By: John Martin | Updated: 2018-10-02 | Comments (3) | Related: > Azure
Problem
Collating information from many different Azure SQL Server Databases can be done in several different ways. However, many of these require rearchitecting or building external services to connect to and then extract data from the databases and then trying to store it in a central repository. All of this can be a problem when trying to setup and manage a simple deployment scenario.
Solution
As well as having the ability to schedule and run tasks, Elastic Database Jobs also have a facility that allows them to collect data from a target database and easily store it in a central location. Here we will explore how we can collect data from user defined objects with Elastic Database Jobs.
Collecting Data for Elastic Database Jobs
Elastic Database job steps, as well as being able to run T-SQL on a schedule, can take the output of a query in the job step and pass the output to another database and store it in a table. To make use of this functionality we need to consider a few additional elements over a job step that simply executes activity on the target database. Primarily we need to have a target Azure SQL Database with results tables in place, as well as configuring Database Scoped Credentials that will be used to connect to the store and load the data we want to collect. In theory this could be the same Database Scoped Credential used to execute the job step. However, I would argue that from a security modularization perspective multiple credentials is a better option.
In the example below I am going to store maintenance information in the job database as this is a logical place for it to reside given the nature of Elastic Database Jobs.
Collecting Maintenance Data to the Job Database
Note: This task builds on my earlier post Index Maintenance in Azure SQL Database with Ola’s Scripts and Elastic Database Jobs. I would recommend reviewing this post to provide greater context to this section.
One of the great things about Ola Hallengren’s maintenance solution is that it is highly versatile and can log the executed commands to a table if you set the appropriate parameter. In my previous post I placed this table into the target database, now we will look to collect that data and store it centrally in our job database, so we have one location to view all our index maintenance operations.
Before we create the job step to collect the data, we need to perform the following actions;
- Create the results table that we are going to store data in
- Create a login on the Azure SQL Server
- Create a user for the login in our jobs database that will allow the job step to connect to the database and load the data
- Grant the user permissions on the table to load the data
- Create a Database Scoped Credential for the login/user so that we can pass this to the job step
Once all of these are in place we can then create our job step.
Create Results Table
There are two options available to us when it comes to storing the command log table data. One is to store the raw data in its native format. The other is to base the collection on the analysis script that Ola publishes for free, which extracts data from the command log for more detailed analysis.
Here I am going to pull the raw data back and store that, the reason being that we can then do subsequent analysis as needed and are not restricted to the subset of data we collect.
I will be creating a new schema to group all my objects together and provide more granular access so that I can have different types of user accessing the data or the job management system.
CREATE SCHEMA [Maintenance];
GO
While we could just take the definition of the command log table and create it here, I want to look at adding some additional information into it to help us identify which server and database the data came from.
Note: There is a need for an additional column “Internal_execution_id” which is part of the output from the job step that returns the data.
CREATE TABLE [Maintenance].[CentralCommandLog]
(
[internal_execution_id] [UNIQUEIDENTIFIER] NOT NULL, --// Additional column needed for data output in job step
[ID] [INT] NOT NULL,
[AzureSQLServer] [sysname] NOT NULL, --// Additional column for source server
[DatabaseName] [sysname] NULL,
[SchemaName] [sysname] NULL,
[ObjectName] [sysname] NULL,
[ObjectType] [CHAR](2) NULL,
[IndexName] [sysname] NULL,
[IndexType] [TINYINT] NULL,
[StatisticsName] [sysname] NULL,
[PartitionNumber] [INT] NULL,
[ExtendedInfo] [XML] NULL,
[Command] [NVARCHAR](MAX) NOT NULL,
[CommandType] [NVARCHAR](60) NOT NULL,
[StartTime] [DATETIME] NOT NULL,
[EndTime] [DATETIME] NULL,
[ErrorNumber] [INT] NULL,
[ErrorMessage] [NVARCHAR](MAX) NULL
);
GO
EXEC sys.sp_addextendedproperty @name = 'ReferenceSource', -- sysname
@value = 'Based on the work of Ola Hallengren, maintenance solution : https://ola.hallengren.com/', -- sql_variant
@level0type = 'SCHEMA', -- varchar(128)
@level0name = 'Maintenance', -- sysname
@level1type = 'TABLE', -- varchar(128)
@level1name = 'CentralCommandLog';
GO
Now we have the table which we are going to store our data in.
Setup Security for Loading Data
Before we can load the data, we need to define the security principals that will be used to connect to the database with. Here we will now create a login, user, and database scoped credential in the jobs database.
Create the Login in the Master database on the Azure SQL Server.
--// This needs to be executed in Master on the Azure SQL Server that hosts the Elastic Database Jobs database. CREATE LOGIN [LoadMaintData] WITH PASSWORD = N'Str0ngP@ssw0rd!'; GO
Now create the user and assign to database role. Presently the user needs to be a member of db_owner to allow the insert.
--// This needs to be executed in the context of the Elastic Database Jobs database. CREATE USER [LoadMaintData] FOR LOGIN [LoadMaintData]; GO ALTER ROLE db_owner ADD MEMBER LoadmaintData; GO
Now we can create the database scoped credential that will be supplied to the job step to insert the data into our central logging table.
--// This needs to be executed in the context of the Elastic Database Jobs database.
CREATE DATABASE SCOPED CREDENTIAL [LoadMaintData]
WITH
IDENTITY = 'LoadMaintData',
SECRET = ' Str0ngP@ssw0rd!';
GO
Now we are all set to go and collect our data.
Collector Job Step
Assumption: For this to work as-is, I am assuming that you will have read and setup the index maintenance routine as outlined in my earlier tip “Index Maintenance in Azure SQL Database with Ola’s Scripts and Elastic Database Jobs”
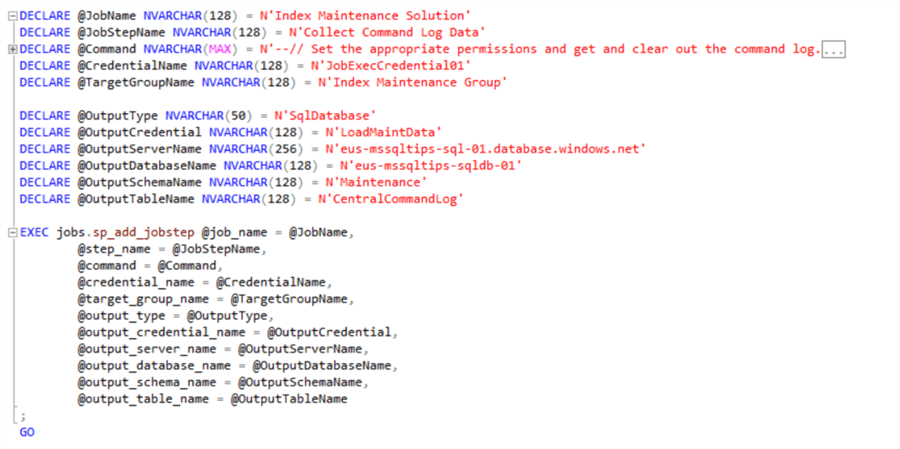
Here we are creating a job step that we will add to the index maintenance job, this will be the final step in the job. You can download the full script from here.
The key things to point out in the script here are the additional parameters needed to handle the collection of the data and its output to the database of our choice. Additionally, the code block will purge the data from the table once we have loaded it to a staging table before selecting it out as the final step. This will mean that we do not get duplicate data.
Note: If the for whatever reason the write to the target fails then the activities will not be rolled back in the job step command.
When the job runs it will collect the data from the dbo.CommandLog tables on each database that it executes on and then store it in the central repository that we have specified. Now that we have the data in one place we can start to analyze it effectively. Ola publishes a script that extracts more detailed information from the command log for the index operations. Because we have made some changes in the way that we are now storing the data we need to update the script a little to account for the new table name and columns.
I am going to create this as a view in the job database so that it is easy to query and perform further analysis on if needed with tools such as Power BI.
--// Script based on original work by Ola Hallengren - https://ola.hallengren.com
--// Original Script downloaded from https://ola.hallengren.com/scripts/misc/IndexCheck.sql
CREATE VIEW Maintenance.IndexFragmentationAnalysis
AS
SELECT AzureSQLServer,
DatabaseName,
SchemaName,
ObjectName,
CASE
WHEN ObjectType = 'U' THEN
'USER_TABLE'
WHEN ObjectType = 'V' THEN
'VIEW'
END AS ObjectType,
IndexName,
CASE
WHEN IndexType = 1 THEN
'CLUSTERED'
WHEN IndexType = 2 THEN
'NONCLUSTERED'
WHEN IndexType = 3 THEN
'XML'
WHEN IndexType = 4 THEN
'SPATIAL'
END AS IndexType,
PartitionNumber,
ExtendedInfo.value('(ExtendedInfo/PageCount)[1]', 'int') AS [PageCount],
ExtendedInfo.value('(ExtendedInfo/Fragmentation)[1]', 'float') AS Fragmentation,
CommandType,
StartTime,
CASE
WHEN DATEDIFF(ss, StartTime, EndTime) / (24 * 3600) > 0 THEN
CAST(DATEDIFF(ss, StartTime, EndTime) / (24 * 3600) AS NVARCHAR) + '.'
ELSE
''
END + RIGHT(CONVERT(NVARCHAR, EndTime - StartTime, 121), 12) AS Duration,
ErrorNumber,
ErrorMessage
FROM Maintenance.CentralCommandLog
WHERE CommandType = 'ALTER_INDEX';
GO
This will give us the output below when we query the view, showing the important details around fragmentation, size, and when the action took place.

Summary
Here we have shown how easy it can be to collect information from many Azure SQL Databases without the overhead of needing to setup and manage large numbers of external objects and Elastic Query. Pulling all the data into one central location reduces the footprint in the source databases as well as making it easy to see information for your whole Azure SQL Database estate for index management.
Next Steps
Review these related tips:
- Introduction to Azure Elastic Database Jobs
- Index Maintenance in Azure SQL Database with Ola’s Scripts and Elastic Database Jobs
- Adding Users to Azure SQL Databases
- How to use Azure SQL Database features and settings
- How to use the Azure SQL Database DTU Calculator
- Learn how to Migrate a SQL Server database to SQL Azure server
- Deploying Azure SQL Database Using Resource Manager PowerShell cmdlets
- SQL Azure Migration Wizard
- Guide to Getting Started with SQL Azure
- Long Term Storage for Azure SQL Database Backups
- SQL Azure Cross Database Querying






About the author
 John Martin is a Data Platform Engineer working in the financial sector as well as Director-at-Large for the PASS organisation and currently a Microsoft Data Platform MVP.
John Martin is a Data Platform Engineer working in the financial sector as well as Director-at-Large for the PASS organisation and currently a Microsoft Data Platform MVP.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2018-10-02
