By: Eduardo Pivaral | Updated: 2022-08-31 | Comments (13) | Related: > TSQL
Problem
Sometimes you must perform DML processes (insert, update, delete or combinations of these) on large SQL Server tables. If your database has a high concurrency these types of processes can lead to blocking or filling up the transaction log, even if you run these processes outside of business hours. So maybe you were tasked to optimize some processes to avoid large log growths and minimize locks on tables. How can this be done?
Solution
We will do these DML processes using batches with the help of @@ROWCOUNT. This also give you the ability to implement custom “stop-resume” logic. We will show you a general method, so you can use it as a base to implement your own processes.
Please note that we will not focus on indexes on this tip, of course this can help queries, but I want to show you a worst-case scenario and index creation is another topic.
Basic algorithm
The basic batch process is something like this:
DECLARE @id_control INT
DECLARE @batchSize INT
DECLARE @results INT
SET @results = 1 --stores the row count after each successful batch
SET @batchSize = 10000 --How many rows you want to operate on each batch
SET @id_control = 0 --current batch
-- when 0 rows returned, exit the loop
WHILE (@results > 0)
BEGIN
-- put your custom code here
SELECT * -- OR DELETE OR UPDATE
FROM <any Table>
WHERE <your logic evaluations>
(
AND <your PK> > @id_control
AND <your PK> <= @id_control + @batchSize
)
-- very important to obtain the latest rowcount to avoid infinite loops
SET @results = @@ROWCOUNT
-- next batch
SET @id_control = @id_control + @batchSize
END
To explain the code, we use a WHILE loop and run our statements inside the loop and we set a batch size (numeric value) to indicate how many rows we want to operate on each batch.
For this approach, I am assuming the primary key is either an int or a numeric data type, so for this algorithm to work you will need that type of key. So for alphanumeric or GUID keys, this approach won't work, but you can implement some other type of custom batch processing with some additional coding.
So, with the batch size and the key control variable, we validate the rows in the table are within the range.
Important Note: Your process will need to always operate on at least some rows in each batch. If a batch does not operate on any rows, the process will end as row count will be 0. If you have a situation where only some rows from a large table will be affected, it is better and more secure to use the index/single DML approach. Another approach for these cases is to use a temporary table to filter the rows to be processed and then use this temp table in the loop to control the process.
Our example setup
We will use a test table [MyTestTable] with this definition:
CREATE TABLE [dbo].[MyTestTable]( [id] [bigint] IDENTITY(1,1) NOT NULL, [dataVarchar] [nvarchar](50) NULL, [dataNumeric] [numeric](18, 3) NULL, [dataInt] [int] NULL, [dataDate] [smalldatetime] NULL, CONSTRAINT [PK_MyTestTable] PRIMARY KEY CLUSTERED ( [id] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] ) ON [PRIMARY] GO
It contains random information and 6,000,000 records.
Executing a SELECT statement
Here we execute a simple SELECT statement over the entire table. Note, I enabled statistics IO and cleared the data cache first so we have better results for comparison.
DBCC DROPCLEANBUFFERS SET STATISTICS IO ON SELECT * FROM [dbo].[MyTestTable] WHERE dataInt > 600
These are the IO results:
The SELECT took 1:08 minutes and retrieved 2,395,317 rows.

SELECT Statement using batches
For the same SELECT we implement the following process to do it in batches:
DBCC DROPCLEANBUFFERS
SET STATISTICS IO ON
DECLARE @id_control INT
DECLARE @batchSize INT
DECLARE @results INT
SET @results = 1
SET @batchSize = 100000
SET @id_control = 0
WHILE (@results > 0)
BEGIN
-- put your custom code here
SELECT *
FROM [dbo].[MyTestTable]
WHERE dataInt > 600
AND id > @id_control
AND id <= @id_control + @batchSize
-- very important to obtain the latest rowcount to avoid infinite loops
SET @results = @@ROWCOUNT
-- next batch
SET @id_control = @id_control + @batchSize
END
The IO results (for each batch):
If we multiply it for 60 batches performed it should be around 65,500 logical reads (approximately the same as before, this makes sense since is the same data we are accessing).
But if we look at the overall execution time, it improves by around 10 seconds, with the same number of rows:
A SELECT statement is probably not the best way to demonstrate this, so let's proceed with an UPDATE statement.
UPDATE Statement using batches
We will do an UPDATE on a varchar field with random data (so our test is more real), after clearing the cache, we will execute the code.
This is a screenshot of the transaction log before the operation.

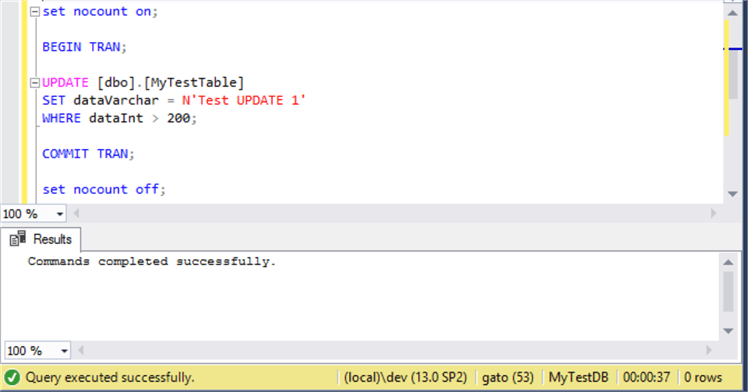
DBCC DROPCLEANBUFFERS BEGIN TRAN; UPDATE [dbo].[MyTestTable] SET dataVarchar = N'Test UPDATE 1' WHERE dataInt > 200; COMMIT TRAN;
The execution took 37 seconds on my machine.
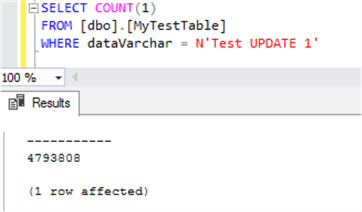
To find the rows affected, we perform a simple count and we get 4,793,808 rows:
SELECT COUNT(1) FROM [dbo].[MyTestTable] WHERE dataVarchar = N'Test UPDATE 1'
Checking the log size again, we can see it grew to 1.5 GB (and then released the space since the database is in SIMPLE mode):

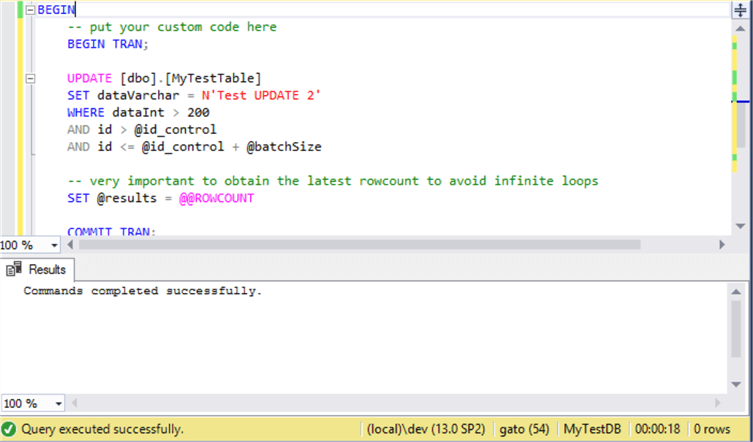
Let's proceed to execute the same UPDATE statement in batches. We will just change the text Test UPDATE 1 for Test UPDATE 2, this time using the batch process. I also shrunk the transaction log to its original size and perform a cache cleanup before executing.
DBCC DROPCLEANBUFFERS DECLARE @id_control INT DECLARE @batchSize INT DECLARE @results INT SET @results = 1 SET @batchSize = 1000000 SET @id_control = 0 WHILE (@results > 0) BEGIN -- put your custom code here BEGIN TRAN; UPDATE [dbo].[MyTestTable] SET dataVarchar = N'Test UPDATE 2' WHERE dataInt > 200 AND id > @id_control AND id <= @id_control + @batchSize -- very important to obtain the latest rowcount to avoid infinite loops SET @results = @@ROWCOUNT COMMIT TRAN; -- next batch SET @id_control = @id_control + @batchSize END
This time the query execution was 18 seconds, so there was an improvement in time.
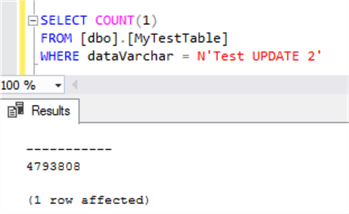
As we can see there was an improvement with the log spaced used. This time the log grew to 0.43 GB.

The last thing to verify is the number of rows affected. We can see we have the same row count as the UPDATE above, 4,793,808 rows.
As you can see, for very large DML processes, running in smaller batches can help on execution time and transaction log use.
The only drawback of this method is that your key must be a sequential number and there must ne at least one row in each batch, so the process does not end before being applied to all data.
Handling transactions and errors
Imagine your process involves complex validations, complex calculations and multiple tables for each batch iteration, to handle potential issues we can use a BEGIN – COMMIT transaction on each batch, but if not implemented properly, and if any error happens on a batch run, it can leave your system unresponsive or running in a forever loop.
A good approach I like to use on error handling and transaction management for each batch is this one, taking one table from WideWorldImporters demo database:
(I purposely made a division by zero so the batch will fail, this is for demonstration purposes.)
SET XACT_ABORT ON;
USE [WideWorldImporters]
DECLARE @id_control INT
DECLARE @batchSize INT
DECLARE @results INT
SET @results = 1 --stores the row count after each successful batch
SET @batchSize = 100 --How many rows you want to operate on each batch
SET @id_control = 0 --current batch
-- when 0 rows returned, exit the loop
WHILE (@results > 0)
BEGIN
BEGIN TRY
BEGIN TRAN
UPDATE [Sales].[Invoices]
SET [TotalChillerItems] = 1/0
WHERE [TotalDryItems] > 1
AND [InvoiceID] > @id_control
AND [InvoiceID] <= @id_control + @batchSize
-- very important to obtain the latest rowcount to avoid infinite loops
SET @results = @@ROWCOUNT
COMMIT TRAN
END TRY
BEGIN CATCH
IF @@TRANCOUNT >= 1
BEGIN
THROW 51000, 'User defined error, on this case divide by zero', 1;
ROLLBACK TRAN
BREAK;
END
SET @results = 0; -- failsafe so we can exit loop if any other issue ocurrs
END CATCH
-- next batch
SET @id_control = @id_control + @batchSize
END
Explaining the code:
The process implemented for batch processing is the same we discussed before, but we added a few things:
- XACT_ABORT ON: We use this to rollback any unhandled transaction if the TRY..CATCH is not able to capture it. According to Microsoft Documentation, there are some errors that are not captured by it.
- TRY..CATCH block: it will help us catch any error that could happen in our batch process (duplicated key, invalid datatype, NULL insert, etc.) and the CATCH block will allow us to take different actions as we require. The last line of code I like to put inside the CATCH block is assigning the @results parameter 0, so in case we have an unhandled exception (something we did not consider) it will act as a failsafe and avoid entering the WHILE loop again.
- BEGIN..COMMIT TRAN: This section is inside the TRY block and will help us to commit or discard the batch if we work with multiple tables, or multiple statements.
- ROLLBACK TRAN: This occurs in the CATCH block, if any issue happens, we first validate that the transaction count is greater or equal to zero, then we can throw a single, generic error or validate other rules and flags and be as descriptive as we want. Then we rollback any open transaction and finally we break the WHILE loop in case needed.
If we execute this code block, we can see that the error is properly caught and thrown and the batch is finished:
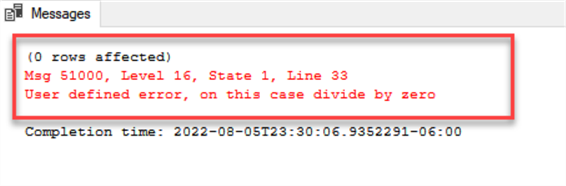
Note that this error handling method should only be used as a base and you must implement other options such as logging, retry-on-error logic, or more complex logic you need to make a robust process, especially if you need to implement it on a system that runs regularly (for example ETL loads or processes).
Next Steps
- You can determine if your process can use this batch method just running the SELECT statements and comparing the number of expected rows with the results.
- You can increase/decrease the batch size to suit your needs, but for it to have meaning the batch size must be less than 50% of the expected rows to be processed.
- This process can be adapted to implement a “stop-retry” logic so already processed rows can be skipped if you decide to cancel the execution.
- It also supports multi-statement processes (in fact, this is the real-world use of this approach) and you can achieve this with a “control” table having all the records to work with and update accordingly.
- If you want to implement an “execution log” you can achieve this by adding PRINT statements. Just now that this could slow down some processes, especially for very small batch sizes.






About the author
 Eduardo Pivaral is an MCSA, SQL Server Database Administrator and Developer with over 15 years experience working in large environments.
Eduardo Pivaral is an MCSA, SQL Server Database Administrator and Developer with over 15 years experience working in large environments. This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2022-08-31
