By: Aaron Bertrand | Updated: 2018-06-22 | Comments (3) | Related: > Functions System
Problem
In a previous tip, Use SQL Server’s UNPIVOT operator to help normalize output, I showed one approach to turn flattened, comma-separated strings into relational data. A user commented on the tip, saying that they had the opposite problem: they wanted to take a set of normalized data (a one-to-many relationship between users and their phone numbers), and flatten that data into a single, comma-separated string of phone numbers for each user. Is there a concise and efficient way to do this in SQL Server?
Solution
SQL Server has two great methods for grouped concatenation: STRING_AGG(), introduced in SQL Server 2017 (and now available in Azure SQL Database), and FOR XML PATH, if you are on an older version. They have different performance characteristics and can be sensitive to minor syntax details, and I’ll deal with those differences as we go along.
First, let’s look at some simple tables and sample data:
CREATE TABLE dbo.Users
(
UserID int CONSTRAINT PK_Users PRIMARY KEY,
Name sysname CONSTRAINT UQ_UserName UNIQUE
);
GO
CREATE TABLE dbo.UserPhones
(
UserID int CONSTRAINT FK_UserPhones_Users
FOREIGN KEY REFERENCES dbo.Users(UserID),
PhoneType varchar(4) NOT NULL,
PhoneNumber varchar(32) NOT NULL
);
GO
INSERT dbo.Users(UserID, Name) VALUES
(1,N'John Doe'),(2,N'Jane Doe'),(3,N'Anon E. Mouse');
INSERT dbo.UserPhones(UserID, PhoneType, PhoneNumber)
VALUES(1,'Home','123-456-7890'),(1,'Cell','456-789-1234'),
(2,'Work','345-678-1291'),(2,'Cell','110-335-6677');
GO
The desired output:
Name PhoneNumbers ---------------- ------------------------------------ Anon E. Mouse Jane Doe Cell 110-335-6677, Work 345-678-1291 John Doe Cell 456-789-1234, Home 123-456-7890
So first, let’s see what we would in versions earlier than SQL Server 2017. The first attempt would likely be:
SELECT
u.Name,
PhoneNumbers =
(
SELECT ', ' + p.PhoneType + ' ' + p.PhoneNumber
FROM dbo.UserPhones AS p
WHERE p.UserID = u.UserID
FOR XML PATH('')
)
FROM dbo.Users AS u
ORDER BY u.Name;
Results:
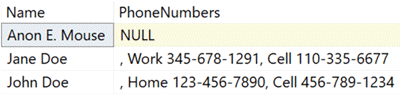
You may notice that the rows are ordered correctly, but the phone numbers are not listed alphabetically. We’re also returning a NULL value for the first row, whereas the desired result lists that as an empty string. Finally, we’ve concatenated with a leading comma, but the first one sits at the beginning of the string like a sore thumb. Let’s deal with the latter artifact first, using our good friend STUFF() to replace the first two characters in the concatenated string with an empty string:
SELECT
u.Name,
PhoneNumbers = STUFF
(
(
SELECT ', ' + p.PhoneType + ' ' + p.PhoneNumber
FROM dbo.UserPhones AS p
WHERE p.UserID = u.UserID
FOR XML PATH('')
), 1, 2, N''
)
FROM dbo.Users AS u
ORDER BY u.Name;
This yields:
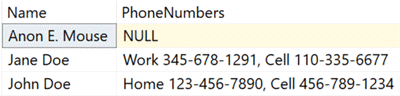
Next, to get rid of the NULL value, we’ll introduce COALESCE(), another handy friend, to replace that NULL with an empty string:
SELECT
u.Name,
PhoneNumbers = COALESCE(STUFF
(
(
SELECT ', ' + p.PhoneType + ' ' + p.PhoneNumber
FROM dbo.UserPhones AS p
WHERE p.UserID = u.UserID
FOR XML PATH('')
), 1, 2, N''
), N'')
FROM dbo.Users AS u
ORDER BY u.Name;
Results:

Next, to deal with the ordering, we can add an ORDER BY clause to the inner query:
SELECT
u.Name,
PhoneNumbers = COALESCE(STUFF
(
(
SELECT ', ' + p.PhoneType + ' ' + p.PhoneNumber
FROM dbo.UserPhones AS p
WHERE p.UserID = u.UserID
ORDER BY p.PhoneType
FOR XML PATH('')
), 1, 2, N''
), N'')
FROM dbo.Users AS u
ORDER BY u.Name;
Finally, the results look right:

But this has become a really messy query, even after forcing myself to format it for consistency rather than legibility. Hopefully you are on SQL Server 2017, or will be there soon, or are using Azure SQL Database, and you can accomplish all of this using much less convoluted syntax that is less sensitive to performance issues, using STRING_AGG() WITHIN GROUP():
SELECT
u.Name,
PhoneNumbers = STRING_AGG(CONCAT(p.PhoneType, ' ', p.PhoneNumber), ', ')
WITHIN GROUP (ORDER BY p.PhoneType)
FROM dbo.Users AS u
LEFT OUTER JOIN dbo.UserPhones AS p
ON u.UserID = p.UserID
GROUP BY u.Name
ORDER BY u.Name;
Results:
Regarding performance, I created a much larger data set:
-- delete our sample data
DELETE dbo.UserPhones;
DELETE dbo.Users;
-- turn off foreign key constraint, so we can generate phone numbers first:
ALTER TABLE dbo.UserPhones NOCHECK CONSTRAINT FK_UserPhones_Users;
-- insert ~2 million rows into the phones table:
;WITH x AS (SELECT TOP (100) name FROM sys.all_columns)
INSERT dbo.UserPhones(UserID, PhoneType, PhoneNumber)
SELECT
UserID = ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) / 2,
PhoneType = pt.Name,
pp.PhoneNumber
FROM AdventureWorks.Person.PersonPhone AS pp
CROSS JOIN x
INNER JOIN AdventureWorks.Person.PhoneNumberType AS pt
ON pp.PhoneNumberTypeID = pt.PhoneNumberTypeID;
GO
-- get ~1 million users into the users table:
INSERT dbo.Users(UserID, Name)
SELECT UserID, N'User' + RIGHT('00000000' + CONVERT(varchar(11), UserID), 8)
FROM dbo.UserPhones
GROUP BY UserID;
GO
-- delete some random rows (for fun):
DELETE dbo.UserPhones WHERE UserID % 676 = 0;
GO
-- re-enable and re-trust foreign key constraint:
ALTER TABLE dbo.UserPhones WITH CHECK CHECK CONSTRAINT ALL;
GO
This doesn't make truly realistic data, but you can spot check it:
SELECT TOP (10) *, COUNT(*) OVER() FROM dbo.Users; SELECT TOP (10) *, COUNT(*) OVER() FROM dbo.UserPhones;
Then I ran our eventual XML PATH query against the new STRING_AGG() query, and analyzed the results with the SentryOne Plan Explorer. Note that I ran this batch multiple times to be sure that one method didn't benefit from another query's work loading the data into buffer, updating statistics, and so on.
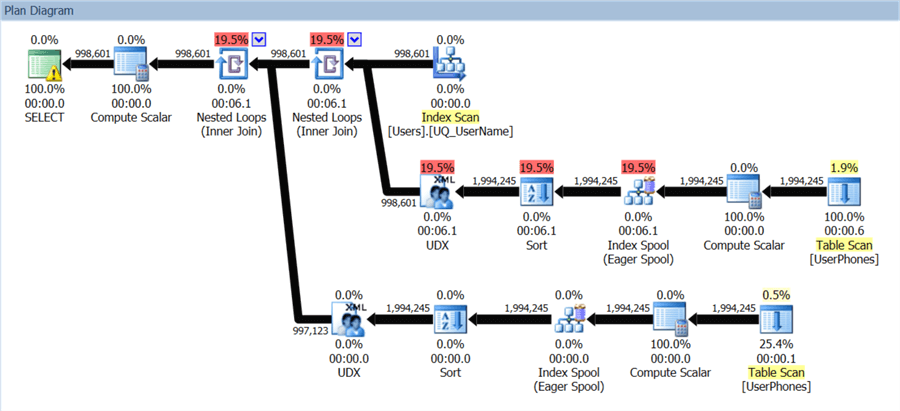
First, the statement tree shows us that the FOR XML PATH query is much more expensive (and took 20X longer to complete), due to both using more CPU and requiring more I/O:

The execution plan for the XML PATH version yields some clues, including two sort operators:
If we switch to Costs By I/O, we see where all the I/O work was done (the workfile/worktable behind the expensive index spools):
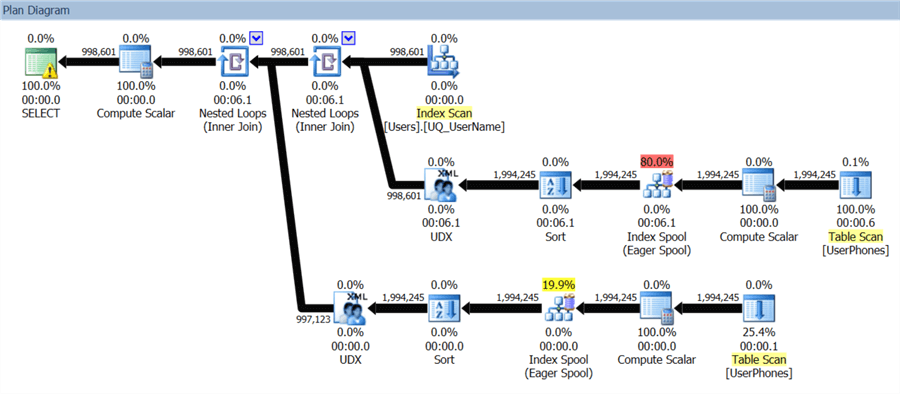
And the tooltip on the root node reveals that likely none of these operations were handled in memory:
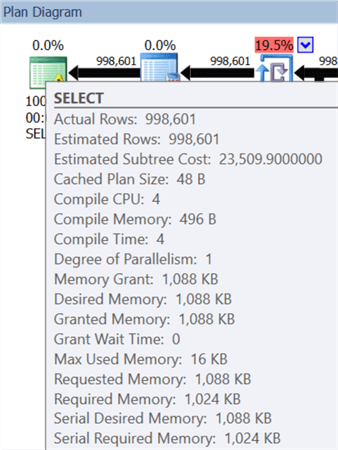
It asked for a measly 1 MB of memory to process this query, and only actually used 16 KB.
Compare that to the STRING_AGG version, which only has a single sort operator, and was able to benefit from parallelism:
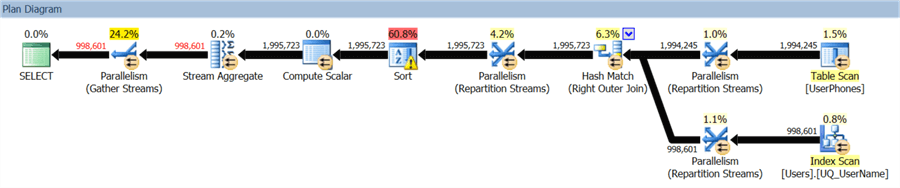
This query uses a lot more memory, which is great when you have it. Still, that one sort operator spilled to tempdb on my system, so concurrency may become a concern, in which case you can limit memory in a variety of ways.
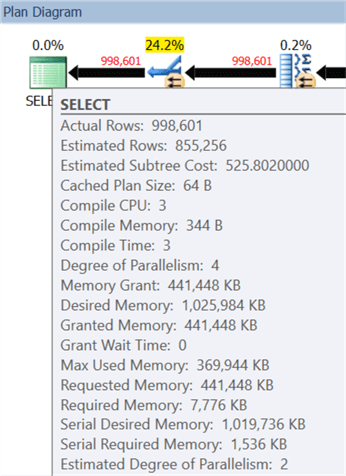
With a 3 second runtime vs. the 73 seconds taken by FOR XML PATH, though, you might be okay here.
Summary
I have shown two methods of building a comma-separated string of multiple values, from the “many” side of a one-to-many relationship, using FOR XML PATH and the newer STRING_AGG() approach. They have unique performance characteristics at larger scale, but hopefully you’re in a position to choose. For other options, you can always look into CLR (Common Language Runtime).
Next Steps
Read on for related tips and other resources:
- T-SQL Enhancements in SQL Server 2017
- Solve old problems with SQL Server’s new STRING_AGG and STRING_SPLIT functions
- Concat Aggregates SQL Server CLR Function
- STRING_AGG (Transact-SQL) (MSDN)






About the author
 Aaron Bertrand (@AaronBertrand) is a passionate technologist with industry experience dating back to Classic ASP and SQL Server 6.5. He is editor-in-chief of the performance-related blog, SQLPerformance.com, and also blogs at sqlblog.org.
Aaron Bertrand (@AaronBertrand) is a passionate technologist with industry experience dating back to Classic ASP and SQL Server 6.5. He is editor-in-chief of the performance-related blog, SQLPerformance.com, and also blogs at sqlblog.org.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2018-06-22
