By: Tim Smith | Updated: 2018-02-27 | Comments | Related: > TSQL
Problem
A significant portion of our analysis involves looking at specific ranges of data and extracting meaningful information about those ranges. We need to be able to summarize these ranges so that we either identify if these are the ranges we need to uncover, or if we can apply further analysis on these ranges. Using T-SQL, what are some ways that we can quickly identify data ranges that may be meaningful to further investigate? In addition, as we do this, are there any considerations we should keep in mind regarding future data sets, as our data continues to grow and we'd like to scale our analysis of our data early in our design?
Solution
In this tip, we’ll be looking at obtaining details on the data spread by meaningful percentiles. We’ll look at an example using a standard percentile range and provide analysis for how we would determine what percentile may warrant a further investigation. Depending on what we’re trying to find, we may find a percentile of data with no spread as meaningful as data with a broad spread.
We’ll begin by creating a table in SQL Server and populating some data using T-SQL for our example. In the below code, we’re using SQL Server 2016, though this code is compatible with most versions of SQL Server except the clustered columnstore index (which is available in 2014 and beyond). If you’re running this test in an earlier version of SQL Server than 2014, you can replace the clustered columnstore index with a nonclustered index. I am using the clustered columnstore index here since I will be applying a query to the entire table, like we would see in data warehouse queries. This is one strength of clustered columnstore indexes.
CREATE TABLE tbLnAnalysis( Id SMALLINT IDENTITY(1,1) , NumberField INT ) CREATE CLUSTERED COLUMNSTORE INDEX CCI_tbLnAnalysis ON tbLnAnalysis ---- Execute in separate batches: highlight first INSERT INTO tbLnAnalysis (NumberField) VALUES (0) GO 6328 ---- Execute in separate batches: highlight first INSERT INTO tbLnAnalysis (NumberField) VALUES (5000) GO 1431 ---- Execute in separate batches: highlight first INSERT INTO tbLnAnalysis (NumberField) VALUES (10000) GO 1100 ---- Execute in separate batches: highlight first INSERT INTO tbLnAnalysis (NumberField) VALUES (15000) GO 854 ---- Execute in separate batches: highlight first INSERT INTO tbLnAnalysis (NumberField) VALUES (20000) GO 675 ---- Execute in separate batches: highlight first INSERT INTO tbLnAnalysis (NumberField) VALUES (25000) GO 232 ---- Execute in separate batches: highlight first INSERT INTO tbLnAnalysis (NumberField) VALUES (50000) GO 89 ---- Execute in separate batches: highlight first INSERT INTO tbLnAnalysis (NumberField) VALUES (50000) GO 89 ---- Execute in separate batches: highlight first INSERT INTO tbLnAnalysis (NumberField) VALUES (100000) GO 21 ---- Execute in separate batches: highlight first INSERT INTO tbLnAnalysis (NumberField) VALUES (250000) GO 4 SELECT * FROM tbLnAnalysis
On the GO number batches, make sure to execute these in separate batches by highlighting each batch and executing them (as noted).
Now that we’ve created a table and populated data, we want to delineate our data into percentiles. We’ll be using the T-SQL NTILE function, which will allow us to break data into as many percentiles as we’d like. In this case, we’ll partition our data into 20 parts using NTILE, which is the T-SQL version of looking at ever 5% category (100 divided by 20 equals 5). The result:
SELECT NTILE(20) OVER (ORDER BY NumberField) TwentiethPercentile , NumberField FROM tbLnAnalysis
By contrast, if we wanted to look at every 10%, we would use 10 in the NTILE function (100 divided by 10 equals 10). For an example and the results:
SELECT NTILE(10) OVER (ORDER BY NumberField) TenthPercentile , NumberField FROM tbLnAnalysis
Returning to looking at every 5%, we want to find the spread of each of these sets of data so that we can identify which ranges of these data may be meaningful to our analysis. In this example, we won’t find that the ranges with no spread are meaningful, however, in some situations these may be more meaningful than ranges of data with a broad spread. To make our code cleaner, we’ll wrap the percentiles into a common table expression and break down the analysis further.
The reason we use a common table expression here is only to make it quick to query the data on the inside of the common table expression. We will group by the percentile and look at some aggregate functions, such as the minimum, maximum, average, variance and standard deviation of these percentiles. These aggregates return these values that apply to these specific ranges of percentiles. The result:
;WITH Twenties AS( SELECT NTILE(20) OVER (ORDER BY NumberField) FifthPercentiles , NumberField FROM tbLnAnalysis ) SELECT FifthPercentiles , MIN(NumberField) MinVal , MAX(NumberField) MaxVal , AVG(NumberField) AvgVal , VAR(NumberField) VarVal , STDEV(NumberField) StDevVal FROM Twenties GROUP BY FifthPercentiles
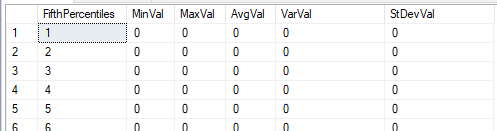
Since we’re using a test data set that we created, we may know what we want to look at immediately from the above data. In situations where we may not know what, let’s consider the following:
- In some situations, we may want to see data ranges with little to no spread, or we may want to see data ranges with broad spread. The standard deviation helps us identify this and we can add a difference between the minimum and maximum (added later) to compare the maximum and minimum values to suit our needs. By adding this column along with the standard deviation, we’ll be able to quickly identify which range of data we want (it may be multiple ranges).
- If I’m defining an outlier by a multiple of the standard deviation, such as using an example of 2 multiples in this example, we can add another column (added later) which aggregates the average with the multiples of the standard deviation to identify the maximum range would be an outlier for this range of data. We may take this analysis further by adding a CASE WHEN statement that results in a YES if the maximum value exceeds our definition of an outlier for our data set. Remember that we may define an outlier with a different multiple of the standard deviation, so while this example uses 2, we may use a higher multiple.
- If we look at many data sets where we can apply this, consider our data in schema templates that we can reuse on other data sets. The reason for this is that if I design an algorithm that looks at a schema, such as a schema with average, difference between maximum and minimum, standard deviation, outliers, etc, I can reuse this algorithm on other data sets provided that I use the same schema. This allows me to create algorithms through functions that use a schema that I can reuse, which saves me further time in the future and allows for automation.
- Finally, we want to pre-solve as much of the next-steps with our data as possible. What will we do with the data ranges that we find next? Can we add any meaningful information to the result so that our next-steps will be complete, or close to complete? Since we’re already applying aggregates to these percentiles, by adding our next-steps to our queries that may be solvable here, we can reduce the performance impact and save time.
These do not cover every situation that you may need, but they provide helpful starting points about thinking further regarding your data and what may help you in your next step of analysis.
;WITH Twenties AS( SELECT NTILE(20) OVER (ORDER BY NumberField) FifthPercentiles , NumberField FROM tbLnAnalysis ) SELECT FifthPercentiles , MIN(NumberField) MinVal , MAX(NumberField) MaxVal , AVG(NumberField) AvgVal , VAR(NumberField) VarVal , STDEV(NumberField) StDevVal , (MAX(NumberField)-MIN(NumberField)) MaxMinDiff ---- Added column , (AVG(NumberField)+(2*STDEV(NumberField))) AnyOutlier --- Added column , CASE WHEN MAX(NumberField) > (AVG(NumberField)+(2*STDEV(NumberField))) THEN 'YES' ELSE 'NO' END AS OutlierAssessment FROM Twenties GROUP BY FifthPercentiles

Next Steps
- If we design a schema for reuse in the final query, we'll be able to apply the above schema for different algorithms that assess the values, even if we change some of the numbers in our final query - such as using a different multiple for standard deviation, or using the absolute value when looking at the difference. Since we may data sets where we want more analysis, I prefer to use a large schema set which covers everything I need when looking at new data, as I can apply existing automation to it. By contrast, if I used a smaller schema with less analysis, I would need to create exceptional functions for these exceptions. Since you mentioned scale, consider the re-use gives us a scaling advantage. When it doubt, provide more from the final query than less for reuse.
- The NTILE function in T-SQL allows us to look at other percentiles, if we wanted to get the range. In this tip, we looked at every 5th and every 10th, but we could break this further depending on our needs.






About the author
 Tim Smith works as a DBA and developer and also teaches Automating ETL on Udemy.
Tim Smith works as a DBA and developer and also teaches Automating ETL on Udemy.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2018-02-27
