By: Eduardo Pivaral | Updated: 2018-10-09 | Comments | Related: > Compression
Problem
You have one of several SQL Server tables occupying a lot of disk space, the data stored is mostly historical and/or logs from your application, the customer indicates you that you cannot purge the data, or store it outside the database, since every now and then users have to check old data, so data must be available to query. Since the data is rarely accessed, the performance is not critical for these old records, so you are looking for a compression solution for historical SQL Server tables.
Solution
Since SQL Server 2016 a compress/decompress solution was introduced for most string and binary data types, so you can compress data to save disk space and then decompress it when you need to access it.
In this tip I will show you how to implement compress and decompress process to your SQL Server database.
SQL Server COMPRESS and DECOMPRESS
The function used to compress the data is COMPRESS, it takes an expression and compresses it using a GZIP algorithm, it then returns a varbinary(max) datatype.
The basic usage is:
COMPRESS(expression)
To decompress a previously compressed value you must use the DECOMPRESS function, it returns a varbinary(max) datatype, so you must use cast or convert to return it to its original datatype.
The basic usage is:
DECOMPRESS(expression)
We will do an example on how to use it and we will see how much space we can save.
SQL Server COMPRESS and DECOMPRESS Example
We will create two tables, one that will store the data without compression and the other that will store the data with compression, we will just create a text field and the respective ID as follows:
CREATE TABLE [Uncompressed_Table]( [ID] [int] IDENTITY(1,1) NOT NULL, [Text_stored] [nvarchar](max) NOT NULL, CONSTRAINT [PK_Uncompressed_Table] PRIMARY KEY CLUSTERED ( [ID] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] ) ON [PRIMARY] TEXTIMAGE_ON [PRIMARY] GO ----------- CREATE TABLE [Compressed_Table]( [ID] [int] NOT NULL, [Text_stored] [varbinary](max) NOT NULL, CONSTRAINT [PK_Compressed_Table] PRIMARY KEY CLUSTERED ( [ID] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] ) ON [PRIMARY] TEXTIMAGE_ON [PRIMARY] GO
Then we proceed to fill the Uncompressed_Table with random data, we insert 60,000 records:
DECLARE @i int
SET @i =RAND()*500
INSERT INTO [Uncompressed_Table] VALUES(REPLICATE ('ABC' ,@i ))
INSERT INTO [Uncompressed_Table] VALUES(REPLICATE ('X' ,@i ))
INSERT INTO [Uncompressed_Table] VALUES(REPLICATE ('Y' ,@i ))
INSERT INTO [Uncompressed_Table] VALUES(REPLICATE ('Z' ,@i ))
INSERT INTO [Uncompressed_Table] VALUES(REPLICATE ('$' ,@i ))
INSERT INTO [Uncompressed_Table] VALUES(REPLICATE ('--' ,@i ))
GO 10000
We can see the space used by the table and the number of rows:

And the type of data we have stored in the table:

We will compress the data stored on the Text_stored column and store it on the compressed table, to see how much space we can save.
Compress SQL Server Data
Since the number of rows is quite small and we are on a development server, we proceed with a simple INSERT INTO statement and use the COMPRESS function as follows:
INSERT INTO [Compressed_Table] SELECT ID, COMPRESS([Text_stored]) FROM [Uncompressed_Table]
This inserts 60,000 rows.
NOTE: if you have a high number of rows or fields to compress, or you are working on a non-dev environment, I recommend implementing a batch solution as I explain in this tip, since the compress function over a large set of rows can lead to high CPU and IO usage.
Then we proceed to check the number of rows and the space used by the table with the compressed data:

The comparison is clear, the space saved by compressing the data is huge, as we only use around 6% of the original space. So, we have achieved the first of our objectives, we can save disk space now.
The only pending thing is to be able to query the data, because this is what it looks when we select the table as it is:
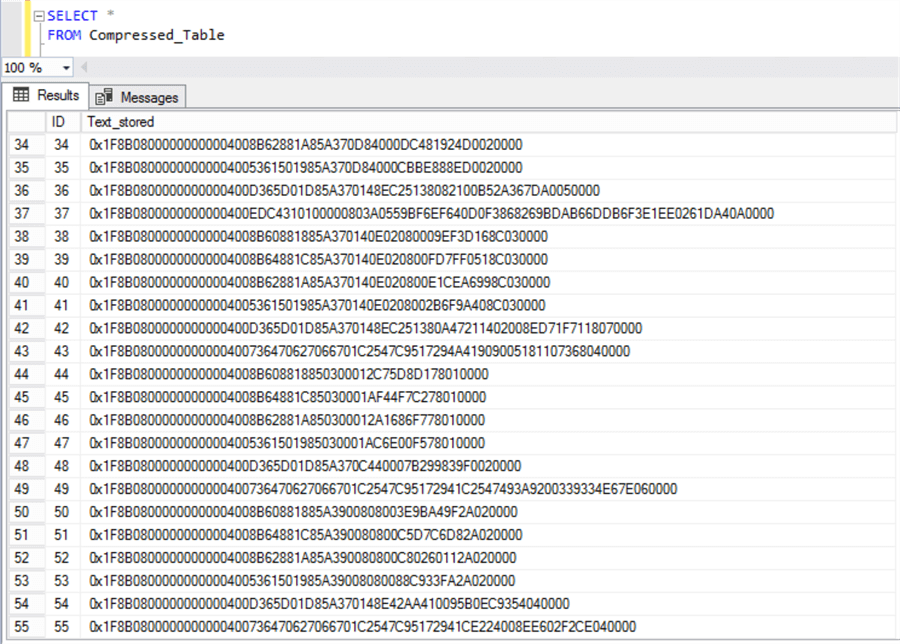
Right now, the data is stored in a compressed GZIP format, to be able to read it we need to decompress it first.
Decompress SQL Server Data
To be able to present the data to your application again, you must decompress it first using the DECOMPRESS function and then cast it to the original datatype.
For our example we will use the following code:
CAST(DECOMPRESS(Text_stored) as nvarchar(max))
And using it in our SELECT statement:
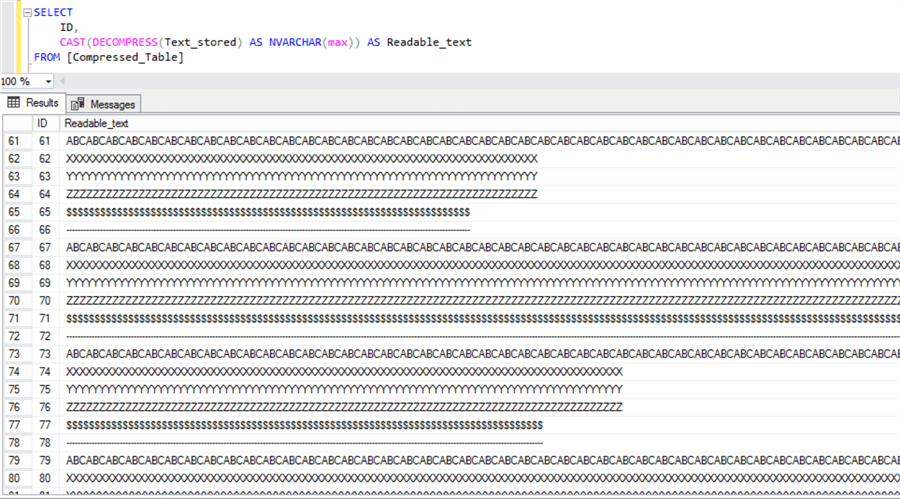
SELECT ID, CAST(DECOMPRESS(Text_stored) AS NVARCHAR(max)) AS Readable_text FROM [Compressed_Table]
And now the data is readable, so it can be use in our application:
Note: As with the INSERT statement, try to minimize as possible the number of rows to decompress, as it can lead to high CPU usage. You can check out this how to batch process SELECT statements in this tip.
We achieved both requirements, save disk space and be able to query the data using the compress and decompress functions.
Next Steps
- You can check the official COMPRESS documentation here.
- You can check the official DECOMPRESS documentation here.
- You can read more about the GZIP format here.
- Note that since the datatype returned is varbinary(max) you are not able to use compressed data on indexes as key columns (and it won’t make much sense since data is in another format). You can however, use it on indexes for INCLUDED columns, with the drawback that they must be built offline.
- This solution is best suited for data that is not frequently queried, as the use of the functions requires additional CPU overhead, always monitor and test performance on a development server first.






About the author
 Eduardo Pivaral is an MCSA, SQL Server Database Administrator and Developer with over 15 years experience working in large environments.
Eduardo Pivaral is an MCSA, SQL Server Database Administrator and Developer with over 15 years experience working in large environments. This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2018-10-09
