By: Pablo Echeverria | Updated: 2018-05-30 | Comments (2) | Related: > SQL Server Agent
Problem
There’s a chance your SQL Server Agent Jobs that have been running smoothly forever, but suddenly for no apparent reason they fail. And when you have a team supporting multiple servers, there’s no guarantee that all jobs have been set up to notify you on failure. Moreover, there are multiple situations that you want to be aware, not only failures such as:
- Jobs that are not going to run
- Jobs that are not notifying you by email
- Jobs that were stopped (a server restart can be the cause)
- Jobs whose duration is abnormal, outside of the average +/- the standard deviation
So, you need a way to get the information across all your SQL Serve instances in a timely manner.
Solution
Querying the SQL Agent Jobs History
In order to query the job history, you’re going to need an index on the [msdb].[dbo].[sysjobhistory] table, because otherwise the information will be retrieved slowly, as it will scan the entire table. The following script creates the index:
USE [msdb] GO CREATE NONCLUSTERED INDEX [IX_sysjobhis_runsta_stepid_rundur] ON [dbo].[sysjobhistory] ([job_id],[instance_id],[run_status],[step_id],[run_duration])
You can run this as a multi-server query in all of your instances at the same time, and if you haven’t purged your job history for a long time, it will take some time to complete:
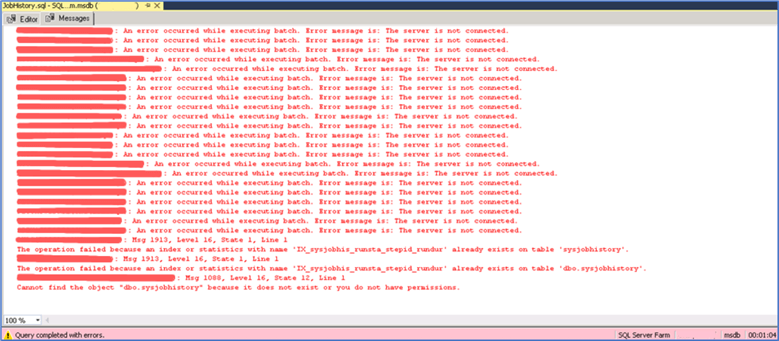
This was run on 150 instances in my environment. Note that you may get errors in cases where:
- The server doesn’t exist anymore, or is unreachable from the server you’re connecting
- The index already exists
- The user you’re connecting with doesn’t have permissions
You will not get a message for the servers where it succeeded.
Once you have created the index, there are additional situations you must consider.
Limit on the number of history rows, per job or in total
If there’s a limit on the number of rows kept for the SQL Server Agent Job history, you may not be able to get a clear picture about how your jobs are performing, especially when there are multiple jobs or they are scheduled to run continuously. The following query will give you information about how they are setup; this can also run as a multi-server query:
DECLARE @Value INT EXEC master.dbo.xp_instance_regread N'HKEY_LOCAL_MACHINE', N'SOFTWARE\Microsoft\MSSQLServer\SQLServerAgent', N'JobHistoryMaxRows', @Value OUTPUT SELECT 'JobHistoryMaxRows: '+CAST(@Value AS VARCHAR) EXEC master.dbo.xp_instance_regread N'HKEY_LOCAL_MACHINE', N'SOFTWARE\Microsoft\MSSQLServer\SQLServerAgent', N'JobHistoryMaxRowsPerJob', @Value OUTPUT SELECT 'JobHistoryMaxRowsPerJob: '+CAST(@Value AS VARCHAR)

Note that you will get errors for the servers that have a SQL Server Express edition because the registry key won’t exist.
If you want to set the same values on all of your servers, you can read this link and run a multi-server query as well.
Scheduled Maintenance Plans
If there’s a scheduled maintenance plan that is deleting information from the job history, you can find it using the following query, as suggested in this link:
DECLARE @xml TABLE([sno] XML)
INSERT INTO @xml
SELECT CAST(CAST([packagedata] AS VARBINARY(MAX)) AS XML)
FROM [msdb].[dbo].[sysssispackages]
WHERE CAST([packagedata] AS VARBINARY(MAX)) LIKE '%RemoveAgentHistory%'
;WITH XMLNAMESPACES ('www.microsoft.com/SqlServer/Dts' AS [p1],
'www.microsoft.com/SqlServer/Dts' AS [DTS],
'www.microsoft.com/sqlserver/dts/tasks/sqltask' AS [SQLTask])
SELECT a.b.value('.','varchar(200)') [PlanName],
c.d.value('./@SQLTask:TaskName','varchar(200)') [TaskName]
FROM @xml
CROSS APPLY sno.nodes('/DTS:Executable/DTS:Property') a(b)
CROSS APPLY sno.nodes('/DTS:Executable/DTS:Executable/DTS:Executable/DTS:ObjectData/SQLTask:SqlTaskData') c(d)
WHERE a.b.value('./@DTS:Name','varchar(200)')='ObjectName'

Once you have the plan name and the task name, you can view the definition under Management. Then you can change it to remove only the data you won’t need.

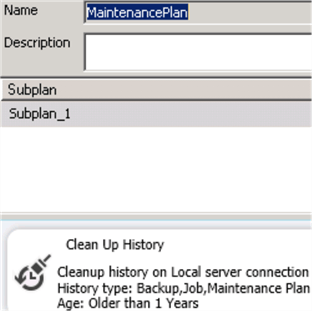
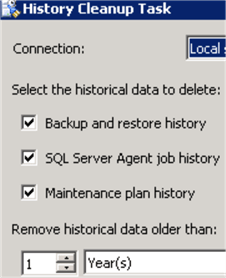
Purging SQL Agent History
You may also have a job that’s purging data as suggested in this tip. If that’s the case, you need to take into account this new index created when you’re partitioning the table.
Or you may have a job that is purging data using the procedure sp_purge_jobhistory, so you need to search in the jobs steps and adjust them as needed.
Script to get all SQL Server Agent Jobs
This is the script ran as a multi-server query to get the information from all jobs across all instances:
USE [msdb]
GO
CREATE TABLE #Info (
[JobId] UNIQUEIDENTIFIER, [Name] VARCHAR(128), [Description] VARCHAR(512), [Enabled] INT, [NotifyEmail] INT,
[NextRun] DATETIME, [SchedFreq] VARCHAR(128), [SubDayFreq] VARCHAR(128), [LastRunId] INT,
[LastRun] DATETIME, [PreviousRunId] INT, [LastDurationSeconds] INT, [LastRunFailedStepCount] INT, [AvgDurationSeconds] INT,
[StdDevDurationSeconds] INT)
INSERT INTO #Info ([JobId], [Name], [Description], [Enabled], [NotifyEmail],
[NextRun], [SchedFreq], [SubDayFreq])
SELECT [j].[job_id], [j].[name], [j].[description], [s].[enabled], [j].[notify_level_email],
[dbo].[agent_datetime](CASE WHEN [js].[next_run_date] <> 0 THEN [js].[next_run_date] ELSE [s].[active_start_date] END,
CASE WHEN [js].[next_run_time] <> 0 THEN [js].[next_run_time] ELSE [s].[active_start_time] END),
CASE [s].[freq_type] WHEN 1 THEN 'Once'
WHEN 4 THEN 'Daily'
WHEN 8 THEN 'Weekly'
WHEN 16 THEN 'Monthly'
WHEN 32 THEN 'Monthly relative'
WHEN 64 THEN 'When agent starts'
WHEN 128 THEN 'When computer idle' END,
CASE [s].[freq_subday_interval]
WHEN 0 THEN 'Once'
ELSE 'Every ' + RIGHT([s].[freq_subday_interval], 2) +
(CASE [s].[freq_subday_type]
WHEN 1 THEN ' Once'
WHEN 2 THEN ' Seconds'
WHEN 4 THEN ' Minutes'
WHEN 8 THEN ' Hours' END) END
FROM [sysjobs] [j]
LEFT JOIN [sysjobschedules] [js] ON [js].[job_id] = [j].[job_id]
LEFT JOIN [sysschedules] [s] ON [s].[schedule_id] = [js].[schedule_id]
WHERE [j].[enabled] = 1
UPDATE [i]
SET [i].[LastRunId] = [h].[instance_id],
[i].[LastRun] = [dbo].[agent_datetime]([h].[run_date], [h].[run_time])
FROM #Info [i]
INNER JOIN [sysjobhistory] [h] ON [h].[instance_id] = (SELECT MAX([instance_id]) FROM [sysjobhistory] [h2] WHERE [h2].[job_id] = [i].[JobId] AND [h2].[step_id] = 0)
UPDATE [i]
SET [i].[PreviousRunId] = (SELECT MAX([instance_id]) FROM [sysjobhistory] [h] WHERE [h].[job_id] = [i].[JobId] AND [h].[step_id] = 0 AND [h].[instance_id] < [i].[LastRunId])
FROM #Info [i]
UPDATE [i]
SET [i].[LastDurationSeconds] = [t].[LastDurationSeconds],
[i].[LastRunFailedStepCount] = [t].[LastRunFailedStepCount]
FROM #Info [i]
INNER JOIN (
SELECT [h].[job_id], SUM(CASE WHEN [h].[run_status] NOT IN (1, 2, 4) THEN 1 ELSE 0 END) [LastRunFailedStepCount],
SUM(CASE WHEN [h].[run_status] = 1 AND [h].[run_duration] > 0 THEN [h].[run_duration]/10000*3600 + ([h].[run_duration]/100)%100*60 + [h].[run_duration]%100 ELSE 0 END) [LastDurationSeconds]
FROM [sysjobhistory] [h]
INNER JOIN #Info [i] ON [i].[JobId] = [h].[job_id] AND [h].[instance_id] > [i].[PreviousRunId] AND [h].[instance_id] < [i].[LastRunId]
GROUP BY [h].[job_id]) [t] ON [t].[job_id] = [i].[JobId]
UPDATE [i]
SET [i].[AvgDurationSeconds] = ISNULL(CASE [t].[AvgDurationSeconds] WHEN 0 THEN 1 ELSE [t].[AvgDurationSeconds] END, 1),
[i].[StdDevDurationSeconds] = ISNULL(CASE [t].[StdDevDurationSeconds] WHEN 0 THEN 1 ELSE [t].[StdDevDurationSeconds] END, 1)
FROM #Info [i]
INNER JOIN (
SELECT [job_id],
AVG([run_duration]/10000*3600 + ([run_duration]/100)%100*60 + [run_duration]%100) [AvgDurationSeconds],
STDEV([run_duration]/10000*3600 + ([run_duration]/100)%100*60 + [run_duration]%100) [StdDevDurationSeconds]
FROM [sysjobhistory]
WHERE [step_id] <> 0
AND [run_status] = 1
AND [run_duration] >= 0
GROUP BY [job_id]) [t] ON [t].[job_id] = [i].[JobId]
SELECT [Name], [Description], [LastRun], [Enabled], [SchedFreq], [SubDayFreq], [NextRun], [LastDurationSeconds],
(CASE WHEN [LastRunFailedStepCount] > 0 THEN 'One or more steps failed'
WHEN [NextRun] IS NULL THEN 'Not going to run'
WHEN [NotifyEmail] = 0 THEN 'Not alerting by email'
ELSE '' END) [Message],
(CASE WHEN [LastDurationSeconds] < ([AvgDurationSeconds] - [StdDevDurationSeconds])
OR [LastDurationSeconds] > ([AvgDurationSeconds] + [StdDevDurationSeconds])
THEN CAST([LastDurationSeconds]/[AvgDurationSeconds] AS VARCHAR)+' times average'
ELSE 'Within average' END) [TimeToComplete],
(CASE WHEN [NextRun] IS NULL THEN '' ELSE 'USE [msdb]; SELECT TOP 10 [step_id], [message], [run_status], [dbo].[agent_datetime]([run_date], [run_time]) [DateTime], [run_duration] FROM [sysjobhistory] WHERE [job_id] = '''+CAST([JobId] AS NVARCHAR(50))+''' ORDER BY [instance_id] DESC' END) [AdditionalInfo]
FROM #Info
WHERE ([LastDurationSeconds] > 15
AND ([LastDurationSeconds] < ([AvgDurationSeconds] - [StdDevDurationSeconds])
OR [LastDurationSeconds] > ([AvgDurationSeconds] + [StdDevDurationSeconds])))
OR [LastRunFailedStepCount] > 0
OR [NextRun] IS NULL
OR [NotifyEmail] = 0
ORDER BY [Name]
DROP TABLE #Info
Note that, because we have created our index to query the job history table efficiently, the 1636 results from all 150 instances are returned in only 12 seconds:
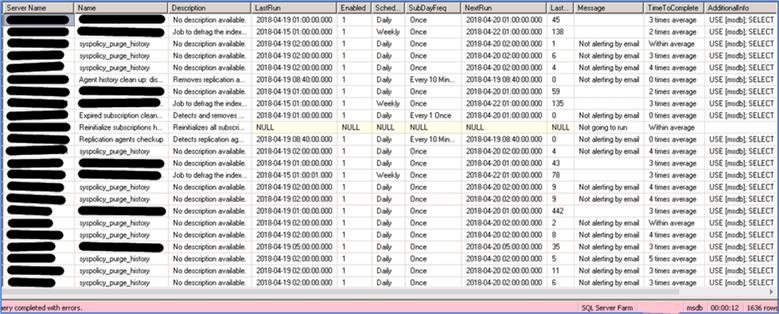
Just take into account that this is only returning information for the jobs that are enabled and have any kind of issue.
The information returned is:
- Server name: This is returned because it’s a multi-server query, but is not included in the script.
- Name: Name of the job.
- Description: Description of the job.
- LastRun: Last time the job ran.
- Enabled: If the schedule is enabled or not. If there are multiple schedules, multiple rows are returned.
- SchedFreq: If the job is scheduled weekly, daily, etc.
- SubDayFreq: If the job is scheduled every 15 minutes, once, etc.
- NextRun: Next date and time the job is expected to run.
- LastDurationSeconds: Number of seconds it took to complete the last time it ran, no matter the schedule.
- Message: Has different warnings
- One or more steps failed: If any step failed or was cancelled on the last run.
- Not going to run: If the schedule prevents the job from running.
- Not alerting by email: If the job is not configured to alert by email.
- TimeToComplete: If the last duration is within the average +/- the standard deviation. If it is below, it will show as “0 times average” or “1 times average”. If it is above, it will show as 2+ times average.
- AdditionalInfo: A command you can run by connecting to the server, which will display the last 10 records of the job history, so you can see what has happened and why it was returned. To interpret the history, you need to take a look at this link.
An easy way to see what you need to take care of immediately is to copy the data to an Excel spreadsheet and sort and filter the data on what is more important.
Next Steps
- You can run the script and check if you’re having issues with your jobs.
- You can learn more about the job history in this link.
- You can schedule the script to run on a daily basis, but you need to run it against all of your instances. Check out this tip about how to do that.






About the author
 Pablo Echeverria is a talented database administrator and C#.Net software developer since 2006. Pablo wrote the book "Hands-on data virtualization with Polybase". He is also talented at tuning long-running queries in Oracle and SQL Server, reducing the execution time to milliseconds and the resource usage up to 10%. He loves learning and connecting new technologies providing expert-level insight as well as being proficient with scripting languages like PowerShell and bash. You can find several Oracle-related tips in his LinkedIn profile.
Pablo Echeverria is a talented database administrator and C#.Net software developer since 2006. Pablo wrote the book "Hands-on data virtualization with Polybase". He is also talented at tuning long-running queries in Oracle and SQL Server, reducing the execution time to milliseconds and the resource usage up to 10%. He loves learning and connecting new technologies providing expert-level insight as well as being proficient with scripting languages like PowerShell and bash. You can find several Oracle-related tips in his LinkedIn profile.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2018-05-30
