By: Dinesh Asanka | Updated: 2018-08-28 | Comments | Related: > Indexing
Problem
In SQL Server there are several types of indexes like: clustered, non-clustered and columnstore indexes (columnstore was added in SQL Server 2012). However, creation of indexes and usage of indexes are not known to many users and there are lot of myths around indexes. This article explains the behavior of clustered indexes with the help of looking at execution plans.
Solution
To explain this, the Sales. SalesOrderDetail table from the AdventureWorks2012 database was used. Following is the table structure for the Sales.SalesOrderDetail table.
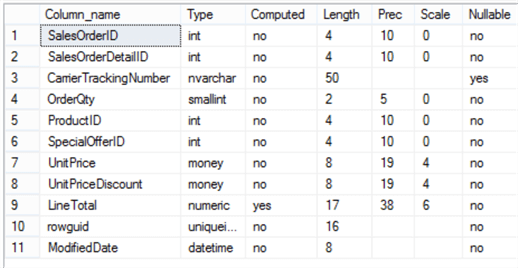
This table has three indexes.

As shown above, there is a clustered index named PK_SalesOrderDetail_SalesOrderID_SalesOrderDetailsID which contains the SalesOrderID and SalesOrderDetailID columns.
Following is sample set of data in the Sales.SalesOrderDetail table.
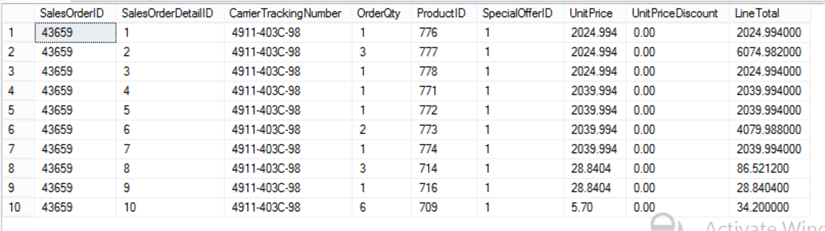
Scenario 1 - SQL Server Select Test
The first test will do a simple SELECT using both parts of the clustered index key to see how the query behaves and we will look at the execution plans.
--Query 1 SELECT SalesOrderID, SalesOrderDetailID FROM Sales.SalesOrderDetail WHERE SalesOrderID = 58950 --Query 2 SELECT SalesOrderID, SalesOrderDetailID FROM Sales.SalesOrderDetail WHERE SalesOrderDetailID = 68531
In the above two queries, the same columns are selected from the same table and the only difference is the column used in the WHERE clause.
In the first query SalesOrderID is used in the WHERE clause and in the second query SalesOrderDetailID is used in the WHERE clause. The first query returns 28 records and the second query returns one record. So, the question is what performs better.
Below we can see the query plans for the two queries.
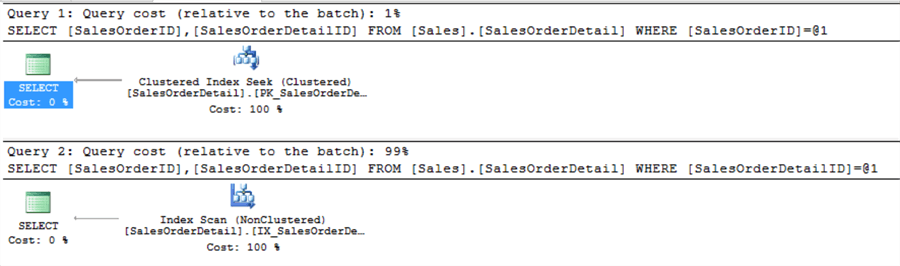
Without much analysis, from the execution plans we can see the relative cost of the first query is 1% where the second query is 99%. When further analysis is done, it can be observed that the first query does an index seek on the clustered index and the second query does an index scan on the non-clustered index. In this scenario, the non-clustered index scan was used because it is faster to scan than scanning the clustered index. The reason it just uses the non-clustered index is that the non-clustered index includes the clustered key (SalesOrderID and SalesOrderDetailID) which are the two columns used in the query. Each non-clustered index includes the key of the clustered index which is the pointer to the get the rest of the data in the clustered index.
Let's compares the clustered index to a paper telephone directory. In a telephone directory, data is indexed by Last Name and First Name. Let's assume you need to search for “Robin Hood” where the first name is Robin and the second name is Hood. If you are asked to do two searches, the first search for First Name = Robin and the second search Last Name = Hood, it is easy to say that searching for Last Name = Hood from the telephone directory will be much faster since it is indexed by Last Name and First Name. In the case of searching for First Name = Robin, you have no choice but to search the entire directory or at least until you find the entry you are looking for.
Since SalesOrderDetail table has a clustered index which contains columns SalesOrderID and SalesOrderDetailID, the first query searches for SalesOrderID and the second query searches for SalesOrderDetailID. The first query will be able to use the index and perform a seek, but the second query needs to scan the entire table until it finds the matching value.
An important aspect of this scenario is to note that the number of records returned does not have a direct correlation to the performance of the queries, as in this case the better performing query is the query which returns more rows.
Scenario 2 - SQL Server Select Test with Different WHERE Clauses
Let's look at another scenario as shown below.
-- Using full index --Query 1 SELECT SalesOrderID, SalesOrderDetailID FROM Sales.SalesOrderDetail WHERE SalesOrderDetailID = 68531 --Query 2 SELECT SalesOrderID, SalesOrderDetailID FROM Sales.SalesOrderDetail WHERE SalesOrderID = 58950 AND SalesOrderDetailID = 68531
In the above two queries, both queries will return the same row. In these queries, the only difference is that WHERE clause for query 1 has one parameter and the second query has two parameters. If we refer back to the previous example of “Robin Hood”, we can ask what is easier? Searching by “Robin” or (“Robin” AND “Hood”). Considering the fact the index is on Last Name and First Name, it is easy to say that (“Robin” AND “Hood”) is a better performing search.
Let's examine the query execution plans.
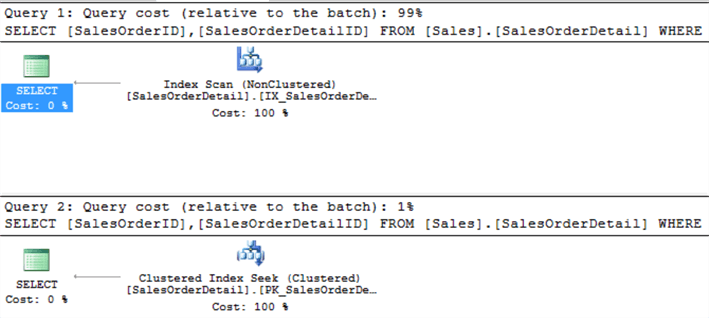
The query execution plans confirm that when the index is fully covered it is performing better. This breaks the myth of some users who think that when the WHERE clause is complex the query performance will be worse.
Scenario 3 - SQL Server Select Test with Varying WHERE Clauses
Let's look at another scenario as shown below.
-- Changing the Where clause order --Query 1 SELECT SalesOrderID, SalesOrderDetailID FROM Sales.SalesOrderDetail WHERE SalesOrderID = 43683 AND SalesOrderDetailID = 240 --Query 2 SELECT SalesOrderID, SalesOrderDetailID FROM Sales.SalesOrderDetail WHERE SalesOrderDetailID = 240 AND SalesOrderID = 43683
In the above two queries, the only difference is the order of the WHERE clause. Many users believe that the WHERE clause should have the same order as the index column order.
Let's verify this with the query execution plans.
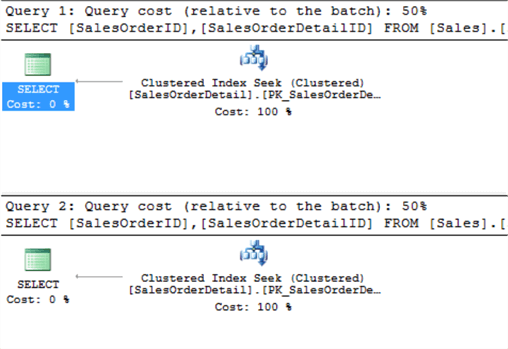
The query execution plan confirms that the relative cost of both queries is 50% and the query plan is the same for both queries which means the order of WHERE clause does not matter.
Scenario 4 - SQL Server Select Test with AND vs. OR Logic
Let's look at another scenario as shown below.
-- Difference between AND and OR --Query 1 SELECT SalesOrderID, SalesOrderDetailID FROM Sales.SalesOrderDetail WHERE SalesOrderID = 43683 AND SalesOrderDetailID = 240 --Query 2 SELECT SalesOrderID, SalesOrderDetailID FROM Sales.SalesOrderDetail WHERE SalesOrderID = 43683 OR SalesOrderDetailID = 240
In this scenario, it is the same query but the only change is the AND /OR combination in the WHERE clause. If you refer back to the Robin Hood example, is it easier to find (Robin and Hood) or (Robin OR Hood). Well, to find (Robin OR Hood) you have no choice but to scan through the entire directory.
Let's confirm this with the query execution plans.
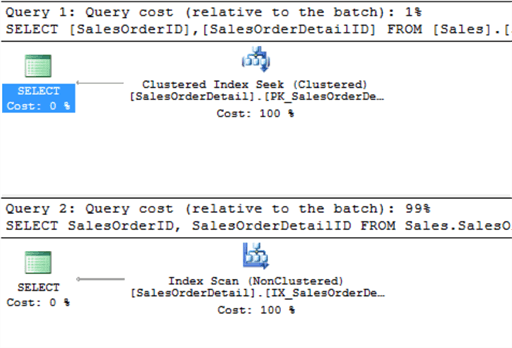
The above execution plans confirm that the query with OR is worse performing than the query with AND.
Scenario 5 - SQL Server Select Test with Varying Columns
Let's look at another scenario as shown below.
-- Different Columns --Query 1 SELECT SalesOrderID, SalesOrderDetailID, CarrierTrackingNumber FROM Sales.SalesOrderDetail WHERE SalesOrderID = 43683 AND SalesOrderDetailID = 240 --Query 2 SELECT SalesOrderID, SalesOrderDetailID FROM Sales.SalesOrderDetail WHERE SalesOrderID = 43683 AND SalesOrderDetailID = 240
In this query, the only change is the additional column in the SELECT. It is easier to make a conclusion that since the query has to retrieve more columns in the first query, the first query would perform worse.
Let's examine the query execution plans.
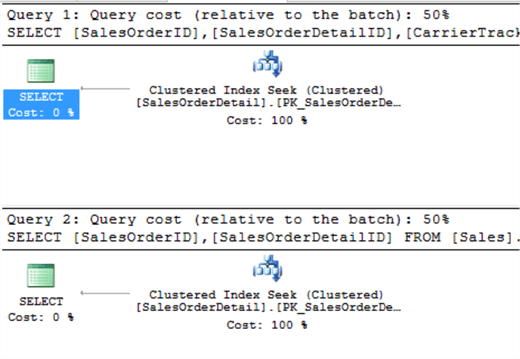
We can see the query plans are similar and the cost is also same. It is important to remember that SalesOrderId, SalesOrderDetailID make up the clustered index, so when additional columns are requested from the clustered index there is no additional overhead. In the case of the non-clustered index things would have been different, since a lookup would need to occur to get the additional columns from the clustered index.
Next Steps
- Please go through these scripts and execute them to see how data access works with a clustered index.
- Read details on indexes at https://docs.microsoft.com/en-us/sql/relational-databases/indexes/clustered-and-nonclustered-indexes-described?view=sql-server-2017






About the author
 Dinesh Asanka is a 10 time Data Platform MVP and frequent speaker at local and international conferences with more than 12 years of database experience.
Dinesh Asanka is a 10 time Data Platform MVP and frequent speaker at local and international conferences with more than 12 years of database experience.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2018-08-28
