By: Edwin Sarmiento | Updated: 2018-05-01 | Comments (3) | Related: 1 | 2 | 3 | 4 | 5 | > Availability Groups
Problem
In a previous tip on Installing SQL Server vNext CTP1 on Red Hat Linux 7.2, we have read about how we can now install SQL Server 2017 on a Linux operating system. We would like to evaluate running SQL Server 2017 Availability Groups on Linux. How do we go about building the Linux environment for SQL Server 2017 Availability Groups?
Solution
To continue this series on Step-by-step Installation and Configuration of SQL Server 2017 Availability Groups on a Linux Cluster, we will look at adding the SQL Server 2017 Always On Availability Group as a resource in the cluster. In Part 4, you have learned how to install and configure Pacemaker on Linux. This tip will walk you through the process of creating and configuring the SQL Server Always On Availability Group with the corresponding listener name as cluster resources.
Creating the SQL Server Always On Availability Group Resources on Pacemaker
Similar to creating a SQL Server Always On Availability Group on a Windows Server Failover Cluster (WSFC), a cluster resource is created. This allows the WSFC to control and manage the Availability Group for automatic failover, health detection and failure detection. The way the WSFC does this is thru the Always On Availability Group cluster resource DLL – hadrres.dll. The cluster resource DLL is the interface between the WSFC and SQL Server. While the WSFC detects health and failure and initiates automatic failover, it does so thru the cluster resource DLL.
The concept is similar with Pacemaker. The cluster resource agent that you installed in Part 2 - mssql-server-ha – is the interface between Pacemaker and SQL Server. It tells Pacemaker about the status and health of the resource – in this case, the SQL Server Always On Availability Group – so the cluster can decide how to deal with it to maintain high availability.
When you create a SQL Server Always On Availability Group on a WSFC, a cluster resource is automatically created for you. This is done thru the tight integration between SQL Server and the WSFC. Not so with Pacemaker. It is your responsibility as the administrator to manually create the cluster resources.
Here’s a high-level overview of the steps for your reference.
- Create the Always On Availability Group resource on Pacemaker
- Create the virtual IP address resource for the Always On Availability Group listener
- Configure the Always On Availability Group resource to run on the same machine as the virtual IP address resource
- Configure the order in which the cluster resources should start/stop
Step #1: Create the Always On Availability Group Resource on Pacemaker
NOTE: Perform this step on ANY of the Linux servers. You don’t need to run it on all nodes. Remember to log in with super user (root) privileges when performing these steps. This example uses linuxha-sqlag1 to run the command.
Creating the Always On Availability Group resource on Pacemaker requires configuring it as a type called clone. Cloned resources were initially intended for allowing multiple instances of a virtual IP address resource to run on several or all cluster nodes at the same time for load balancing. The Always On Availability Group resource is considered to be an anonymous cloned resource where the Availability Group configuration exists on all of the cluster nodes running the SQL Server instances acting as replicas. The resource behaves exactly the same everywhere it is running. But since you can only have one primary replica, there can only be one copy of the cloned resource active per cluster node.
Cloned resources are allowed to be in one of two operating modes (also called roles) – master or slave. The master role is the one controlling the state of the slave roles. In an Always On Availability Group, the master role is assigned to the node running the primary replica while the slave roles are assigned to the nodes running secondary replicas. During a failover, the slave roles can be promoted to master, much like how a secondary replica can take over the role of the primary replica.
Run the command below to create the Always On Availability Group resource on Pacemaker.
sudo pcs resource create LINUX_SQLAG ocf:mssql:ag ag_name=LINUX_SQLAG master notify=true
The following parameters are used
- LINUX_SQLAG: the name of the Pacemaker cluster resource; does not need to be the same as the name of the Always On Availability Group
- ocf:mssql:ag: the name of the Open Cluster Framework (OCF) resource agent, provided by mssql-server-ha
- ag_name=LINUX_SQLAG: the name of the Always On Availability Group as defined in Part 3
- master: defines the resource as a master/slave cloned resource
- notify=true: tells all cloned resource before stopping or starting a copy of the clone and after the action was completed successfully

Step #2: Create the virtual IP address resource for the Always On Availability Group listener
NOTE: Perform this step on ANY of the Linux servers. You don’t need to run it on all nodes. Remember to log in with super user (root) privileges when performing these steps. This example uses linuxha-sqlag1 to run the command.
Unlike in a WSFC, there is no equivalent of a virtual network name resource in Pacemaker. In order to connect to the Always On Availability Group via the listener name, it has to be manually created in the DNS as has already been done in Part 1. You, then, need to create the corresponding virtual IP address resource on Pacemaker.
Run the command below to create the virtual IP address resource for the Always On Availability Group listener.
sudo pcs resource create AGListener_VIP ocf:heartbeat:IPaddr2 ip=10.10.10.58 cidr_netmask=24
The following parameters are used
- AGListener_VIP: the name of the virtual IP address resource; does not need to be the same as the Always On Availability Group listener name
- ocf:heartbeat:IPaddr2: the name of the Open Cluster Framework (OCF) resource agent that manages virtual IPv4 addresses
- ip=10.10.10.58: the virtual IP address of the Always On Availability Group listener name as defined in Part 3
- cidr_netmask=24: the subnet mask of the Always On Availability Group listener name as defined in Part 3

Step #3: Configure the Always On Availability Group resource to run on the same machine as the virtual IP address resource
NOTE: Perform this step on ANY of the Linux servers. You don’t need to run it on all nodes. Remember to log in with super user (root) privileges when performing these steps. This example uses linuxha-sqlag1 to run the command.
Since the Always On Availability Group listener name can only redirect client applications to the primary replica, the Availability Group and the listener name both have to be running in the same cluster node all the time. You cannot have the primary replica running on one node while the listener name on another. In a WSFC, this is made possible thru the concept of a cluster resource group.
Pacemaker also has the concept of cluster resource groups, where a set of resources that need to be located together, start sequentially, and stop in the reverse order in the same cluster node. However, since the Always On Availability Group resource is configured as a master/slave cloned resource, it cannot be added to a Pacemaker cluster resource group. In order to achieve the same behavior as cluster resource groups, the concept of a colocation constraint is used.
A colocation constraint tells the cluster that the location of one resource depends on the location of another. But in order to do so, it has to take into account the preferences of the main resource. For example, if resource A depends on resource B, the cluster needs to know the configuration of resource B when deciding where to place resource A.
Decisions in a Pacemaker cluster are made based on calculated scores per resource and node. Any node with a negative score for a resource cannot run that resource. The cluster will run a resource on a node with the highest score. You can configure how the cluster makes decisions with the use of constraints. When defining resource constraints, you specify a score for each constraint. The score indicates the value you are assigning to this resource constraint. Pacemaker implements INFINITY (or equivalently, +INFINITY) internally as a score of 1,000,000. Addition and subtraction with it follow these three basic rules:
- Any value + INFINITY = INFINITY
- Any value - INFINITY = -INFINITY
- INFINITY - INFINITY = -INFINITY
Run the command below to add colocation constraint to make sure that the Always On Availability Group resource run on the same machine as the virtual IP address resource.
sudo pcs constraint colocation add AGListener_VIP LINUX_SQLAG-master INFINITY with-rsc-role=Master
The following parameters are used
- AGListener_VIP: the name of the virtual IP address resource
- LINUX_SQLAG-master: the name of the Always On Availability Group resource acting as the master clone
- INFINITY: the score assigned to the resource constraint; this means that the constraint is REQUIRED
- with-rsc-role=Master: an additional attribute of the constraint; this means that this constraint is associated with the master clone (or the Always On Availability Group primary replica)

Step #4: Configure the order in which the cluster resources should start/stop
NOTE: Perform this step on ANY of the Linux servers. You don’t need to run it on all nodes. Remember to log in with super user (root) privileges when performing these steps. This example uses linuxha-sqlag1 to run the command.
In a WSFC, the concept of cluster resource dependencies exists to make sure that a resource will only come online if the dependent resource is already online. Think of the SQL Server Agent service. Because it is dependent on the SQL Server database engine service, it has to wait until the SQL Server database engine service is fully started before it can start. In the same way, the WSFC has to bring the Always On Availability Group listener name online before the Availability Group can be brought online.
Cluster resource dependencies can be achieved using cluster resource groups in Pacemaker. But because the Always On Availability Group resource cannot be added to a Pacemaker cluster resource group, the way to achieve cluster resource dependencies is by using an ordering constraint. An ordering constraint is simply a way to tell the cluster the order in which resources should start or stop.
Run the command below to configure the order in which the cluster resources should start/stop.
sudo pcs constraint order promote LINUX_SQLAG-master then start AGListener_VIP
The following parameters are used
- promote: the action for this constraint; promote the resource from a slave resource to a master resource
- LINUX_SQLAG-master: the name of the Always On Availability Group resource acting as the master clone
- start: the action for the constraint after the preliminary action has completed
- AGListener_VIP: the name of the virtual IP address resource

The sequence of events is not quite the same as that of how a WSFC starts the Always On Availability Group when automatic failover is initiated. In a WSFC, the sequence of events is as follows:
- Stop Availability Group on current primary replica
- Stop listener name on current primary replica
- Start listener on new primary replica
- Start Availability Group on new primary replica
That’s because the colocation constraint has an implicit ordering constraint. The default sequence of events when a colocation constraint is defined on the listener name is as follows:
- Stop the virtual IP address resource on current primary replica
- Stop Availability Group on current primary replica
- Start the virtual IP address resource on new primary replica
- Start Availability Group on new primary replica
This default sequence of events can potentially lead to client applications getting redirected to the old secondary replica even before it becomes the new primary replica. That’s because there is a possibility that the listener name is brought online (step #3) even before the Always On Availability Group is fully brought offline and the secondary replica promoted to primary replica(step #2). The ordering constraint prevents that from happening. However, it also increases the recovery time objective as client applications won’t be able to connect to the databases in the Always On Availability Group until the virtual IP address resource is brought online.
Verifying Always On Availability Group Configuration
Once everything has been configured, you can verify that the Always On Availability Group is working. A simple way to verify the configuration is to run the command below.
sudo pcs status
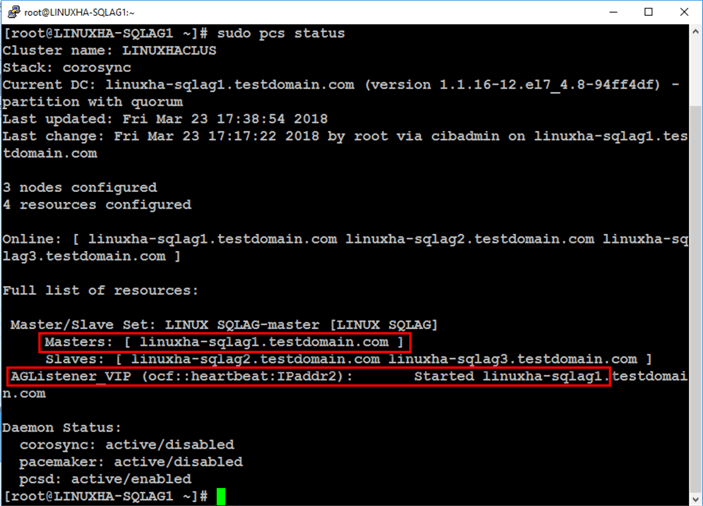
Notice that the master clone resource – LINUX_SQLAG-master – is running on linuxha-sqlag1. The virtual IP address resource – AGListener_VIP – is started and also running on linuxha-sqlag1.
Next, test connectivity to the Availability Group listener name using a simple PING test.
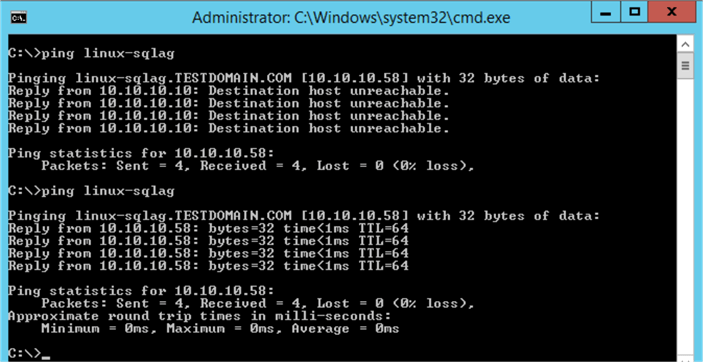
Before the virtual IP address resource was added to the cluster, there was no response when a PING test was run against the Availability Group listener name. After the virtual IP address resource was added to the cluster and started successfully, you should see a result on the IP address.
After performing a simple network test, connect to the Always On Availability Group via the listener name using SQL Server Management Studio. Use the query below to check the instance name of the primary replica and some of the properties of the Availability Group.
SELECT @@SERVERNAME as replica_name, @@VERSION, host_platform, host_distribution, host_release FROM sys.dm_os_host_info GO SELECT a.name as AG_Name, a.cluster_type_desc, b.dns_name, c.ip_address, c.ip_subnet_mask FROM sys.availability_groups a INNER JOIN sys.availability_group_listeners b ON a.group_id=b.group_id INNER JOIN sys.availability_group_listener_ip_addresses c ON b.listener_id=c.listener_id
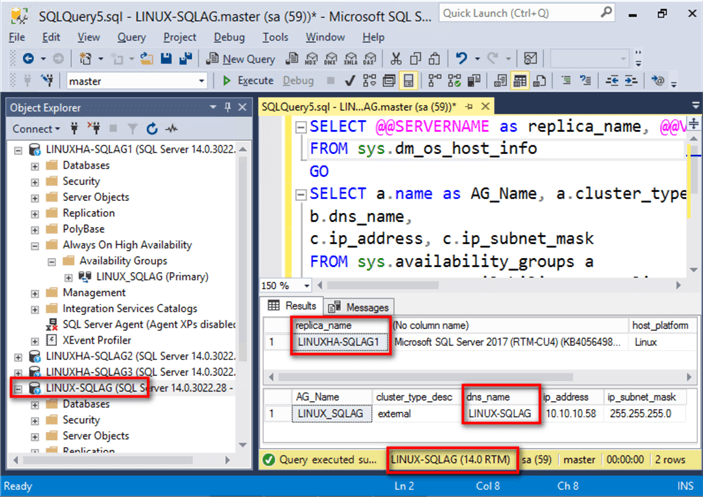
NOTE: Once you’ve added the Always On Availability Group as a cluster resource on Pacemaker, you can no longer use ALTER AVAILABILITY GROUP command nor SQL Server Management Studio to initiate manual failover. The proper way to initiate a manual failover is thru the use of the pcs resource move command.
Testing Automatic Failover
An easy way to test automatic failover is to shut down the node that is currently running the primary replica. Run the command below to initiate an immediate shutdown.
sudo shutdown now

If you are running a continuous PING test, you will temporarily get a request timed out response until the Always On Availability Group has been automatically failed over.
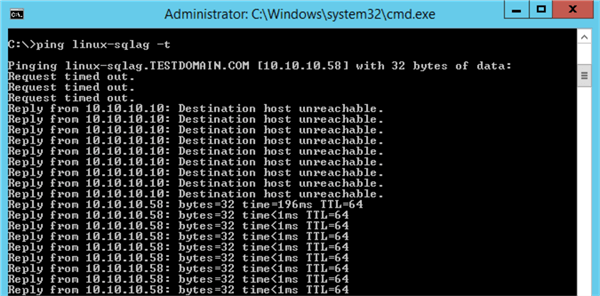
Once you get a response from the PING test, you can re-run the same query above to verify the new primary replica.
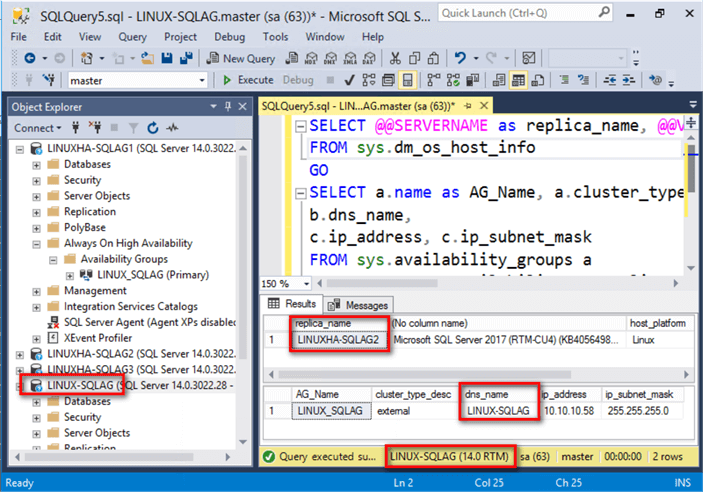
You can re-run the command below to check the status of the cluster and the resources.
sudo pcs status
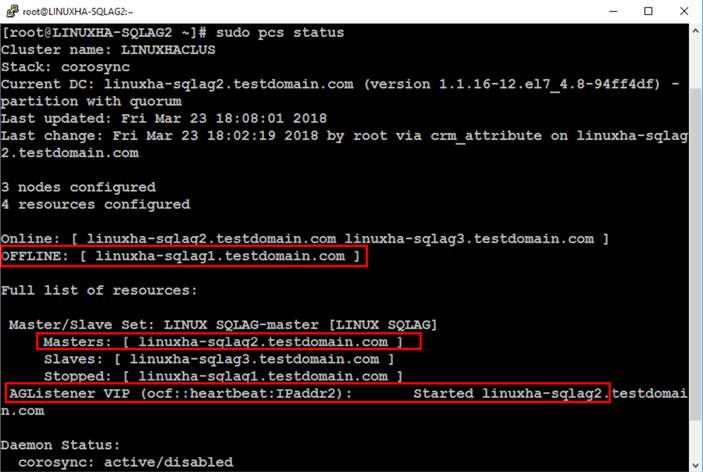
Notice that because the original primary – linuxha-sqlag1 – was shut down, the cluster automatically moved the resources to linuxha-sqlag2. This is a simple test to verify that automatic failover works.
Implementing a SQL Server Always On Availability Group on a Linux cluster requires proper planning and thorough documentation. Use this tip series as a guide to help you successfully provide high availability to your SQL Server databases using Always On Availability Groups on Linux.
Next Steps
- Review the previous four parts of this tip series:
- Review these previous tips on SQL Server on Linux
- Using ssh to connect to Linux for the SQL Server DBA
- Configure SQL Server on Linux
- Top 10 Linux Commands for SQL Server DBAs
- SQL Server on Linux Tips
- Read more on the following topics






About the author
 Edwin M Sarmiento is a Microsoft SQL Server MVP and Microsoft Certified Master from Ottawa, Canada specializing in high availability, disaster recovery and system infrastructures.
Edwin M Sarmiento is a Microsoft SQL Server MVP and Microsoft Certified Master from Ottawa, Canada specializing in high availability, disaster recovery and system infrastructures.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2018-05-01
