By: Artemakis Artemiou | Updated: 2018-08-09 | Comments | Related: 1 | 2 | 3 | 4 | 5 | 6 | 7 | > Application Development
Problem
This tip will help you to better understand what connection pooling is in the data access world. Also, after reading this tip, you will have more knowledge on how to take advantage of the connection pooling mechanism when writing .NET data access code that communicates with SQL Server.
Solution
In its simplest explanation, a connection pool is a cache of database connections. Within this tip’s context, we will talk about ADO.NET connection pooling and even more specifically, we will talk about how you can take advantage of SQL Server connection pooling from your .NET application (i.e. a C# program). At this point it is worth mentioning that connection pooling is a mechanism widely supported in software engineering and is supported by all major DBMSs.
In .NET, connection pooling is automatically used under certain conditions. Understanding the benefits of connection pooling and how it works, can help you manage your database connections when writing data access code more efficiently, thus enabling your application to be more performant and robust.
Why is Connection Pooling Needed?
In a few words: for performance, for application stability, for avoiding exhaustion of database connection pools, and more. For example, in order to establish a single database connection from a C# program to a SQL Server instance, there is a series of steps that takes place in the background. These steps can include: establishing the actual network connection to a physical channel (i.e. a TCP/IP socket/port), the initial handshake between the source and the destination, the parsing of connection string information, database server authentication, authorization checks, and much more.
Now, imagine having an application opening and closing database connections all the time (or even worse; not closing the database connections), without reusing at least some of the already cached database connection pools. In some cases, this could be a situation that would lead to an exhaustion of database connection pools, and consequently would possibly lead to an application crash (if not proper exception handling is in place).
How Does Connection Pooling Work in ADO.NET?
ADO.NET provides connection pooling capabilities with the use of a pooler. This pooler manages connections by keeping alive a number of established connections for any given connection configuration in the data application that uses ADO.NET. A connection configuration is actually the connection string used for that connection. When the code calls “Open” on a connection, if that connection’s configuration has been used earlier, then it is highly possible that a cached connection is kept alive by the pooler and so this connection is served instead of establishing a new connection to the database. This saves time and resources. When the code calls “Close” on the connection, the pooler returns it back to the connection pool/cache, thus keeping it alive for a future call, that is the call for a new “Open” command on the same connection configuration/connection string.
Example of Connection Pooling Using C# and SQL Server
The information above covered the theory behind the connection pooling technique. Now it’s time to see an example in order to fully understand what was discussed above.
This example features 3 SQL Server databases on a SQL Server 2017 instance:
- SampleDB1
- SampleDB2
- SampleDB3
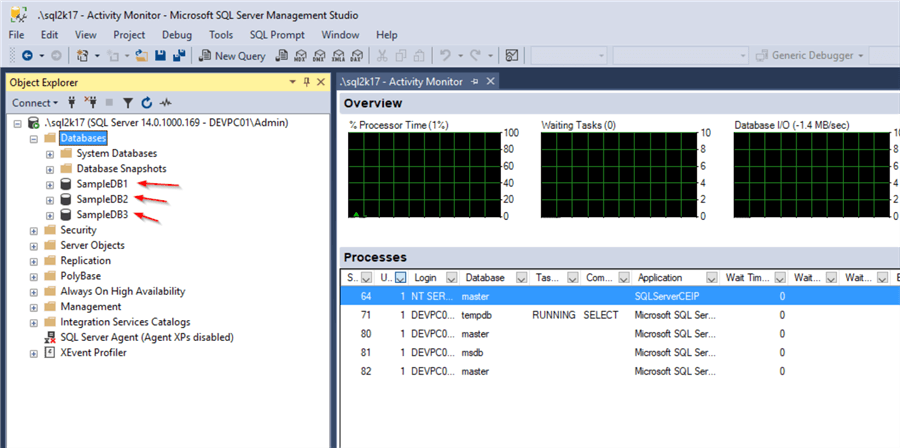
Let’s start by checking out the SSMS Activity Monitor. We see that there are currently not any connections on any of the above databases in SQL Server:
Now, let’s write some C# code (in this case, a C# console application) that accesses the above 3 sample databases using ADO.NET:
using System; using System.Collections.Generic; using System.Data.SqlClient; using System.Linq; using System.Text; using System.Threading.Tasks; namespace ConnectionPoolingExample1 { class Program { static void Main(string[] args) { using (SqlConnection connection = new SqlConnection(@"Server=.\SQL2K17;Database=SampleDB1;Trusted_Connection = yes")) { connection.Open(); } using (SqlConnection connection = new SqlConnection(@"Server=.\SQL2K17;Database=SampleDB2;Trusted_Connection = yes")) { connection.Open(); } using (SqlConnection connection = new SqlConnection(@"Server=.\SQL2K17;Database=SampleDB3;Trusted_Connection = yes")) { connection.Open(); } Console.ReadLine(); } } }
Note: In the above example I’m connecting to a named SQL Server instance named “.\SQL2K17”.
Next, we run the above code (without pressing “Enter” upon its execution, because this would close the application and terminate all database connections). We check again the Activity Monitor in SQL Server Management Studio and we can see that, as expected, there are three connections established each one to the respective sample database:
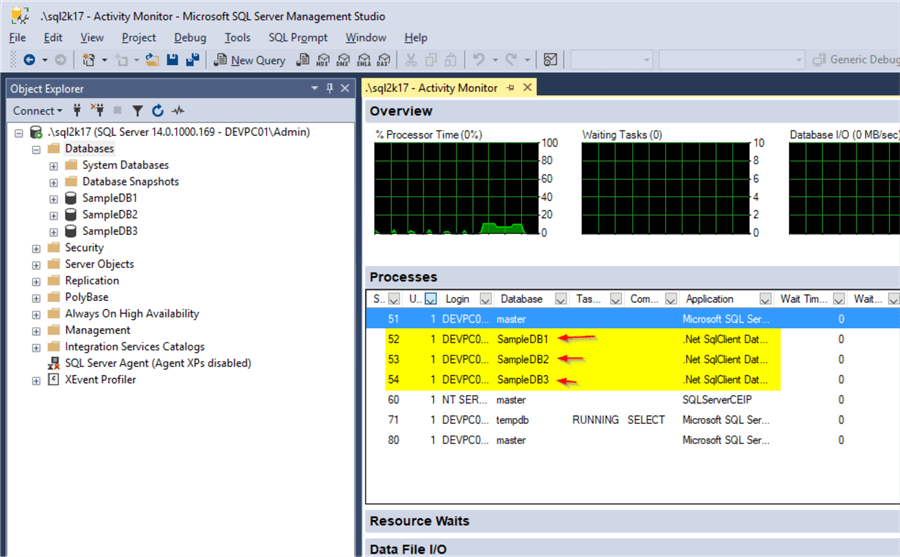
So far, so good. As expected, we get 3 different database connections because our code had 3 different connection strings. No connection pooling was applicable for the above scenario.
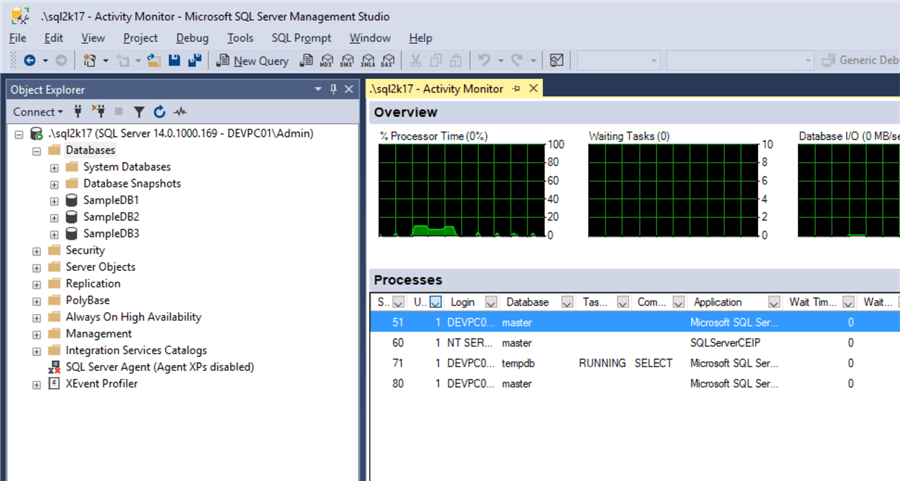
In the meantime, now you can press “Enter” in order to close this sample application. Just to confirm that by the time the application closes, the database connections are terminated as well, you can check the below screenshot:
Now, let’s see connection pooling in action. Let’s add two more SQL Server calls in our code, but again, for sample databases “SampleDB1” and “SampleDB2”. Here’s how the new code looks like:
using System; using System.Collections.Generic; using System.Data.SqlClient; using System.Linq; using System.Text; using System.Threading.Tasks; namespace ConnectionPoolingExample1 { class Program { static void Main(string[] args) { using (SqlConnection connection = new SqlConnection(@"Server=.\SQL2K17;Database=SampleDB1;Trusted_Connection = yes")) { connection.Open(); } using (SqlConnection connection = new SqlConnection(@"Server=.\SQL2K17;Database=SampleDB2;Trusted_Connection = yes")) { connection.Open(); } using (SqlConnection connection = new SqlConnection(@"Server=.\SQL2K17;Database=SampleDB3;Trusted_Connection = yes")) { connection.Open(); } using (SqlConnection connection = new SqlConnection(@"Server=.\SQL2K17;Database=SampleDB1;Trusted_Connection = yes")) { connection.Open(); } using (SqlConnection connection = new SqlConnection(@"Server=.\SQL2K17;Database=SampleDB2;Trusted_Connection = yes")) { connection.Open(); } Console.ReadLine(); } } }
As you can see in the new code above, we have in total 5 SQL Server calls, but actually all our calls target again 3 databases (two connection requests call “SampleDB1” and two other connection requests call “SampleDB2”).
Let’s run the program (again without pressing “Enter” upon its execution) and check again Activity Monitor in SSMS:
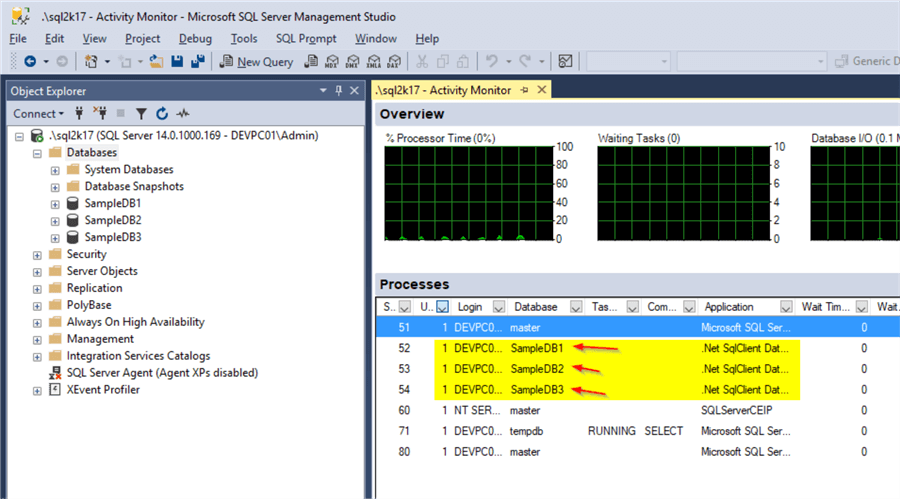
As you can see in the above screenshot, even though our application has just made 5 SQL Server connection requests, the actual sessions on SQL Server are only 3 and this is what ADO.NET connection pooling is all about!
Analysis and Conclusion
In this tip, we examined the power and usefulness of SQL Server Connection Pooling using ADO.NET. Via two simple C# programs, we made calls to SQL Server and saw how the connection pooler handled the connections in each case. We saw how the connection pooler reuses the already established connections when the connection strings are the same. This is a great functionality that significantly contributes towards more performant and robust .NET data applications.
In the first example, via our C# application, we made 3 SQL Server calls, each one against a different database (SampleDB1, SampleDB2 and SampleDB3). Since we used 3 different connection strings, the connection pooler could not reuse any connection because the connections were different.
However, in the second example, we made 5 SQL Server calls, from which there were two pairs of calls that targeted the same database. In that case, the connection pooler took action and served the 4th and 5th SQL Server connection requests with the connections it already had in cache. This resulted in serving all 5 connections with actually requiring only 3 sessions in SQL Server.
Some considerations about connection pooling:
- The pool is automatically cleared in the case the application’s execution is terminated. It can be also cleared manually with the use of the methods “ClearAllPools” and “ClearPool”.
- Always close the database connections in your code when finished, in order to allow the connection to return back to the pool (a good idea is to make use of the “using” statement in your database connection code blocks).
- The connection pooler removes connections from the pool after they have been idle for a few minutes, or in the case where they are no longer connected to SQL Server.
Connection pooling is very useful. Even though it works automatically in the background in .NET, it is also indirectly depended on the quality of data access code we write. Always try to reuse connection strings as much as possible, as well as close each database connection right after the database tasks are completed. By applying this practice, you will help connection pooler to handle your database connection needs faster and more efficiently, by reusing connections from the pool.
Next Steps
- Check out the tip Script to check SQL Server connection pooling
- Check out the tip How To Create an ADO.NET Data Access Utility Class for SQL Server
- Check the MS Docs article about SQL Server Connection Pooling






About the author
 Artemakis Artemiou is a Senior SQL Server and Software Architect, Author, and a former Microsoft Data Platform MVP (2009-2018).
Artemakis Artemiou is a Senior SQL Server and Software Architect, Author, and a former Microsoft Data Platform MVP (2009-2018).This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2018-08-09
