By: Koen Verbeeck | Updated: 2018-08-17 | Comments (4) | Related: 1 | 2 | 3 | 4 | More > Integration Services Development
Problem
In the first part we introduced the reasoning behind type 2 slowly changing dimensions. We also discussed different implementation options in Integration Services (SSIS). Finally, we started with an implementation in the data flow using out-of-the-box transformations only, so we can build an optimized data flow for loading a type 2 dimension. In this tip, we’ll continue the implementation.
Solution
In the first part of the tip we ended with a data flow where we checked if a row was an insert or an update using the lookup component. If you haven’t read the first part yet, it’s recommended to do so.
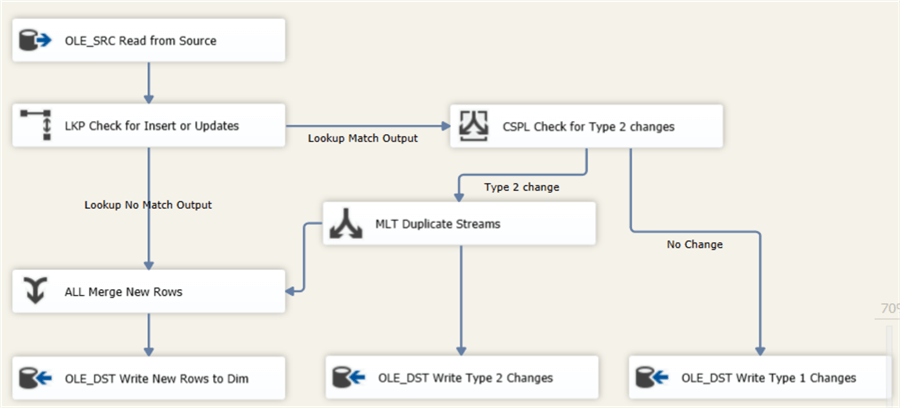
For the updated rows, we’re going to verify if a row has columns that have changed compared with the most recent row of that business key. First, we’re going to check for type 2 changes. If a type 2 change has occurred, a new row will be inserted and the previous version will get a timestamp for the ValidTo column, to indicate how long that version was valid in time.
Add a conditional split to the data flow canvas and connect it with the match output of the lookup component.
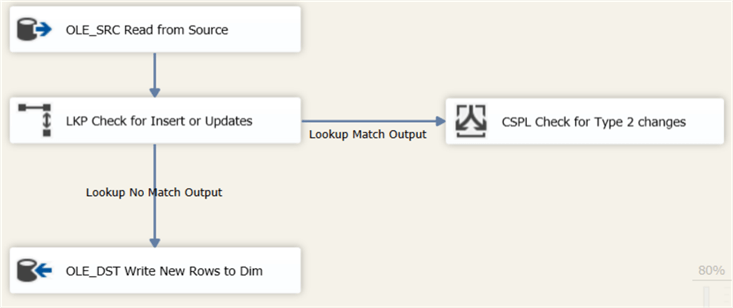
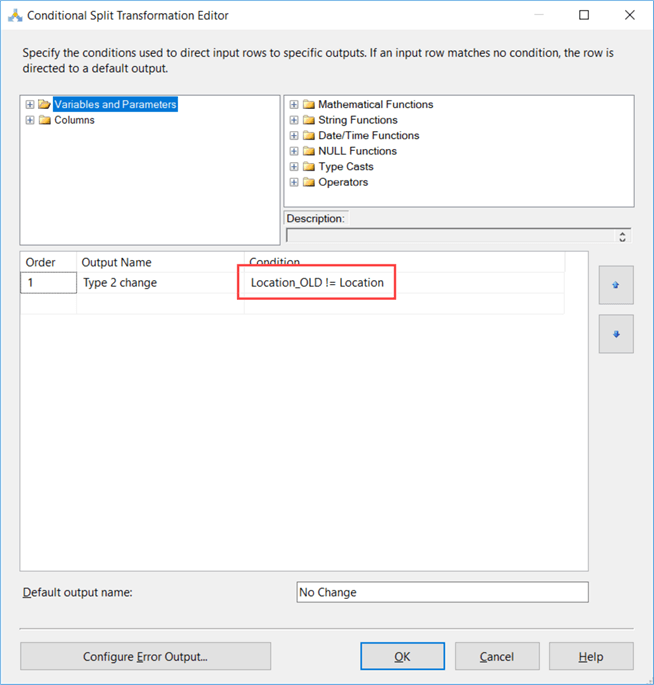
In the condition, we check if the new value of the field Location is different from the current value (which was retrieved in the lookup):
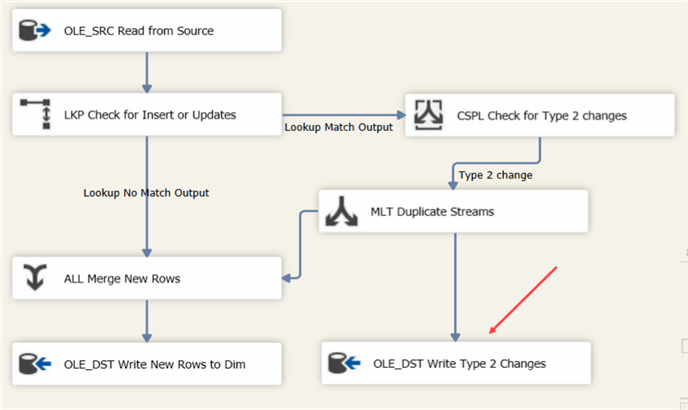
If a change has occurred, a new row has to be inserted into the dimension. But at the same time, we also need to update the previous version. To solve this issue, we’ll use a multicast to create two copies of the row. One we’ll send to the OLE DB Destination, the other to an update. We’re going to reuse the OLE DB Destination that inserts new rows into the dimension. To do this, we place a UNION ALL to merge the two streams together.
The data flow looks like this:
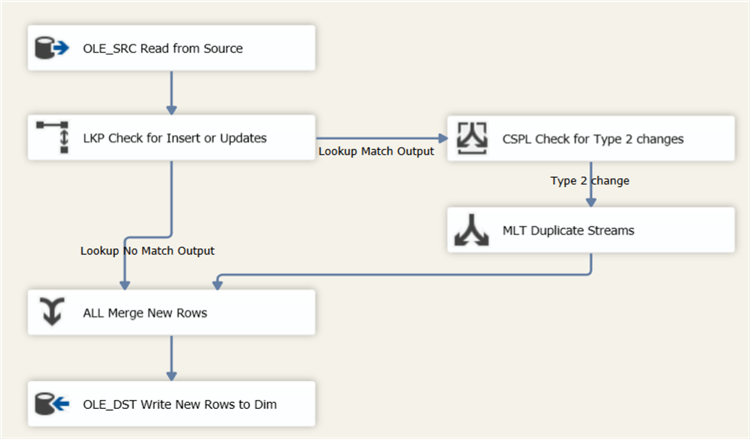
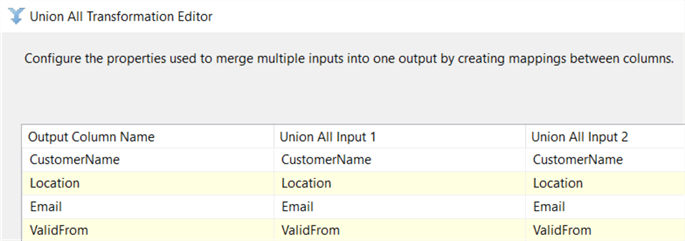
The UNION ALL component has the following configuration:
The insert of new rows is now covered in the data flow. We’re still left with the updates though. There are two types of updates:
- Updating the ValidTo field of the previous version when a Type 2 field has occurred
- Updating all other fields when Type 1 changes have occurred
When using the SCD Type 2 wizard in SSIS, the OLE DB Command is used to issue the updates against the database. The problem with this transformation is that an update is sent to the database for every single row. This puts a burden on the transaction log and is much slower than a single batch update. For large dimensions, this can cause performance issues. To work around this, we’ll create two tables. The following T-SQL is used:
DROP TABLE IF EXISTS [dbo].[UPD_DimCustomer_SCD2]; CREATE TABLE [dbo].[UPD_DimCustomer_SCD2]( [SK_Customer] [int] NOT NULL, [ValidFrom] [date] NOT NULL ); DROP TABLE IF EXISTS [dbo].[UPD_DimCustomer_SCD1]; CREATE TABLE [dbo].[UPD_DimCustomer_SCD1]( [CustomerName] [VARCHAR](50) NOT NULL, [Email] [varchar](50) NULL );
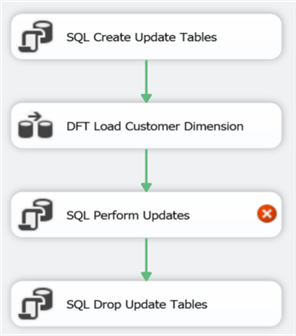
Keep in mind that DROP TABLE IF EXISTS is only valid since SQL Server 2016. These T-SQL statements are executed in an Execute SQL Task right before the data flow task.
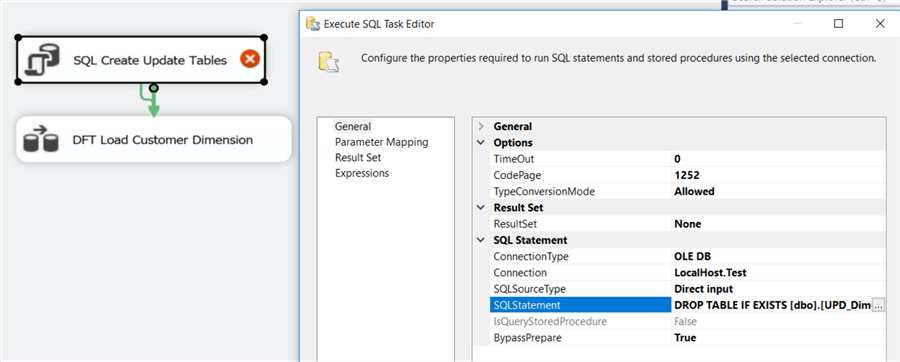
After the data flow task, another Execute SQL Task can be added to drop the update tables, as some sort of clean-up. While debugging, it might be interesting not to drop these tables as you might want to inspect their contents.
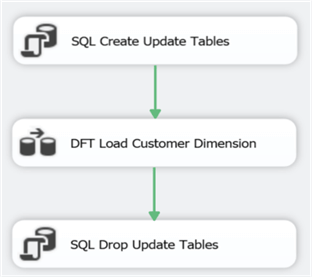
To make sure this pattern works, you have to set the DelayValidation property of the data flow to True. If not, the data flow will fail validation because the update tables won’t exist yet when the package starts. Let’s continue with the data flow. Add another OLE DB Destination to write the type 2 changes to the dbo.UPD_DimCustomer_SCD2 table:
Here we’ll map the surrogate key retrieved from the lookup and the ValidFrom field:
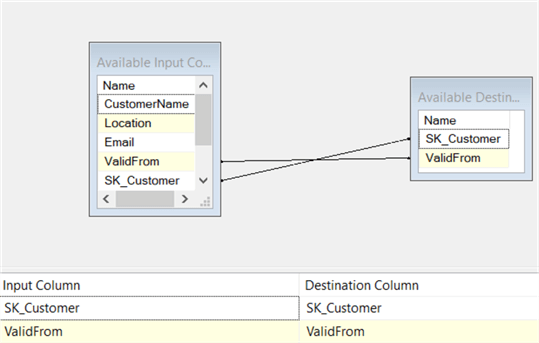
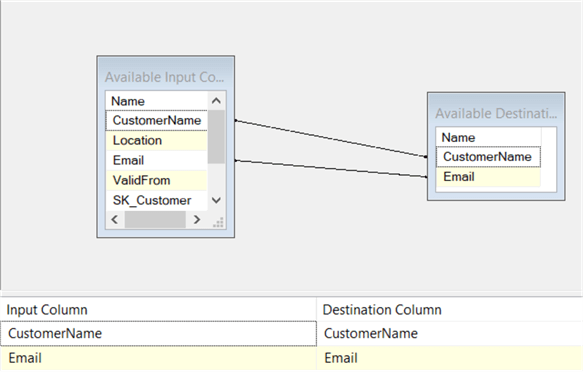
Finally, add a third OLE DB Destination to write the type 1 changes to the dbo.UPD_DimCustomer_SCD1 table.
In the mapping pane, the business key of the dimension – CustomerName – and all type 1 fields of the dimension are mapped to the update table.
The data flow is now finished. The last step is now configuring the updates. Add an Execute SQL Task between the data flow and the last Execute SQL Task:
First, we need a T-SQL update statement that sets the ValidTo field of the previous version of a row:
UPDATE d SET [ValidTo] = DATEADD(DAY,-1,[u].[ValidFrom]) FROM [dbo].[DimCustomer] d JOIN [dbo].[UPD_DimCustomer_SCD2] u ON [u].[SK_Customer] = [d].[SK_Customer];
Because we join on the surrogate key, this update statement will have good performance since this column is typically the primary key of the dimension (and thus has a clustered index on it when the defaults were followed).
The ValidTo field is set to one day prior to the ValidFrom field.
Next, we update the type 1 columns using the business key:
UPDATE d SET [Email] = u.[Email] FROM dbo.[DimCustomer] d JOIN dbo.[UPD_DimCustomer_SCD1] u ON u.[CustomerName] = d.[CustomerName] WHERE ISNULL(d.[Email],’’) <> ISNULL(u.[Email],’’);
Here we join on the business key. Ideally, a unique index is placed on the business key columns to enforce uniqueness. Therefore, this update statement should have good performance as well. To minimize the number of updates, we also check if the value for email has changed it all. To take NULL values into account, we wrap both columns in an ISNULL function. If the column is not nullable, this isn’t necessary of course.
Testing the Package
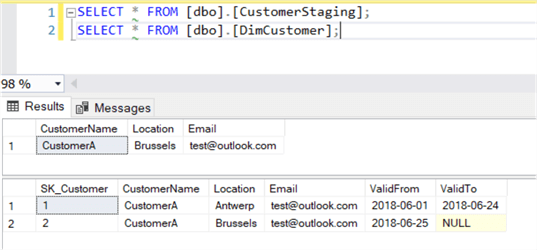
The package is now finished, so let’s test some scenarios. Currently, the following data is in the staging table and in the dimension:
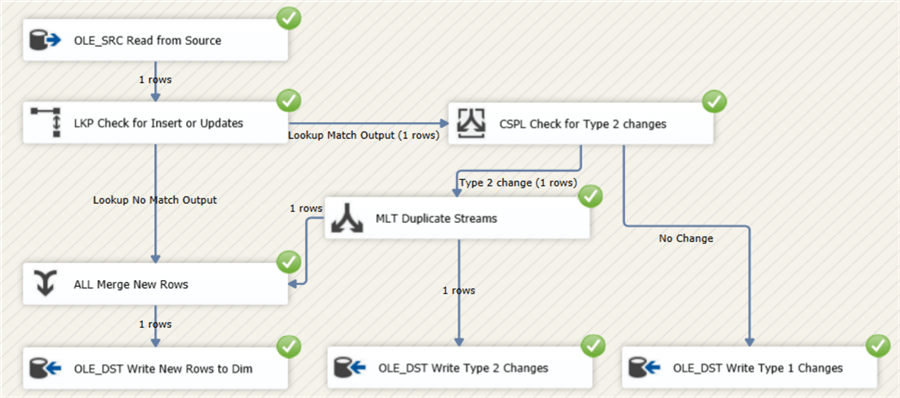
Let’s change the location to California in the staging table, triggering a type 2 change. The data flow looks like this when running the package:
The data in the tables:
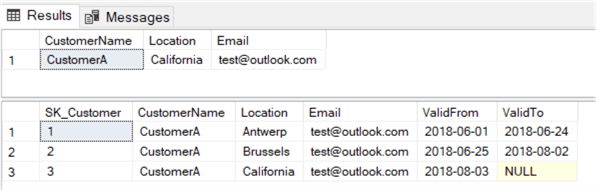
The package was run on the 4th of August. This means ValidFrom is the 3rd of August, since we fetch data that is valid until the previous day (since typically batch ETL runs are executed at night). You can change this depending on your business logic. The ValidTo field of the previous version (SK_Customer = 2) is set to one day prior, the 2nd of August.
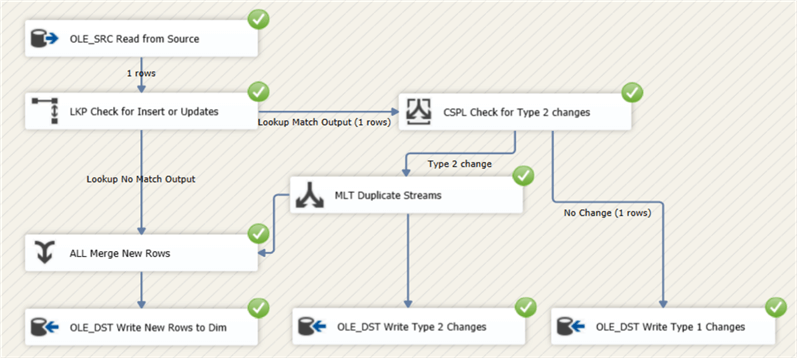
Let’s make a type 1 change by changing the email address. Running the data flow results in the following:
The data in the tables:
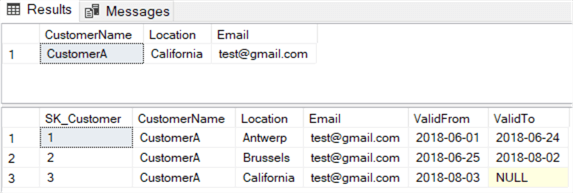
As you can see, the email is updated for every version.
Conclusion
In this part we finalized the design of the SSIS package that loads a Type 2 slowly changing dimension. However, there are still some optimizations possible:
- Currently we always update type 1 fields, even when there is no actual change. There’s a check in the T-SQL update statement, but this is after we’ve written all the rows to the temporary table.
- Detecting updates can be made more efficient by using hashes.
- What about intra-day changes?
In the next part of the tip, we’ll cover each of those scenarios.
Next Steps
- Make sure to read part 1 of this tip series.
- If you want to know more about implementing slowly changing dimensions in SSIS, you can check out the following tips:
- You can find more SSIS development tips in this overview.






About the author
 Koen Verbeeck is a seasoned business intelligence consultant at AE. He has over a decade of experience with the Microsoft Data Platform in numerous industries. He holds several certifications and is a prolific writer contributing content about SSIS, ADF, SSAS, SSRS, MDS, Power BI, Snowflake and Azure services. He has spoken at PASS, SQLBits, dataMinds Connect and delivers webinars on MSSQLTips.com. Koen has been awarded the Microsoft MVP data platform award for many years.
Koen Verbeeck is a seasoned business intelligence consultant at AE. He has over a decade of experience with the Microsoft Data Platform in numerous industries. He holds several certifications and is a prolific writer contributing content about SSIS, ADF, SSAS, SSRS, MDS, Power BI, Snowflake and Azure services. He has spoken at PASS, SQLBits, dataMinds Connect and delivers webinars on MSSQLTips.com. Koen has been awarded the Microsoft MVP data platform award for many years.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2018-08-17
