By: Ron L'Esteve | Updated: 2019-02-11 | Comments (5) | Related: > Azure
Problem
There are numerous Big Data processing technologies available on the market. This article will help with gaining confidence and familiarity with Microsoft Azure's Data Lake Analytics offering to process large datasets quickly, while demonstrating the potential and capabilities of U-SQL to aggregate and process big data files.
Solution
When it comes to learning any new language and technology, there is always a learning curve to assist with improving our skillsets and gaining confidence with new tools and technologies. This article describes how to get started with Azure Data Lake Analytics and write U-SQL queries to clean, aggregate and process multiple big data files quickly.
Creating an Azure Data Lake Analytics Account
To process data in Azure Data Lake Analytics, you'll need an Azure Data Lake Analytics account associated with an Azure Data Lake store.
- In a web browser, navigate to http://portal.azure.com, and if prompted, sign in using the Microsoft account that is associated with your Azure subscription.
- In the Microsoft Azure portal, in the Hub Menu, click New. Then navigate to Data Lake Analytics.
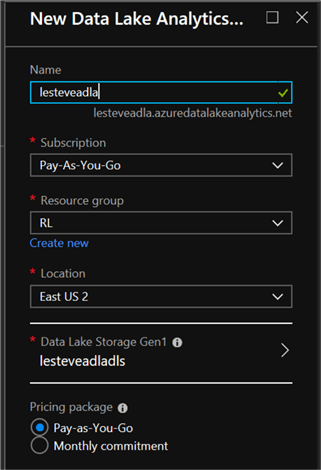
- In the New Data Lake Analytics Account blade, enter the following
settings, and then click Create.
- Name: Enter a unique name
- Subscription: Select your Azure subscription
- Resource Group: Create a new resource group
- Location: Select a resource
- Data Lake Store: Create a new Data Lake Store
Writing U-SQL Queries to Clean Data in Azure Data Lake
Now that we've created a Data Lake Analytics account, let's get started with writing U-SQL.
Azure Data Lake Analytics enables you to process data by writing U-SQL code which is like T-SQL, but also includes support for C# syntax and data types.
Example 1
To start, I'll go ahead and upload a file to my ADLS containing a list of products and their detail containing the following columns:
- ProductID
- Name
- ProductNumber
- Color
- StandardCost
- ListPrice
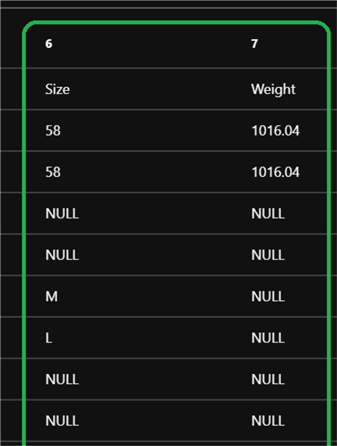
- Size
- Weight
When I click products.txt to preview the data, I'll notice that this file contains a tab-delimited list of products. I also notice that some of the product details contain the text "NULL" – this is used in the Size and Weight columns to indicate that there is no known value for this product.
Next, I'll return to the blade for my Azure Data Lake Store, and on the Overview page, click + New Job.
In the New U-SQL Job blade, I change the Job Name to Process Products.
In the query pane, I enter the following U-SQL code:
@products = EXTRACT ProductID string,
ProductName string,
ProductNumber string,
Color string,
StandardCost decimal,
ListPrice decimal,
Size string,
NetWeight string
FROM "/bigdata/products.txt"
USING Extractors.Tsv(skipFirstNRows:1);
@cleanProducts = SELECT ProductID,
ProductName,
ProductNumber,
(Color == "NULL") ? "None" : Color AS Color,
StandardCost,
ListPrice,
ListPrice - StandardCost AS Markup,
(Size == "NULL") ? "N/A" : Size AS Size,
(NetWeight == "NULL") ? "0.00" : NetWeight AS NetWeight
FROM @products;
OUTPUT @cleanProducts
TO "output/cleanproducts.csv"
ORDER BY ProductID
USING Outputters.Csv(outputHeader:true);
Note that code in the query does the following:
- Loads the tab-delimited data from the text file into a table variable with appropriate columns, skipping the first row (which contains the column names).
- Cleans the data by changing NULL Color values to "None", changing NULL Size values to "N/A", and changing NULL Weight values to 0.00.
- Calculates the markup for each product by subtracting the cost from the list price.
- Stores the cleaned data in a comma-delimited file.
I'll then click submit to run the Job. Once the job completes running successfully, I'll review the graph created which shows the steps used to execute the job.
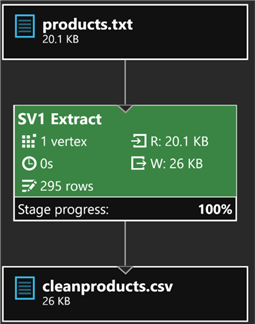
After that, I will navigate to my output folder where the cleansed file was created to see a preview of the results.
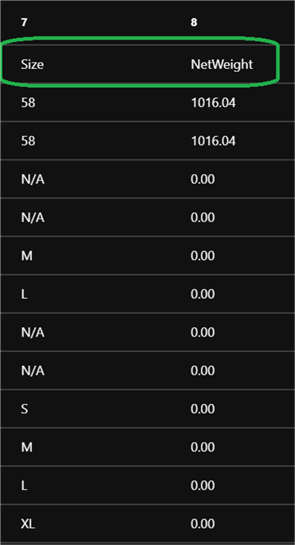
Sure enough, I notice that all the expected cleansing steps have been applied to my dataset.
Example 2
Using my same ADLA account I am going to upload process another file containing some sample log data.
When I review the contents of the file, I see that it contains some header rows that are prefixed with a # character along with some space-delimited web server request records.
Once again, I'll create a New Job to use a U-SQL query to read and process the data.
I'll start by entering the following query:
@log = EXTRACT entry string FROM "/bigdata/2008-01.txt" USING Extractors.Text(); OUTPUT @log TO "/output/log.txt" USING Outputters.Text();
This code will use the built-in Text extractor to read the contents of log file. The default field delimiter for the Text extractor is a comma, which the source data does not contain, so the code reads each line of text in the log file, and then uses the default Text outputter to write the data to an output file.
I can now add a SELECT statement to Filter the data and remove the comment rows.
My modified query will look like this, with the addition of a SELECT for @cleaned:
@log = EXTRACT entry string
FROM "/bigdata/2008-01.txt"
USING Extractors.Text();
@cleaned = SELECT entry
FROM @log
WHERE entry.Substring(0,1) != "#";
OUTPUT @cleaned
TO "/output/cleaned.txt"
USING Outputters.Text();
This query uses a SELECT statement to filter the data retrieved by the extractor and the WHERE clause in the SELECT statement uses the C# Substring function to filter out rows that start with a "#" character. The ability to blend C# and SQL is what makes U-SQL such a flexible and extensible language for data processing.
I'll click Submit Job and observe the job details as it is run. After the job has been prepared, a job graph should be displayed, showing the steps used to execute it.
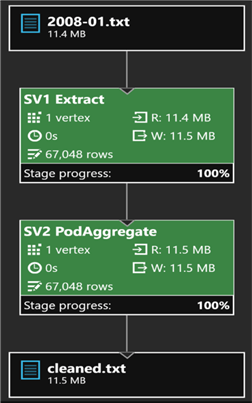
After the job completes successfully, I'll click the Output tab and select cleaned.txt to see a preview of the results, which no longer contains comment rows.
Note that the preview automatically displays the data as a table, detecting spaces as the delimiter. However, the output data is plain text.
Writing a U-SQL Query to Apply a Schema to the Data
Now that you have seen how to use U-SQL to read and filter text data based on rows of text, next I will apply a schema to the data, separating it into discrete fields that can be processed individually.
In my ADLA account, I'll click New U-SQL Job, give it an intuitive name such as 'Process Log Data' and then enter the following code:
@log = EXTRACT date string,
time string,
client_ip string,
username string,
server_ip string,
port int,
method string,
stem string,
query string,
status string,
server_bytes int,
client_bytes int,
time_taken int,
user_agent string,
referrer string
FROM "/bigdata/2008-01.txt"
USING Extractors.Text(' ', silent:true);
OUTPUT @log
TO "/output/log.csv"
USING Outputters.Csv();
This code uses the built-in Text extractor to read the contents of the log file based on a schema that defines multiple columns and their data types. The delimiter for the Text extractor is specified as a space, and the extractor is configured to silently drop any rows that do not match the schema.
The data is then written to the Azure Data Lake Store using the built-in Csv outputter. This is a specific implementation of the Text outputter that saves the data in comma-delimited format.
Writing a U-SQL Query to Aggregate the Data
Now that I've created a schema, I'll go ahead and begin aggregating and filtering my data.
The following code uses a SELECT statement with a GROUP BY clause to summarize the total log entries, server bytes, and client bytes by day.
The results are then written to the Azure Data Lake store using the built-in Csv outputter, with an ORDER BY clause that sorts the results into ascending order of date.
@log = EXTRACT date string,
time string,
client_ip string,
username string,
server_ip string,
port int,
method string,
stem string,
query string,
status string,
server_bytes int,
client_bytes int,
time_taken int,
user_agent string,
referrer string
FROM "/bigdata/2008-01.txt"
USING Extractors.Text(' ', silent:true);
@dailysummary = SELECT date,
COUNT(*) AS hits,
SUM(server_bytes) AS bytes_sent,
SUM(client_bytes) AS bytes_received
FROM @log
GROUP BY date;
OUTPUT @dailysummary
TO "/output/daily_summary.csv"
ORDER BY date
USING Outputters.Csv();
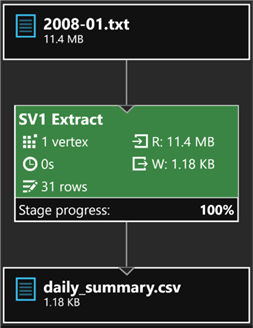
After the job is submitted and successfully completed, I'll click the Output tab and select daily_summary.csv to see a preview of the results.
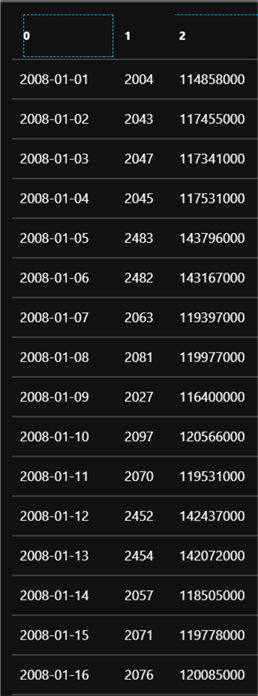
Sure enough, I can see that each row in the data contains a daily summary of hits, bytes sent, and bytes received.
Writing a U-SQL Query to Process Multiple Files
Now that I've done quite a bit of processing on a single file, I'll take things one step further by processing data in multiple files.
Thus far, I've been processing files for January. I will now upload log data for February to June to process multiple files.
Now I'll create a new ADLA job to process these multiple files by using a wildcard in my query to read data from all the files together.
In the New U-SQL Job blade, I'll type 'Summarize Logs' and enter the following script in the code window:
@log = EXTRACT date string,
time string,
client_ip string,
username string,
server_ip string,
port int,
method string,
stem string,
query string,
status string,
server_bytes int,
client_bytes int,
time_taken int,
user_agent string,
referrer string
FROM "/bigdata/{*}.txt"
USING Extractors.Text(' ', silent:true);
@dailysummary = SELECT date,
COUNT(*) AS hits,
SUM(server_bytes) AS bytes_sent,
SUM(client_bytes) AS bytes_received
FROM @log
GROUP BY date;
OUTPUT @dailysummary
TO "/output/six_month_summary.csv"
ORDER BY date
USING Outputters.Csv();
Notice how the code uses the wildcard placeholder {*} to read all files with a .txt extension from the specified folder.
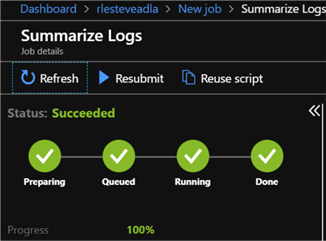
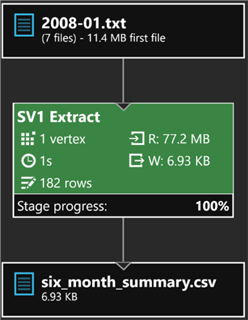
After the job is submitted and successfully completed, I'll click the Output tab and select six_month_summary.csv to see a preview of the results.
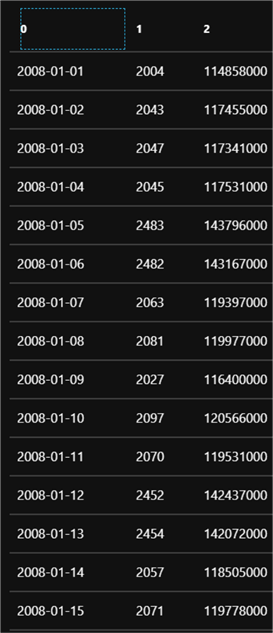
As expected, I can see that each row in the data contains a daily summary of hits, bytes sent, and bytes received for January through June.
Next Steps
- In this article, we learned how to process data stored in Azure Data Lake Store using Azure Data Lake Analytics by writing U-SQL Queries.
- Be sure to check out my article on Writing Federated U-SQL Queries to Join Azure Data Lake Store Files to Azure SQL DB, which demonstrates how to use Azure Data Lake Analytics to query data from Azure SQL DB
- Stay tuned for my additional upcoming tips related to Monitoring U-SQL Jobs, U-SQL Catalogs and Using C# in U-SQL.






About the author
 Ron L'Esteve is a trusted information technology thought leader and professional Author residing in Illinois. He brings over 20 years of IT experience and is well-known for his impactful books and article publications on Data & AI Architecture, Engineering, and Cloud Leadership. Ron completed his Master�s in Business Administration and Finance from Loyola University in Chicago. Ron brings deep tec
Ron L'Esteve is a trusted information technology thought leader and professional Author residing in Illinois. He brings over 20 years of IT experience and is well-known for his impactful books and article publications on Data & AI Architecture, Engineering, and Cloud Leadership. Ron completed his Master�s in Business Administration and Finance from Loyola University in Chicago. Ron brings deep tecThis author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2019-02-11
