By: Aaron Bertrand | Updated: 2018-09-06 | Comments | Related: > Performance Tuning
Problem
Table variables were introduced in SQL Server 2000 to help alleviate the recompilations that came with #temp tables – a problem that is less prevalent in modern versions, but still exists. There is a common misconception that table variables avoid I/O, since people believe they are memory resident while #temp tables are not, but this is not true – both table variables and #temp tables will write to tempdb when necessary.
Table variables are great for small result sets, since they avoid these recompilations, and also because they do not have statistics that SQL Server has to maintain. But the latter point is a double-edged sword: the more rows in the table variable, the worse decisions the optimizer may make. Without statistics to check, it always assumes there is only one row (actually, zero, rounded up), and sometimes these assumptions are tragic. Performing a join involving a table variable can lead to a very bad plan strategy if SQL Server thinks there can only be one unique, matching row when, in fact, there may be thousands or more, including duplicates.
Solution
Microsoft has mitigated this problem in the past with trace flag 2453, which can trigger a recompile when enough rows have changed. I blogged about trace flag 2453 back in 2014, and Ahmad Yaseen talked about it in a previous tip, but let’s take a quick look at how it can help. I created the following view on a SQL Server 2017 instance:
CREATE VIEW dbo.Congruence AS SELECT m1.number, m1.name FROM master.dbo.spt_values AS m1 CROSS JOIN (SELECT TOP 100 number FROM master.dbo.spt_values) AS m2;
This view holds 231,800 rows on my system; YMMV.
Now, we have a stored procedure that pulls rows from the view based on a pattern in the name, inserts them into a table variable, and then joins that table variable to a system catalog view:
CREATE PROCEDURE dbo.GetNamesByPattern
@Pattern sysname = N'%'
AS
BEGIN
DECLARE @t table (id int, name sysname);
INSERT @t(id,name)
SELECT number, name
FROM dbo.Congruence
WHERE name LIKE @Pattern;
SELECT t.id,t.name FROM @t AS t
INNER JOIN sys.all_objects AS o
ON t.id = o.object_id
WHERE o.modify_date >= '20000101';
END
Now, let’s call this procedure with three different name patterns – the default % (all rows), contains S, and starts with Q:
ALTER DATABASE SCOPED CONFIGURATION CLEAR PROCEDURE_CACHE; EXEC dbo.GetNamesByPattern @Pattern = N'%'; EXEC dbo.GetNamesByPattern @Pattern = N'%S%'; EXEC dbo.GetNamesByPattern @Pattern = N'Q%';
Using the free SentryOne Plan Explorer, we can quickly examine the estimated and actual rows that come back for each query against the table variable:
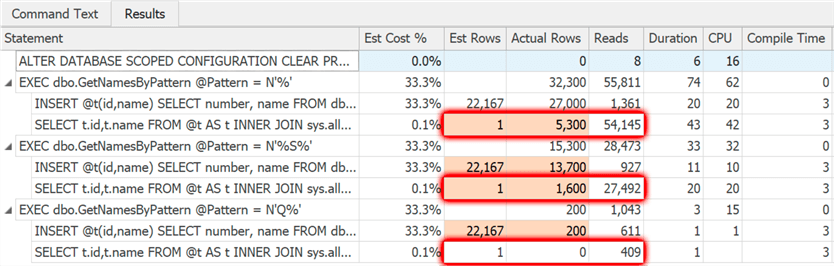
As you can see, the default behavior in current versions of SQL Server is to estimate that a single row will come out of that table variable, no matter how many rows are actually there. Take note of the reads, too, as this is a reflection of the plan choice that was made based on that one row guess, and will be interesting to compare in a moment.
Now, let’s call the stored procedure with trace flag 2453 running:
ALTER DATABASE SCOPED CONFIGURATION CLEAR PROCEDURE_CACHE; DBCC TRACEON(2453, -1); EXEC dbo.GetNamesByPattern @Pattern = N'%'; EXEC dbo.GetNamesByPattern @Pattern = N'%S%'; EXEC dbo.GetNamesByPattern @Pattern = N'Q%'; DBCC TRACEOFF(2453, -1);
The results this time:
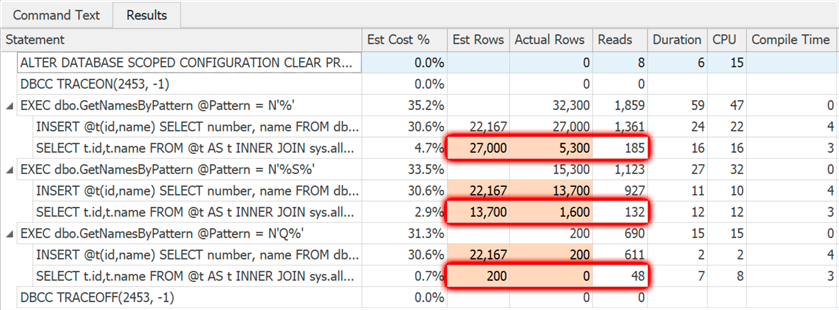
Between executions, the difference in rows in the table variable is enough that a recompile is triggered and, as a result, you get a more accurate estimate for what’s going to come out of the table variable. It’s wrong, of course, but that’s because the hash or merge join used in each case is off. Still, it’s way less wrong than the previous batch, and notice how there are so much fewer reads going on – this is due to a more sane plan choice.
To check what happens with OPTION (RECOMPILE), let’s create a copy of the procedure:
CREATE PROCEDURE dbo.GetNamesByPattern_OptionRecompile @Pattern sysname = N'%' AS BEGIN DECLARE @t table (id int, name sysname); INSERT @t(id,name) SELECT number, name FROM dbo.Congruence WHERE name LIKE @Pattern; SELECT t.id,t.name FROM @t AS t INNER JOIN sys.all_objects AS o ON t.id = o.object_id WHERE o.modify_date >= '20000101' OPTION (RECOMPILE); END
Then we’ll call the batch again, without the trace flag:
ALTER DATABASE SCOPED CONFIGURATION CLEAR PROCEDURE_CACHE; EXEC dbo.GetNamesByPattern_OptionRecompile @Pattern = N'%'; EXEC dbo.GetNamesByPattern_OptionRecompile @Pattern = N'%S%'; EXEC dbo.GetNamesByPattern_OptionRecompile @Pattern = N'Q%';
Nearly identical results:
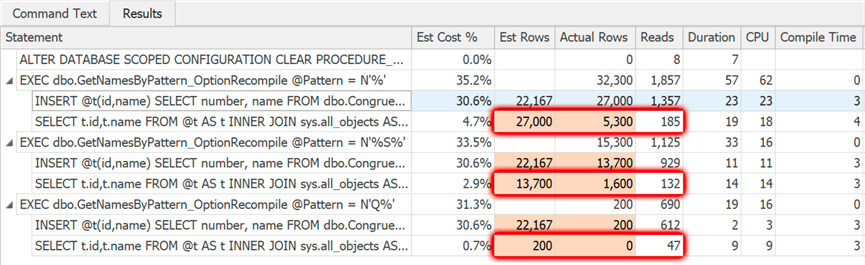
This is because, with the trace flag, we happened to trigger a recompile every time based on reaching row change thresholds, and now we are telling SQL Server to just do it every time. Hold onto that thought.
In Azure SQL Database, under compatibility level 150, there is a new feature (under preview at the time of writing) that simulates the behavior of trace flag 2453, with the benefit of not having to run under a trace flag, or adding OPTION (RECOMPILE) to queries. The feature is called Table Variable Deferred Compilation, and the implementation is to delay initial compilation until after the table variable has been populated the first time.
Because I need to test this on an Azure SQL Database system without access to things like the master database, I had to create my own tables and views to represent master..spt_values and sys.all_objects. On the system above I ran:
SELECT m1.number, m1.name INTO dbo.Congruence FROM master.dbo.spt_values AS m1 CROSS JOIN (SELECT TOP 100 number FROM master.dbo.spt_values) AS m2; SELECT * INTO dbo.sysallobjects FROM sys.all_objects;
Then I generated create table and insert statements and ran them on an Azure SQL Database system, along with:
ALTER DATABASE CURRENT SET COMPATIBILITY_LEVEL = 150;
This will change the reads slightly because I haven’t brought all the columns and indexes from both objects, but I wanted accurate row counts. (In hindsight, I should have performed the select into operations first and just used those tables in both systems, or using AdventureWorks, but quite honestly, at this point I didn’t feel like re-doing the screen shots.)
Now the stored procedure looks slightly different:
CREATE PROCEDURE dbo.GetNamesByPattern @Pattern sysname = N'%' AS BEGIN DECLARE @t table (id int, name sysname); INSERT @t(id,name) SELECT number, name FROM dbo.Congruence WHERE name LIKE @Pattern; SELECT t.id,t.name FROM @t AS t INNER JOIN dbo.sysallobjects AS o ON t.id = o.object_id WHERE o.modify_date >= '20000101'; END
And when we run that first batch again, here are the results:
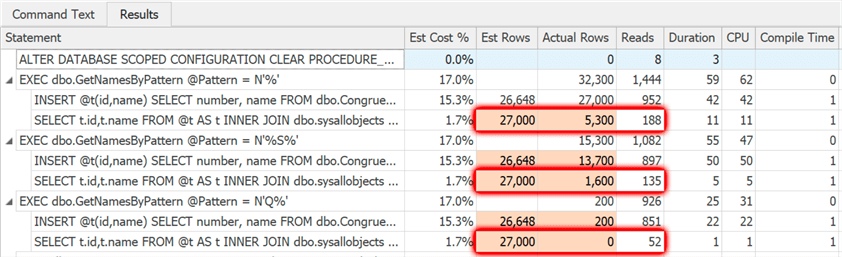
On the plus side, the first execution is way better than the default behavior in current versions, without running under a trace flag or adding hints to the query. The estimate of 27,000 rows is based on something real instead of this arbitrary guess of one row. However, subsequent executions simply reuse that original estimate, to avoid the cost of recompiling every time. Not that disastrous here, when the original strategy was based on expecting all rows.
What happens when the original strategy for the first compilation is based on a much lower row count? This is easy to simulate with the following batch:
ALTER DATABASE SCOPED CONFIGURATION CLEAR PROCEDURE_CACHE; EXEC dbo.GetNamesByPattern @Pattern = N'%NQRGT%'; EXEC dbo.GetNamesByPattern @Pattern = N'%S%'; EXEC dbo.GetNamesByPattern @Pattern = N'Q%';
Results this time tell a much different story:
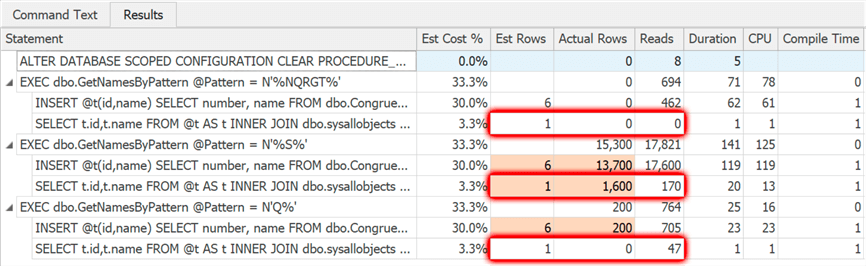
All executions now revert to the low estimate from the first execution. The second execution – where virtually no rows were expected but over 13,000 were returned – leads to an unacceptable number of reads and unpredictable performance as a result. If we add OPTION (RECOMPILE) to both statements in the procedure:
ALTER PROCEDURE dbo.GetNamesByPattern
@Pattern sysname = N'%'
AS
BEGIN
DECLARE @t table (id int, name sysname);
INSERT @t(id,name)
SELECT number, name FROM dbo.Congruence
WHERE name LIKE @Pattern OPTION (RECOMPILE);
SELECT t.id,t.name FROM @t AS t
INNER JOIN dbo.sysallobjects AS o
ON t.id = o.object_id
WHERE o.modify_date >= '20000101' OPTION (RECOMPILE);
END
And then run both batches again:
ALTER DATABASE SCOPED CONFIGURATION CLEAR PROCEDURE_CACHE; EXEC /* first exec: all rows */ dbo.GetNamesByPattern @Pattern = N'%'; EXEC dbo.GetNamesByPattern_OptionRecompile @Pattern = N'%S%'; EXEC dbo.GetNamesByPattern_OptionRecompile @Pattern = N'Q%'; ALTER DATABASE SCOPED CONFIGURATION CLEAR PROCEDURE_CACHE; EXEC /* first exec = 6 rows */ dbo.GetNamesByPattern @Pattern = N'%NQRGT%'; EXEC dbo.GetNamesByPattern_OptionRecompile @Pattern = N'%S%'; EXEC dbo.GetNamesByPattern_OptionRecompile @Pattern = N'Q%';
Results:
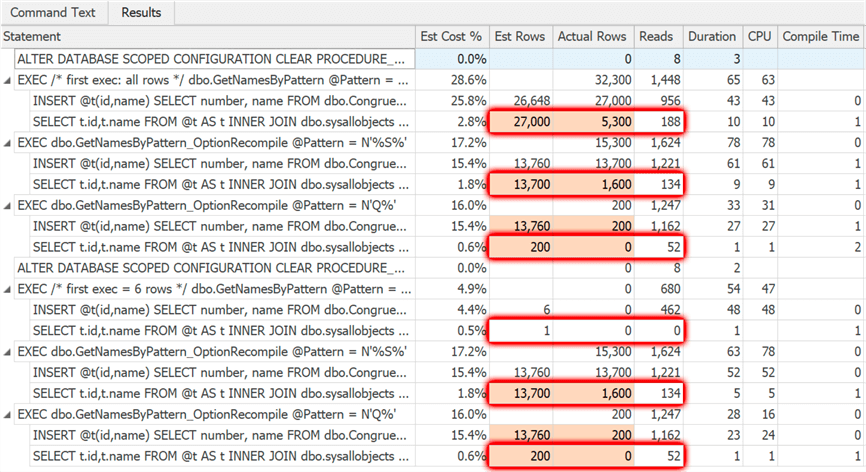
Now our plan strategies are at least reasonable. Our guesses are still way off; with other tuning, we could perhaps make some of these estimates more accurate. But first and subsequent executions are based on real cardinality in the table variable, and aren’t impacted by choices made in the first execution. In any case, this is the same or better overall than:
- the original behavior (worse – unless table variable always has low row counts)
- trace flag 2453 (roughly the same)
- OPTION (RECOMPILE) alone (roughly the same – if compilation costs are reasonable)
- compatibility level 150 alone (worse – if row counts fluctuate greatly)
…at least for this workload, with fluctuating row counts in the table variable, and relatively simple queries that don’t have a high compile cost.
You’ll have to test the impact on your workload to see where the trade-offs pay off the best – it might be that more accurate estimates are worth higher compile times, or it may be that the worst possible plan provides acceptable performance, or it may be that you want to consider using #temp tables instead of table variables.
Summary
In Azure SQL Database, and hopefully in the next version of SQL Server, you will get some inherent help in getting better cardinality estimates for table variables, at least under compatibility level 150 and above. If you have table variables that get populated with a relatively consistent number of rows, this new functionality will allow you to enjoy better estimates without the trace flag or the cost of recompiling every time. However, if your table variable size fluctuates greatly, and your queries don’t cause high compilation times, you should consider the combination of the new functionality coupled with OPTION (RECOMPILE).
Next Steps
Read on for related tips and other resources:
- Improve SQL Server Table Variable Performance Using Trace Flag 2453
- Improving SQL Server performance when using table variables
- New Trace Flag to Fix Table Variable Performance
- Public Preview of Table Variable Deferred Compilation in Azure SQL Database
- What's the difference between a temp table and table variable in SQL Server?
- SQL Server Temp Table vs Table Variable Performance Testing
- All SQL Server Performance Tuning Tips






About the author
 Aaron Bertrand (@AaronBertrand) is a passionate technologist with industry experience dating back to Classic ASP and SQL Server 6.5. He is editor-in-chief of the performance-related blog, SQLPerformance.com, and also blogs at sqlblog.org.
Aaron Bertrand (@AaronBertrand) is a passionate technologist with industry experience dating back to Classic ASP and SQL Server 6.5. He is editor-in-chief of the performance-related blog, SQLPerformance.com, and also blogs at sqlblog.org.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2018-09-06
