, a table in SSAS Tabular consists of one single partition. Which means during processing, it’s possible only one single processor core will be used for certain parts of the model processing. This depends on which part of the processing cycle and the number of segments in the data. You can find an example of CPU usage in the whitepaper Performance Tuning of Tabular Models in SQL Server 2012 Analysis Services at page 103. In this example, only one core is used to read and encode the first 16 million rows of data.
Keep in mind that if you have multiple tables in your model, those will be processed in parallel, no matter the version of SSAS Tabular. Starting from SSAS 2016, partitions of a single table are processed in parallel as well.
In this tip, we’ll investigate how we can improve processing performance for one single table. The screenshots and guidelines for this tip are created using Visual Studio 2017, with a compatibility level of 1400 (for SSAS 2017). All of the concepts can be translated to SSAS 2016, although 2017 might use the M language to retrieve data (like in Power BI Desktop or Power Query) and 2016 will use plain T-SQL statements.
Example to Process SSAS Tabular Partitions in Parallel
We’re going to use the StackOverflow sample database, in specific the Posts table since it has a large number of rows (On my instance, I have removed some blob columns to save some space). After creating a blank SSAS Tabular 2017 project, we can add the table to the model using the new Get Data experience.
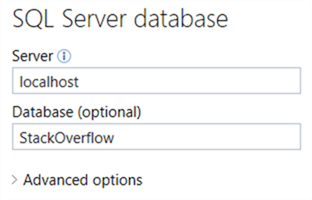
Enter the server and the database name:
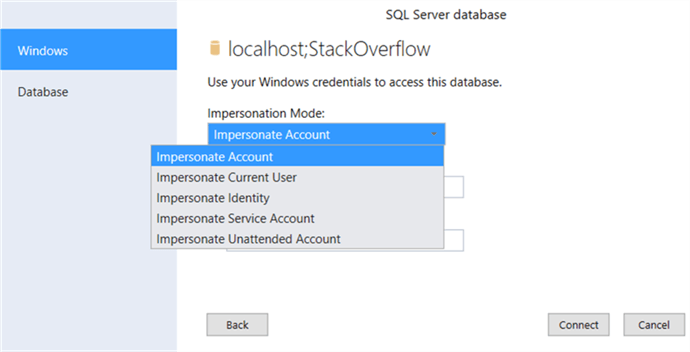
Specify credentials to read the data. Not all options are supported for processing the models. I ended up specifying a SQL login to read the data. You might get a warning about encryption support.
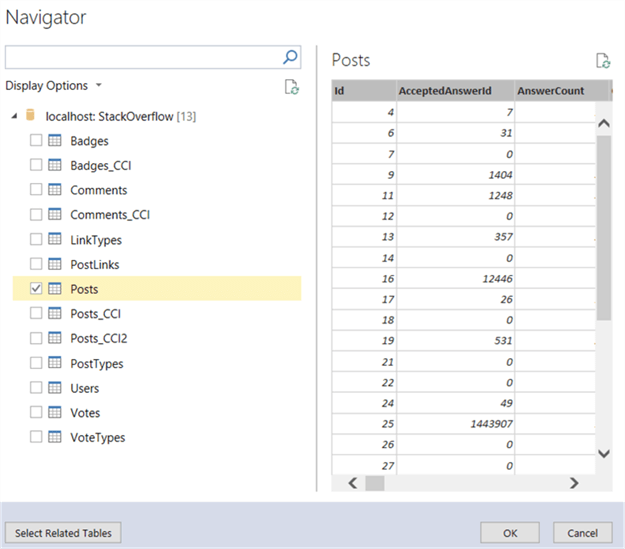
Select the Posts table from the list and click on OK (I have a couple of extra tables because I experimented with columnstore indexes).
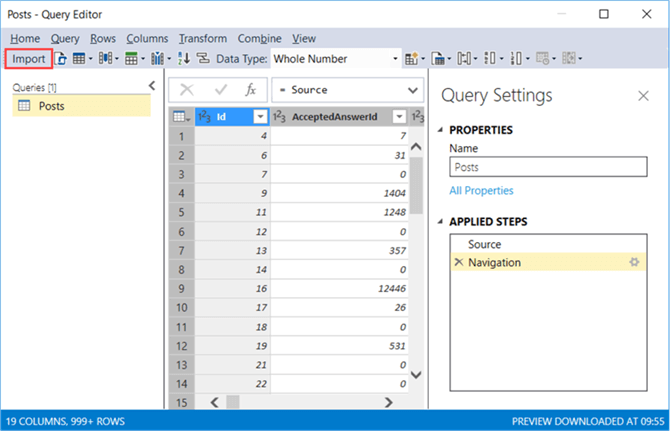
The query editor will open. We can leave everything as-is and click on Import to load the table to the model in Visual Studio, which can take quite some time.
Let’s test the processing performance by deploying the model to the server. With the following JSON command we can process the table:
{
"refresh": {
"type": "full",
"objects": [
{
"database": "ParallelPartitions",
"table": "Posts"
}
]
}
}
On my system, processing the table takes about 6 minutes 30 seconds.
Creating Partitions in a SSAS Tabular Model
We’re going to create partitions for the different years of the creation date in the Posts table.
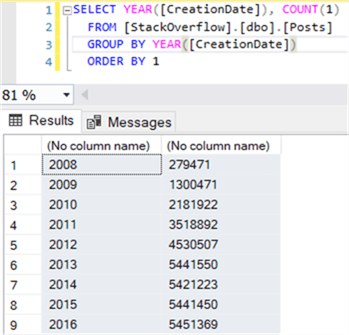
We’re going to create 5 partitions: one for each year between 2013 and 2016 and one for all the other years. Let’s start modifying the existing partition of the Posts table in the model. Click on the table and go to its properties. Click on the ellipsis for the source data.
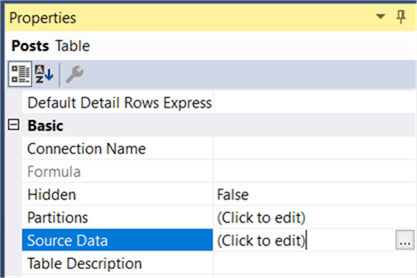
This will take you to the M statement that fetches the data for the Posts table. Click on Design… to go to the query editor. There we will take the following steps:
- Add a new column called Year which contains the year from the CreationDate column. The function Date.Year([CreationDate]) can be used.
- Filter the Year column for all values below or equal to 2012.
- Remove the Year column.
When you right-click on the last step in the Query Settings, you can choose View Native Query.
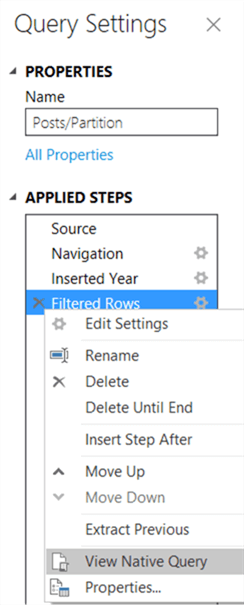
Here we can verify all the transformations are actually being folded back to the SQL Server database engine:

Import the data and close the table properties dialog. In the properties, now go to the Partition Manager.
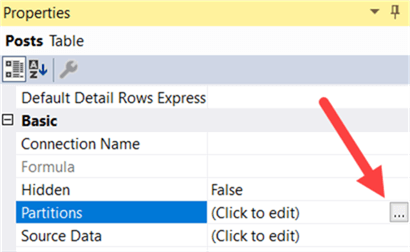
First we’re renaming the partition to Below2012. Then we’re going to copy the partition.
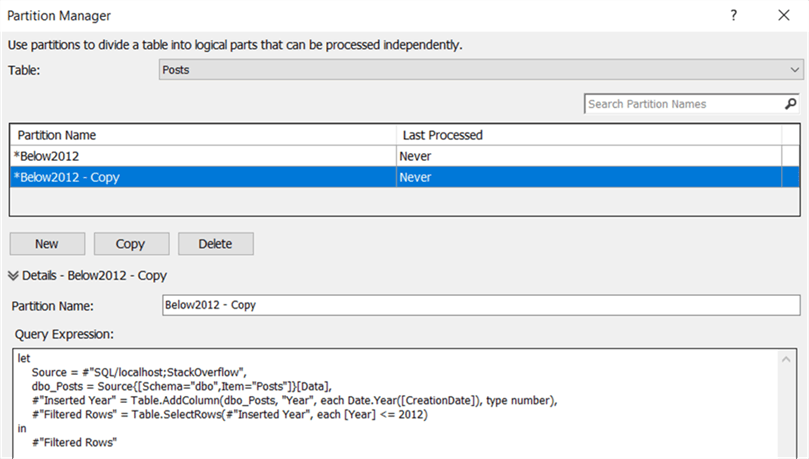
In this copy, we can simply change the M code so that it filters only the years 2013. Repeat this process for all other years.
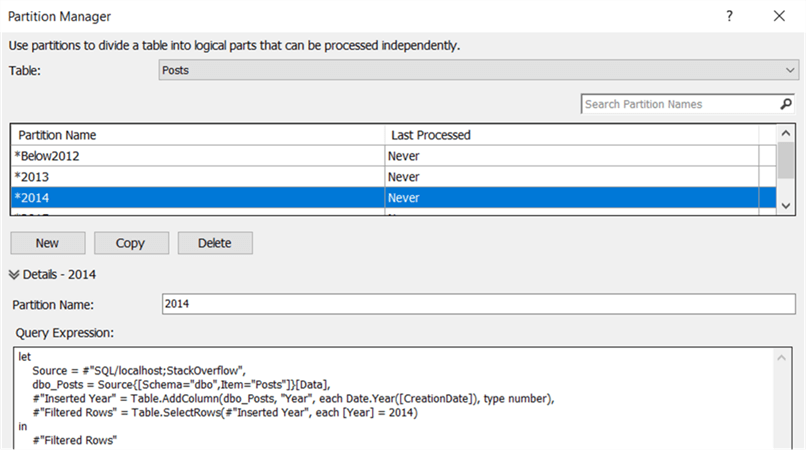
With all the partitions created, we can deploy the model back to the server.
Processing with Multiple Partitions with SQL Server Analysis Services Tabular
When processing the table, we can now see all the partitions are processed at the same time:
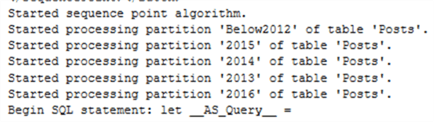
On my machine, processing now took 5 minutes 44 seconds, or an improvement of 12% for a Process Full of the entire table. The bottleneck is probably not in reading data from SQL Server, but rather in compressing the various segments and processing the various hierarchies. Of course, in your system and with your data, your mileage might vary. More improvement in processing performance can be achieved by processing a single partition, instead of the whole table.
A small side note: if re-encoding events happen during processing, parallel processing might increase system resource usage as multiple processing operations need to be interrupted and re-started. For more information about re-encoding events, check out the tip Improve Analysis Services Tabular 2017 Processing with Encoding Hints.
Conclusion
By creating partitions in SQL Server Analysis Services Tabular 2016 or later, we can reduce the duration of processing. Since SSAS 2016, partitions can be processed in parallel, while in earlier versions this was a serial process.
Next Steps
- You can find a zipped version of the project file used in this tip here. The connection points to a local instance of the StackOverflow database. The deployment server and local workspace server are both set to localhost.
- If you are interested in knowing more about encoding and the internals of processing a Tabular model, you can check out the Performance Tuning of Tabular Models in SQL Server 2012 Analysis Services whitepaper. It’s about the first version of SSAS Tabular, but a lot of the internals are still the same.
- You can find more Analysis Services tips in this overview.






About the author
 Koen Verbeeck is a seasoned business intelligence consultant at AE. He has over a decade of experience with the Microsoft Data Platform in numerous industries. He holds several certifications and is a prolific writer contributing content about SSIS, ADF, SSAS, SSRS, MDS, Power BI, Snowflake and Azure services. He has spoken at PASS, SQLBits, dataMinds Connect and delivers webinars on MSSQLTips.com. Koen has been awarded the Microsoft MVP data platform award for many years.
Koen Verbeeck is a seasoned business intelligence consultant at AE. He has over a decade of experience with the Microsoft Data Platform in numerous industries. He holds several certifications and is a prolific writer contributing content about SSIS, ADF, SSAS, SSRS, MDS, Power BI, Snowflake and Azure services. He has spoken at PASS, SQLBits, dataMinds Connect and delivers webinars on MSSQLTips.com. Koen has been awarded the Microsoft MVP data platform award for many years.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2017-11-13
