By: Derek Colley | Updated: 2018-07-11 | Comments (4) | Related: > Azure
Problem
Azure DB is a virtual Microsoft Azure offering that provides a SQL Server service directly accessible via a URL-based connection string. In return for a subscription fee, one can create, connect to and use a significant proportion of the capabilities of an on-premises SQL Server database engine at a fraction of the cost and with swift and painless deployment. However, judging the correct service tier in which to create your new Azure DB is difficult. Get it right, and you may be paying for more than you need. Get it wrong, and you'll start seeing service throttling as you hit your resource quotas. How do we estimate which model, tier and number of DTUs / vCores are appropriate for the workload we are migrating?
Solution
Performance of an Azure DB is governed by two models, the DTU-based model and the vCore-based model, and each provide differing levels of service tier and grade of service. Within the tiers we can define our DTU levels / vCores. This tip will define all these key terms and provide more information on the levels of service each combination provides. We will look at features and limitations, and demonstrate how to estimate our model, tier and DTU/vCore requirements using a decision flowchart. We'll also introduce the Azure SQL Database DTU Calculator. Finally, we'll cover the anatomy of a DTU, sum up and offer links for further reading.
Note: I reference other articles as [n] in this article. Refer to the list of references at the end of this article.
Azure DB Models
Microsoft currently offer Azure DB in two models, the DTU model and the vCore model. The DTU model is based on the Database Transaction Unit, and is a blended mix of CPU, I/O and memory (RAM) capabilities based on a benchmark OLTP workload called ASDB. The vCore model is based on the number of virtual CPU cores you require, and this can be scaled up as your workload increases.
The DTU model works well if you have pricing constraints or have a fairly stable workload. It is also scalable, as you are able to upgrade the tier or grade of your Azure DB in the future. However, in the DTU model CPU capabilities and storage capabilities are closely coupled; DTUs are a mix of CPU, I/O and memory as we'll discuss in the section 'Anatomy of a DTU' and so if you need more granular control over your CPU or storage requirements, vCore might be best for you. The vCore model is split into the General Purpose and Business Critical tiers.
Microsoft state [3] that as a rule of thumb, every 100 DTU in the Standard tier requires at least 1 vCore in the General Purpose tier, and every 125 DTU in the Premium tier requires at least 1 vCore in the Business Critical tier. Where your DTU requirements are less than 1 vCore, it is not recommended to use the vCore model.
The vCore model supports up to 80 vCores (CPUs) and 7 GB of memory is allocated per vCore. The Business Critical tier also offers In-Memory OLTP support; 3 replicas; and local SSD storage up to 4TB. In the General Purpose tier, you can expect 500 IOPS per vCore with a maximum allowance of 7,000 IOPS, and in the Business Critical tier you can expect 5,000 IOPS per vCore with a maximum allowance of 200,000 IOPS. This means we must work out our DTU requirements in order to come to a rational decision on which model to use, DTUs or vCores. On to Service Tiers, which will help us determine what these are.
Azure Service Tiers
When we create an Azure DB in the DTU model, we first select a tier - Basic, Standard or Premium, and the definition of the DTU actually depends on this tier - as it's pegged to a benchmark standard called ASDB, this benchmark gives different definitions depending on the tier selected. So, one DTU in Standard is not equal to one DTU in Premium.
However, guidance is available in choosing a service tier. We have six core considerations - backup retention, CPU, IO throughput, IO latency, whether we need columnstore indexing, and whether we need in-memory OLTP. See 'Choosing a service tier' in [1]. We can also use the decision flowchart below, which consolidates the limits imposed by each Service Tier into a series of yes/no workflow questions to aid planning.
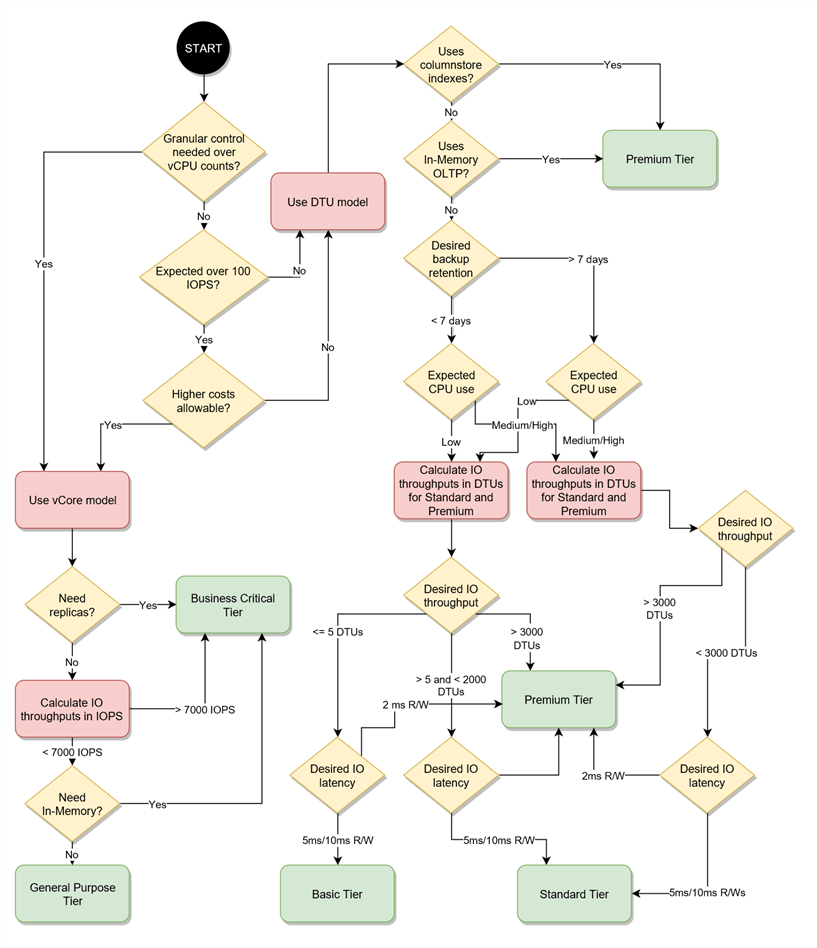
Let's work through the flowchart with an example.
First, consider columnstore indexing. If you have columns in your tables with low selectivity (where the ratio of distinct values in your column to total cardinality is low, such as gender) then columnstore indexes can be a great choice if queries depend on filtering on these columns. Can you live without this? Azure DB offers columnstore index support only in the Standard tier (providing you buy the S3 grade or above - we'll cover performance levels in the next section) and Premium tier. For the purposes of the flowchart we'll assume if you want CS indexing, you'll want Premium, but bear the S3 requirement in mind.
Next, consider in-memory OLTP. As with columnstore indexing, are you using in-memory tables? Can you live without them? These are available only in the Premium tier.
Basic allows just 7 days backup retention, whereas Standard and Premium allow backup policies to extend to 35 days (and beyond, with a long-term backup retention policy). So, if 7 days retention doesn't do it for you, Basic is already ruled out.
CPU - Basic is suitable for workloads with a 'Low' CPU requirement. Standard is suitable for 'Low, Medium, High' and Premium for 'Medium, High'. Now translating this is rather tricky. A good rule of thumb might be to look at your CPU levels using perfmon / DMVs (see IO discussion below), factor in the number of cores you have in use and estimate which category your workload falls into.
When determining IO throughput, 2.5 IOPS per DTU (Basic and Standard tiers) provides an easy basis to calculate the number of DTUs we need if we know our IOPS requirement. And considering that IOPS is calculable from Mbps and block size, and we know SQL Server uses 64KB blocks, we can fairly simply work out our IO requirement by measuring read and write throughput (Mbps) on our on-premises database.
Let's work through a calculation. First, how do we measure database IO throughput? One method is to use perfmon to create a Data Collector Set which gathers this information. If we have the good fortune to have our on-premise database separated from other DBs, we can use Disk Bytes/sec to capture throughput into a CSV file over the course of a day and find the figures from a simple ordering of the output data in Excel (don't forget to convert bytes to MB!) We can also observe and estimate using Resource Monitor or use the SQL Server DMVs. This tip isn't focused on perfmon manipulation but if you'd like a walkthrough in setting up performance counters, see fellow MSSQLTips author Matteo Lorini's excellent tip [2] on finding disk bottlenecks.
Now, let's assume you have found a low-water mark of 5MBps, a high-water mark of 150MBps and a median figure of 30MBps. Let's translate that into IOPs using the well-understood formula IOPS = (MBps / KB per IO) * 1024. So, in our case, this translates to a low-water mark of 80 IOPs, a median of 480 IOPS and a high of 2400 IOPs.
At 2.5 IOPs per DTU in the Basic and Standard tiers we can easily forecast the DTUs required to sustain our observed level of IO activity by dividing by 2.5. This yields a low of 32 DTUs, a median of 192 DTUs and a high of 960 DTUs (in the premium tier, 48 IOPS per DTU are allowed, so this yields 1.6 DTUs, 10 DTUs and 50 DTUs respectively). We now need to compare our numbers against the maximum number of DTUs allowed under each tier.
As detailed in [1], for Basic it's just 5 DTUs - Standard it's 3,000, and in Premium it's 4,000. So, in our example, having calculated a high-water mark of 2400 IOPS, it's tempting to panic and go straight for the Premium banding of service tier, which would cost more to maintain. However, Standard actually meets our needs - in terms of I/O alone, the Premium band, with its differing DTU definition (at 50 Premium DTUs, we could scale up our maximum IO needs 80 times before running out of DTUs!) is overkill for our situation.
When it comes to IO latency, Basic and Standard tier both offer 5ms reads and 10ms writes, fairly standard latency targets for best practice in on-premise databases. Note however that Premium offers just 2ms read and write latency. If latency is important to your applications (are you at risk of experiencing timeouts or have exceptionally fast data consumption requirements?) then consider Premium. Also consider that if your latency requirements are super-low (think banking, stock exchange, large-scale e-commerce) then think about network latency too, which will depend on where your apps reside.
On database sizing: Not shown in the flowchart is database size. Seasoned DBAs will recognize the parallels here with the various editions of SQL Server, where Express used to provide 2GB (now 10GB) through to Enterprise, which is effectively unlimited. In Azure DB, the Basic tier has a maximum 2GB size limit. The Standard tier is 1TB, and the Premium tier has a maximum of 4TB. If you can't archive or remove redundant data, then look at your on-premises database size and fit it into the right tier as appropriate.
Hopefully by now you have reached the end of your path through the flowchart and have enough information to work out which model and tier you need to select. We'll now look at performance levels.
Azure DB Service Performance Levels
Now you've estimated your desired CPU performance, memory expectation, IOPs and available features, it's time to choose a performance level based on your choice of model and tier. Microsoft provide comparative tables to allow you to choose the appropriate level for you [4] and [5]. They are too lengthy to summarize here so ensure you take a look at them.
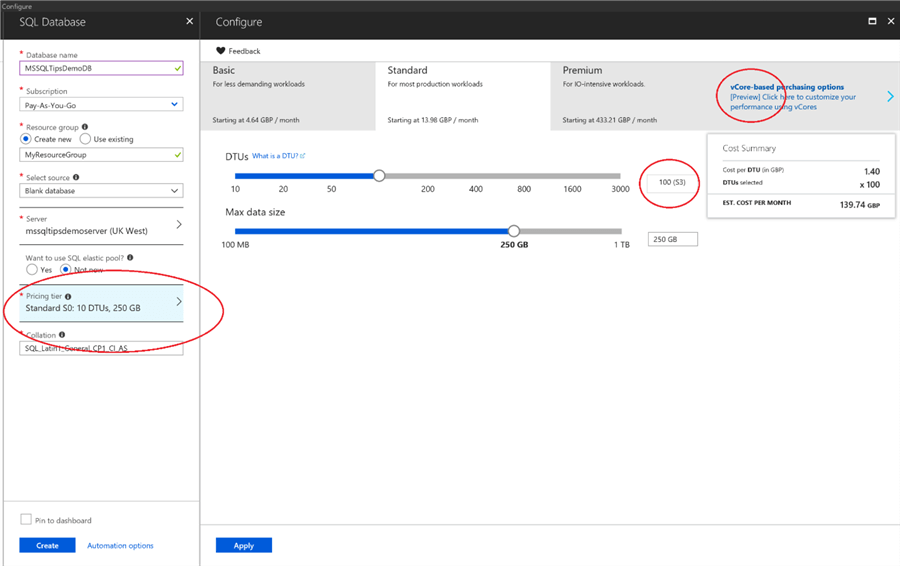
DTU performance levels are named as a letter and a digit. The letter determines the service tier, and the digit determines, in ascending order, the performance category. So S0 is the lowest-performing level of the Standard Tier (DTU model) whereas P4 is a middle-performing level in the Premium tier. For the vCore-based model, the naming convention is comprised of the tier, the CPU generation, and the number of vCores. So, GP_Gen4_8 denotes a Generation-4 CPU in the General Purpose tier with 8 vCores. The Generation-4 CPU is based on an Intel E5-2673 v3 (Haswell) 2.4-GHz processor. The following screenshot shows how this is configured when creating the database. Note we can use the sliding scale to move up and down the S-levels depending on how many DTUs and how much storage space is required. Also note the option to use the vCore model in the top-right.
We've covered the basics of the service tier limits, but also bear in mind that extra limits in the form of maximum concurrent workers (requests) and maximum concurrent sessions are also mandated here. So, it's well worth checking your number of user connections and number of concurrent requests (you can use perfmon counters for both - User Sessions and Batch Requests Per Second map nicely) too. Basic has a limit of 30 BRPS and 300 concurrent sessions; Standard Tier scales from 600 to 6,000 BRPS and 600 to 30,000 concurrent sessions as you choose successive performance levels; Premium from 200 BRPS to 6,400 BRPS and 30,000 concurrent sessions across the board. In the vCore model, BRPS starts at a maximum of 200 under GP_Gen4_1 scaling to 8,000 BRPS under BC_Gen5_80.
Using the tables in [4] and [5], coupled with your previous determination using the decision flowchart, you should now have enough information to determine the appropriate model, tier and performance level to suit the workload you are migrating. However, with so many moving parts it's easy to get confused, and there is a substantial burden of analysis on the DBA or database architect to plan effectively for Azure DB migration. For this reason, Microsoft have made available a special calculator to assist in part of the process, the DTU calculations.
Supplementary Tooling
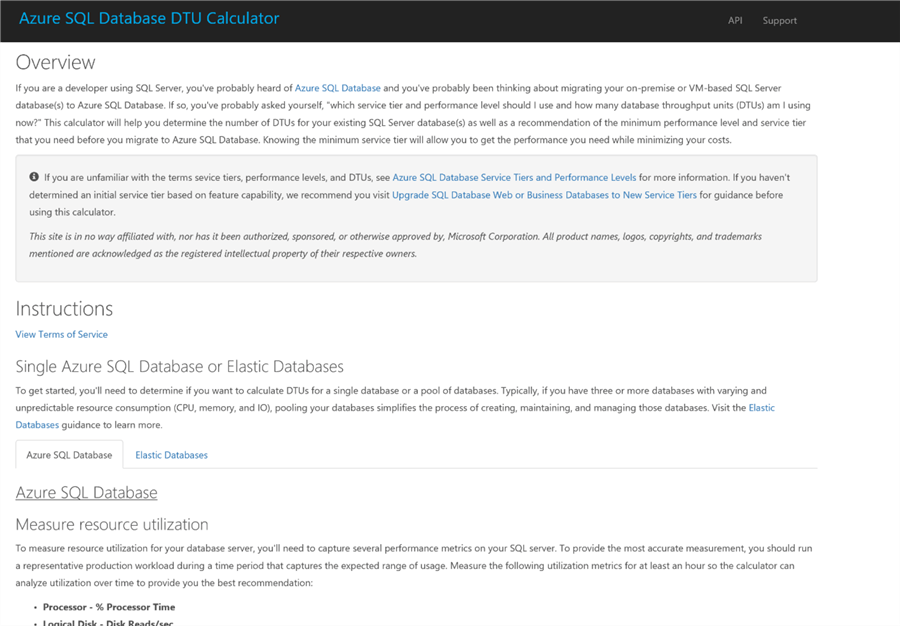
The Azure SQL Database DTU Calculator [6] is a tool written by Justin Henriksen in 2015 to help planners determine the appropriate DTU levels based on their workload. By consuming a CSV file of information from perfmon resource counters, the tool will provide a series of charts depicting the percentage of time that the measured resource consumption fits within the limits of each Service Tier and performance level. The data can be broken down into CPU, IOPS and log activities.
I would always recommend, when gathering information for operations such as migrations, to fetch information from more than one source and cross-reference this information to arrive at conclusions. This process is called triangulation - in this sense, this means use the information you have gathered from your workload in conjunction with the decision flowchart above, the performance level tables from Microsoft and cross-reference this with the outcomes from tools like the DTU calculator to arrive at a specific combination of model, service tier and performance level.
Please also note that this tool is not authored by or associated with the author of this tip or MSSQLTips.com, and so no liability can be assumed for any loss or damage resulting from its use.
If you're already on Azure DB and suffering performance woes from a poor fit for your workload to the model, tier and performance level, consider using Azure SQL Database Query Performance Insight [7]. This tool allows you to examine your DTU resource consumption and examine top queries in your Azure DB (by CPU, duration and execution count). You're also able to view query details and history. In the same way that Query Store allows this for on-premises databases in SQL 2016 onwards, this tool is also built on Query Store, with Azure providing some front-end analytics for review. The tool is available from the Azure portal, in the left-side menu from your Azure DB, labeled Query Performance Insight.
The Anatomy of a DTU
Now we're comfortable with the idea of models, service tiers and performance levels, let's delve into the anatomy of a DTU (applies to DTU-based model only). What makes a DTU? The Database Transaction Unit, as mentioned before, is a blended mix of CPU, memory and IO allocation and is determined by running through benchmark (ASDB) tests. Its definition is dependent on the service tier. Let's summarize those tests here - you can find more detailed information in [8].
The schema for the benchmark consists of 6 tables; 2 are fixed-size, 3 tables are sized proportionately to the number of users, database size and performance level, and the population of 2 tables change throughout the benchmark workload. The schemas are filled with randomly-generated data in fixed distributions.
The workload is 2:1 reads to writes, distributed over 9 categories. Examples of these categories are 'read-lite', which means in-memory, read-only load, and 'Update Heavy' - write-heavy, on-disk load. These are mixed in various proportions: 'read-lite' constitutes around 35% of the workload, 'update-lite' 20%, 'CPU heavy' 10% and the remaining 35% distributed across the other 6 categories.
Scaling is done via 'scale-factor units'. Each scale-factor unit is approximately 100MB - 150MB in size increasing logarithmically. During testing, 1 user (active database connection) is generated for each scale-factor unit, and these have a direct correlation to the Service Tier and performance level. The table in [8] shows all details, but as an example, the DTU for Premium in performance level 1 (P1) is partly defined as the responsiveness of the workload with 200 concurrent users and a database size of 28GB (40 scale-factor units). Therefore, the definition of a DTU is dependent on number of users and database size, which are dependent on service tier and performance level.
Key metrics are throughput, measured at different granularity levels depending on tier, and response time thresholds, again dependent on tier. For example, granularity for Premium is transactions per second, but for Basic it is transactions per hour, meaning performance can be inconsistent across the hour for Basic whereas quality of transaction throughput metrics are higher for Premium. There are also more stringent requirements for a DTU in the Premium tier, where 95% of all transactions should finish in 0.5 seconds or below (compared to 80% of all transactions within 2 seconds or below in Basic).
A Note on Elastic Pools:
Before we end, we must note a change of terminology when considering elastic pools. Elastic pools are not covered here but warrant consideration if looking to deploy multiple Azure DB services. These are pools of resource used to group together Azure DB services to share resources. When one service is fallow, another can use the 'spare' resource that would otherwise be allocated to the first resource for its own workload. Elastic pools are covered more comprehensively in [9] and the key concepts of model, service tier and performance level still apply. However, note that DTUs become 'eDTUs', able to be allocated between Azure DBs as resource levels demand.
Summary
DTU construction is a complicated business, and at the time of writing Microsoft has not made available the exact algorithms used to construct DTU definitions, so we must use the published information as best we can. DTUs are artificial measures denoting load on an Azure DB service, built from a mix of CPU, IO and memory use depending on tier and based on a benchmark standard. Azure service models are split into DTU-based and vCore-based. The DTU-based model has the Basic, Standard and Premium tiers, and the vCore-based is split into the General Purpose and Business Critical tiers. The DTU model is useful for most workloads, but CPU and IO capabilities scale proportionately; vCore is best for higher workloads with a need for independent CPU and IO scalability. The Basic, Standard and Premium tiers in the DTU model each have limitations, and these can affect which combination of model, tier and level is chosen for your workload. A decision matrix is provided to help make those decisions, and supplementary tooling in the form of a DTU calculator and query insight tool are introduced. Finally, we summarized the internals of the DTU benchmarking process.
Next Steps
Hopefully this tip has gone some way in consolidating the information on Azure DB service levels and helped you to plan for your upcoming Azure DB migration or resize your existing one. Any comments or questions are always appreciated.
Thank you for reading and if you'd like to know more about any concept discussed, please use the links below.
- [1] Microsoft Corporation, 2018. DTU-based purchasing model for Azure SQL Database. Available at: https://docs.microsoft.com/en-us/azure/sql-database/sql-database-service-tiers-dtu
- [2] Matteo Lorini, MSSQLTips.com. Perfmon Counters to Identify Disk Bottlenecks. Available at: https://www.mssqltips.com/sqlservertip/2460/perfmon-counters-to-identify-sql-server-disk-bottlenecks/
- [3] Microsoft Corporation, 2018. vCore-based purchasing model for Azure SQL Database (preview). https://docs.microsoft.com/en-us/azure/sql-database/sql-database-service-tiers-vcore
- [4] Microsoft Corporation, 2018. Azure SQL Database DTU-based resource
model limits.
https://docs.microsoft.com/en-us/azure/sql-database/sql-database-dtu-resource-limits - [5] Microsoft Corporation, 2018. Azure SQL Database vCore-based purchasing model limits (preview). https://docs.microsoft.com/en-us/azure/sql-database/sql-database-vcore-resource-limits
- [6] Justin Henriksen, 2015. Azure SQL Database DTU Calculator.
http://dtucalculator.azurewebsites.net/ - [7] Microsoft Corporation, 2018. Azure SQL Database Query Performance Insight. https://docs.microsoft.com/en-us/azure/sql-database/sql-database-query-performance
- [8] Microsoft Corporation, 2018. Azure SQL Database DTU benchmark overview. https://docs.microsoft.com/en-us/azure/sql-database/sql-database-benchmark-overview
- [9] Microsoft Corporation, 2018. Elastic pools help you manage and scale multiple Azure SQL databases. https://docs.microsoft.com/en-us/azure/sql-database/sql-database-elastic-pool






About the author
 Dr. Derek Colley is a UK-based DBA and BI Developer with more than a decade of experience working with SQL Server, Oracle and MySQL.
Dr. Derek Colley is a UK-based DBA and BI Developer with more than a decade of experience working with SQL Server, Oracle and MySQL.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2018-07-11
