By: Ahmad Yaseen | Updated: 2018-04-27 | Comments (1) | Related: > Functions User Defined UDF
Problem
In SQL Server, Computed Columns and User Defined Scalar Functions don't always get along nicely. Most database developers complain about the performance of Computed Columns that use a Scalar Function to determine its value. In this tip, we will investigate the secret behind this bad relationship.
Solution
Before discussing our main issue in the tip, let's have an overview of Computed Columns and the Scalar Function concepts.
SQL Server Computed Column Overview
A Computed Column is a special type of columns with its values calculated using an expression that includes constant values, functions, data from other columns in the same table, or a combination of these components connected by one or more operators.
The Computed Column is a virtual column, with its value calculated, and not inserted directly by the user. Each time the column is referenced in the query and stored in memory without being stored physically in the table, unless the column is defined as a PERSISTED column. The Computed Column makes the life of the developers easier by providing the calculation logic at the database layer, rather than calculating it at the application layer.
To define a Computed column as PERSISTED, it should be deterministic, which means that the expression used to calculate the Computed Column values should return the same result any time it is called with a specific set of input values under the same database state. If the Computed Column is defined as PERSISTED, the column values will be updated automatically when any column that participates in the Computed Column expression is changed, reducing the overhead of calculating the Computed column values at runtime. In addition, defining the Computed column as PERSISTED enables creating an index on that column, to speed up the queries that access the computed column.
User Defined Scalar Function Overview
A SQL Server User Defined Function is encapsulated T-SQL commands that accept parameters, performs some sort of action or calculation, and returns the result of that action as a value, hiding the logic complexity from the application layer and making it reusable.
SQL Server provides us with two types of user defined functions; Table-valued function, also known as TVF, that returns the result in the form of a table and can be used in the FROM clause of the query, and a Scalar-valued function that returns a single data value of the type defined in a RETURNS clause.
In addition to the result shape, the two user defined function types differ from each other in the way they are handled internally by the query optimizer. The Scalar-valued function will be executed once for each row in the result set, where SQL Server will call the Table-valued function once regardless of the number of rows to be processed.
Computed Column with Scalar Function
A common design mistake is to encapsulate the calculation logic of the Computed Column using a user-defined Scalar function, as it will prevent the queries that are submitted on that table from taking benefits of the parallelism feature regardless of the Maximum Degree of Parallelism value being set to 0 or a value larger than 1 and the query cost exceeding the Cost Threshold for Parallelism configured value.
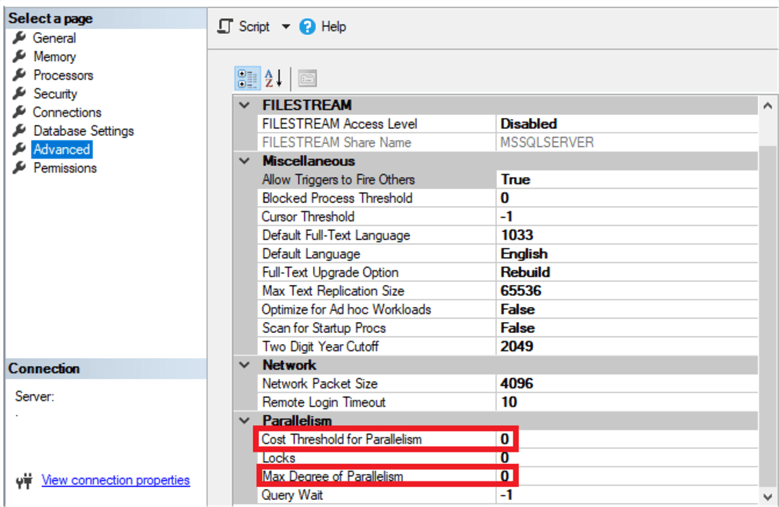
Assume that we have configured the SQL Server instance with the Max Degree of Parallelism value equal to 0, that allows the SQL Server Engine to use all available processors to process queries and the Cost Threshold for Parallelism value to 0, to allow executing all queries using a parallel execution plan, as shown in the snapshot below, taken from the Advanced tab of the Server Properties window:
To start with our demo, we will create a User Defined Scalar function, that takes the monthly income of the employee and calculates the yearly income for that employee including the basic salary and the bonus, using the CREATE FUNCTION T-SQL statement below:
USE MSSQLTipsDemo GO CREATE FUNCTION dbo.UDF_YearlyIncome(@MonthlyIncome INT) RETURNS INT AS BEGIN RETURN 14.15* @MonthlyIncome END GO
The testing scenario will be as follows; we will create two tables with Computed Columns to view the yearly income of the employee. The yearly income in the Computed Column of the first table will be calculated using a direct expression provided in the CREATE TABLE T-SQL statement. In addition, a non-clustered index will be created on that Computed Column to speed up the search based on that column, as shown below:
CREATE TABLE Employees_NoFunction ( ID INT IDENTITY (1,1) PRIMARY KEY, Employee_Name VARCHAR(50), EmployeeAddress VARCHAR (MAX), EmployeeSalary INT, YearlyIncome AS 14.15*EmployeeSalary ) GO CREATE NONCLUSTERED INDEX IX_Employees_NoFunction_YearlyIncome ON Employees_NoFunction (YearlyIncome) GO
In the second table, the Computed column will calculate the yearly income by passing the EmployeeSalary value to the previously created Scalar function in the CREATE TABLE T-SQL statement. If you execute the below CREATE TABLE statement that defines the Computed column as PERSISTED:
CREATE TABLE Employees_WithFunction ( ID INT IDENTITY (1,1) PRIMARY KEY, Employee_Name VARCHAR(50), EmployeeAddress VARCHAR (MAX), EmployeeSalary INT, YearlyIncome AS DBO.UDF_YearlyIncome(EmployeeSalary) PERSISTED )
The statement will fail, showing that we cannot define the Computed column as PERSISTED because this column is non-deterministic as shown in the error message below:

The previous function that is used to calculate the Computed column values is deterministic, as it will always return the same value when called with the same input, but SQL Server does not know that. Let's remove the PERSISTED word from the computed column definition in the previous CREATE TABLE T-SQL statement, as shown below:
CREATE TABLE Employees_WithFunction ( ID INT IDENTITY (1,1) PRIMARY KEY, Employee_Name VARCHAR(50), EmployeeAddress VARCHAR (MAX), EmployeeSalary INT, YearlyIncome AS DBO.UDF_YearlyIncome(EmployeeSalary) ) GO
Let's now try to create a non-clustered index on the Computed column, using the CREATE INDEX T-SQL statement below:
CREATE NONCLUSTERED INDEX IX_Employees_WithFunction_YearlyIncome ON Employees_WithFunction (YearlyIncome) GO
The statement will fail, showing that the Computed column is non-deterministic and cannot be used in the index key, as shown in the error message below:

The below INSERT INTO T-SQL statements can be used to fill the two tables, Employees_NoFunction and Employees_WithFunction, with the same 400K records, taking into consideration that the number beside the GO statement specifies the number of times the statement will be executed, as shown below:
INSERT INTO Employees_NoFunction VALUES ('Kenth', 'USA - Seattle' , 5400)
GO 100000
INSERT INTO Employees_NoFunction VALUES ('Jack', 'USA - Washington' , 6200)
GO 100000
INSERT INTO Employees_NoFunction VALUES ('John', 'Jordan - Amman' , 7100)
GO 100000
INSERT INTO Employees_NoFunction VALUES ('Frank', 'Jordan - Zarqa' , 4900)
GO 100000
INSERT INTO Employees_WithFunction VALUES ('Kenth', 'USA - Seattle' , 5400)
GO 100000
INSERT INTO Employees_WithFunction VALUES ('Jack', 'USA - Washington' , 6200)
GO 100000
INSERT INTO Employees_WithFunction VALUES ('John', 'Jordan - Amman' , 7100)
GO 100000
INSERT INTO Employees_WithFunction VALUES ('Frank', 'Jordan - Zarqa' , 4900)
GO 100000
The two tables are ready now for our testing. We will execute the below two SELECT statements, after enabling the TIME and IO statistics and enabling the actual execution plan:
SET STATISTICS IO ON SET STATISTICS TIME ON SELECT Employee_Name FROM Employees_NoFunction WHERE (YearlyIncome >1500 OR EmployeeSalary >450) AND EmployeeAddress LIKE '%SEAT%' GO SELECT Employee_Name FROM Employees_WithFunction WHERE (YearlyIncome >1500 OR EmployeeSalary >450) AND EmployeeAddress LIKE '%SEAT%'
You will see from the generated statistics that querying the first table that has a Computed column calculated without using a Scalar function is faster, and consumes less CPU time, than querying the second table that has a Computed Column calculated using a Scalar function, as shown below:

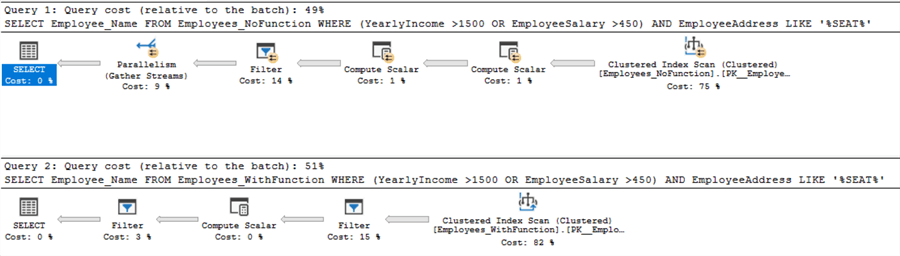
Checking the execution plans generated from the previous SELECT statements, you will see that the first SELECT query, that does not use the Scalar function, is faster due to using a parallel execution plan. On the other hand, using the Scalar function to calculate the Computed Column values in the second table, prevents the query from using a parallel execution plan, and uses a serial execution plan, as shown in the execution plans below:
Next Steps
- Check out these other resources:
- Getting creative with Computed Columns in SQL Server
- Using Computed Columns in SQL Server with Persisted Values
- How to create indexes on computed columns in SQL Server
- Understand the Performance Behavior of SQL Server Scalar User Defined Functions
- Refactor SQL Server scalar UDF to inline TVF to improve performance






About the author
 Ahmad Yaseen is a SQL Server DBA with a bachelor’s degree in computer engineering as well as .NET development experience.
Ahmad Yaseen is a SQL Server DBA with a bachelor’s degree in computer engineering as well as .NET development experience.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2018-04-27
